
|
Métodos Estatísticos em Pesquisa Científica
Análise do Questionário 2020
# Pacotes necessários
library(splitstackshape, quietly = TRUE)
library(scales)
library(psych)
library(lubridate)
library(pander)
library(DT)
library(plyr)
library(ggplot2)
# Leitura dos dados
#path <- "./resp_teste.csv"
path <- "quest/resp_mpec2020 - Respostas ao formulário 1.csv"
quest <- read.csv(path, sep = ',', encoding = 'UTF-8')
#quest <- read.csv(path, sep = ',', encoding = 'latin1')
# Excluindo a primeira coluna referente aos carimbos de data e hora do google forms
quest <- quest[,-1]
# Classificacao das variaves
# lo/ln - var qualitativa ordinal, nominal
# td - var quantitativa discreta
# Renomeando as colunas
names(quest) <-
c(
# questoes academicas
"ln_instituicao", "ln_setorAtuacao", "lo_ativAtuacao",
"ln_setorArea", "tc_anoFimGrad", "ln_localGrad",
"ln_progGrad", "tc_inicMest", "tc_fimMest",
"ln_localMest", "td_artigo", "ln_bolsaEstudo",
"td_estatGrad", "td_estatPGrad", "lo_soft",
"ln_enumSoft", "lo_importancia", "td_notaImport",
"ln_expectAposPG", "ln_conhecTransv", "lo_videoTransv",
"ln_turma", "lo_contatoProfDisc", "lo_contatoProfColabDisc",
"ln_medio1", "ln_medio2",
# perfil do aluno
"ln_sexo", "tc_altura", "tc_peso",
"dataNasc", "ln_tipoTrab", "ln_compMoradia",
"td_numIrmao", "ln_origem", "ln_tipoHab",
"ln_tipoTransp", "tc_tempoPUniv", "td_qtddServTransp",
"ln_pet", "ln_instr","ln_rede",
#questoes extra
"tc_idadeProf", "ln_kiki"
)
paleta <- c('#F78181', #vermelho
'#21610B', #verde escuro
'#A9F5F2', #azul
'#81F781', #verde
'#2E9AFE', #azul2
'#F781F3', #rosa
'#610B21', #vermelho escuro
'#F3F781', #amarelo
'#08088A', #azul escuro
'#086A87', #azul3
'#58FA82', #laranja
'#21610B' #verde escuro
)
path2 <- "quest/resp_2019.csv"
antigo <- read.csv(path2, sep = ',', encoding = 'UTF-8')
antigo <- data.frame(antigo[,-1], stringsAsFactors = FALSE)
names(antigo) <- c("lo_ativAtuacao", "ln_setorAtuacao",
"tc_anoFimGrad", "ln_localGrad",
"ln_progGrad", "tc_inicMest", "tc_fimMest",
"ln_localMest", "td_artigo", "ln_bolsaEstudo",
"td_estatGrad", "td_estatPGrad", "lo_soft",
"ln_enumSoft", "lo_importancia", "td_notaImport",
"ln_tipoTrab", "ln_sexo", "td_numIrmao",
"ln_origem", "ln_compMoradia", "ln_tipoTransp",
"ln_tipoHab", "tc_tempoPUniv", "tc_altura",
"tc_peso", "ln_pet", "ln_instr", "dataNasc",
"ln_rede", "td_qtddServTransp", "lo_provNetflix",
"ln_arrozNatal", "tc_idadeProf", "ln_expectAposPG",
"ln_conhecTransv", "lo_videoTransv",
"lo_contatoProfDisc", "lo_contatoProfColabDisc")Na primeira aula da disciplina de Métodos Estatísticos em Pesquisa Científica um questionário é repassado aos alunos via formulário do Google.
A ideia é coletar informações a respeito dos participantes da disciplina e realizar uma análise dos dados obtidos de forma a varrer uma boa parte do conteúdo referente à análise exploratória.
Após a realização do questionário os dados foram exportados em formato csv e importados no software R para que uma análise das informações coletada fosse feita.
O material desenvolvido para a oferta 2020 segue em grande parte o molde do que foi feito em outras ofertas.
As duas diferenças de maior impacto das versões anteriores foram com relação ao template do output e organização (tanto das questões no questionário, quanto na apresentação dos resultados).
Para este ano fizemos uma tentativa de organizar as questões do questionário em grupos maiores, desta forma, nesta versão existem:
- Questões acadêmicas.
- Questões pessoais.
- Questões extra.
Quando possível foi acrescentada uma aba com o resultado da análise da questão no ano anterior.
Nas análises das primeiras questões há mais material pois buscou-se explorar um número maior de opções de representação com o objetivo de alimentar a discussão.
Após as análises univariadas exploramos algumas representações bivariadas e, por fim, o correlograma.
Contribuíram para este material:
- Versão 1 - Hektor Dannyel Vieira Brasil.
- Versão 2 - Kally Chung.
- Versão 3 - Lineu Alberto Cavazani de Freitas.
Todas as versões foram desenvolvidas sob a orientação do professor Paulo Justiniano Ribeiro Junior.
Dados
Visando uma análise mais eficiente, foi feita uma série de tratamentos nos dados brutos. Vejamos as primeiras linhas dos dados:
Análise exploratória
Existem dois tipos de variáveis: as numéricas (quantitativas) e as não numéricas (qualitativas), cada uma das classes tem suas ramificações:
Variáveis Quantitativas: assumem valores numéricos.
Podem ser:
Discretas: características mensuráveis que podem assumir apenas um número finito ou infinito contável de valores e, assim, somente fazem sentido valores inteiros.
Contínuas: características mensuráveis que assumem valores em uma escala contínua, isto é, na reta real.
Variáveis Qualitativas: são as características definidas categorias, ou seja, representam uma classificação dos indivíduos e não uma característica numérica.
Podem ser:
Nominais: não existe ordenação nem peso entre as categorias.
Ordinais: existe uma ordenação entre as categorias.
Podemos sintetizar a informação presente nos dados por meio de tabelas de frequência e gráficos.
Cuidados devem ser tomados no que diz respeito à escolha do tipo de gráfico para representar a variável com o intuito de evitar que o gráfico fique desproporcional ou privilegiando determinados valores a fim de induzir conclusões àqueles que utilizam o gráfico como forma de visualização.
A escolha do gráfico está diretamente ligada ao tipo das variáveis. Além disso, existem gráficos que permitem análises de mais de uma variável simultâneamente a fim de verificar como uma influencia a outra(s).
Algumas possibilidades de gráficos para cada tipo de variável são:
Qualitativa nominal ou ordinal: setores, barras.
Quantitativa discreta: barras, histograma, boxplot.
Quantitativas contínuas: histograma ou boxplot.
- Análises bivariadas:
- Quantivativa vs Quantitativa: Diagrama de dispersão.
- Qualitativa vs Quantitativa: Boxplots.
- Qualitativa vs Qualitativa: Gráfico de mosaico.
Análise univariada
Vamos analisar, uma a uma, as questões do questionário.
Questões acadêmicas
A qual instituição você está filiado hoje?
Tabela 1
quest$ln_instituicao <- tolower(iconv(quest$ln_instituicao,
to ='ASCII//TRANSLIT', from = "UTF-8"))
classOpcoes <- tolower(c("UFPR",'UEL', 'UEM', 'UEPG', "UNIOESTE",
"UNICENTRO", "UENP", "UNILA",
"IFPR", "UTFPR"))
quest$ln_instituicao[ !quest$ln_instituicao %in% classOpcoes ] <- "outro"
quest$ln_instituicao <- factor(quest$ln_instituicao,
levels = tolower(c("UFPR",
'UEL', 'UEM', 'UEPG',
"UNIOESTE",
"UNICENTRO", "UENP",
"UNILA", "IFPR",
"UTFPR",
"OUTRO")))
fa_inst <- table(quest$ln_instituicao) # frequência absoluta
fr_inst <- prop.table(fa_inst) # frequência relativa
fac_inst <- cumsum(fr_inst) # frequência acumulada
inst <- data.frame(niveis = names(fa_inst),
freq = as.vector(fa_inst),
freq_r = as.vector(fr_inst),
freq_ac = as.vector(fac_inst)) # unindo as informações
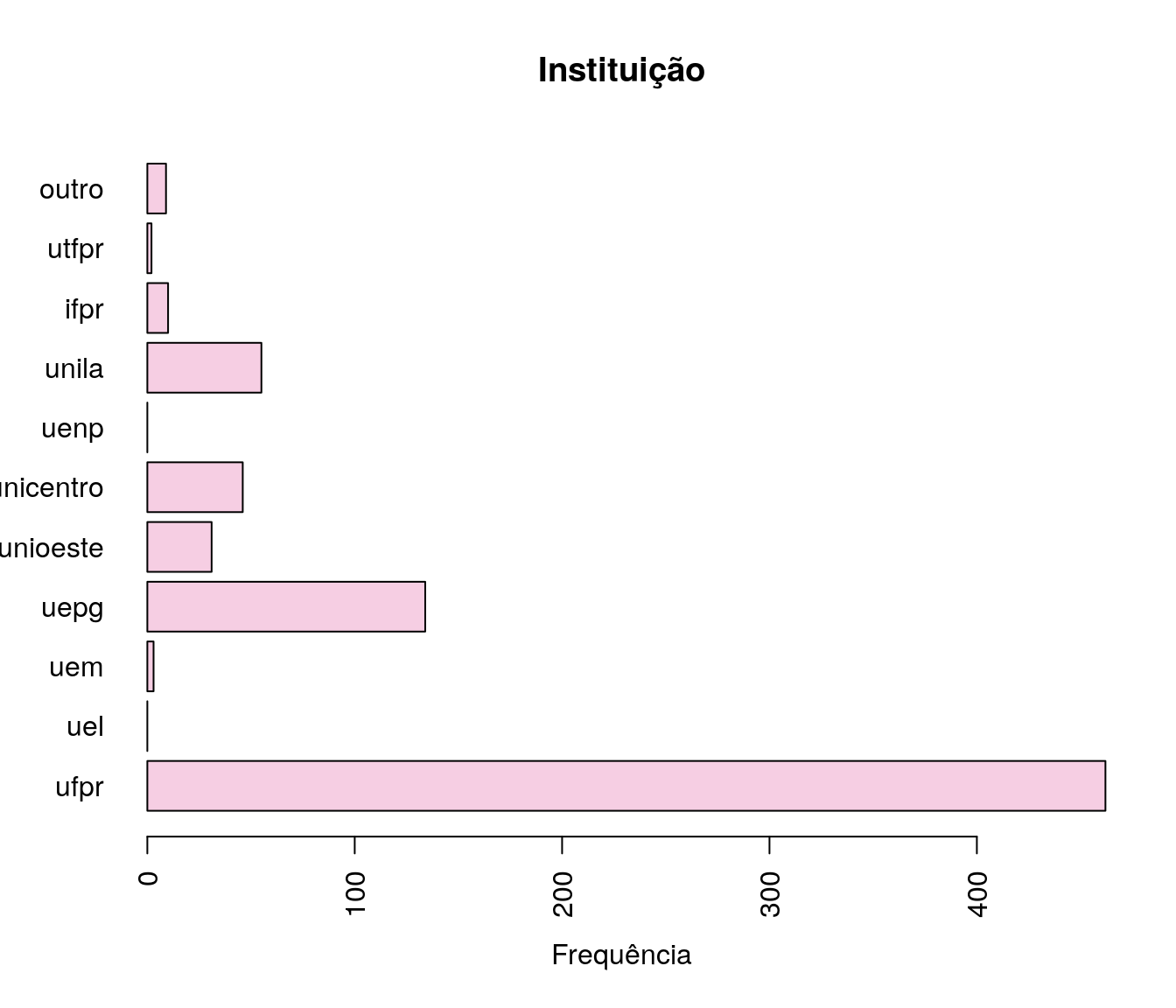
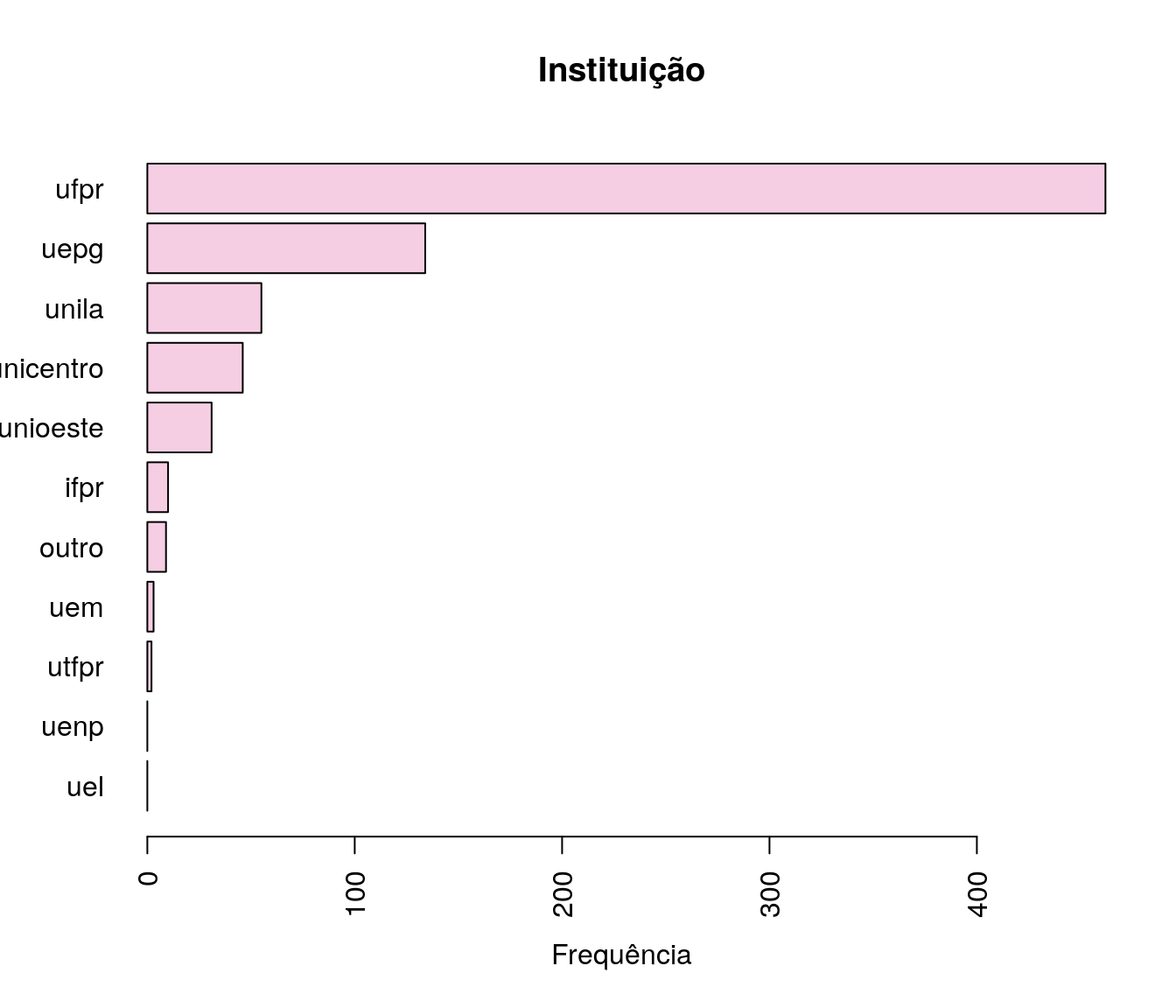
pander:::pander(inst) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| ufpr | 462 | 0.6144 | 0.6144 |
| uel | 0 | 0 | 0.6144 |
| uem | 3 | 0.003989 | 0.6184 |
| uepg | 134 | 0.1782 | 0.7965 |
| unioeste | 31 | 0.04122 | 0.8378 |
| unicentro | 46 | 0.06117 | 0.8989 |
| uenp | 0 | 0 | 0.8989 |
| unila | 55 | 0.07314 | 0.9721 |
| ifpr | 10 | 0.0133 | 0.9854 |
| utfpr | 2 | 0.00266 | 0.988 |
| outro | 9 | 0.01197 | 1 |
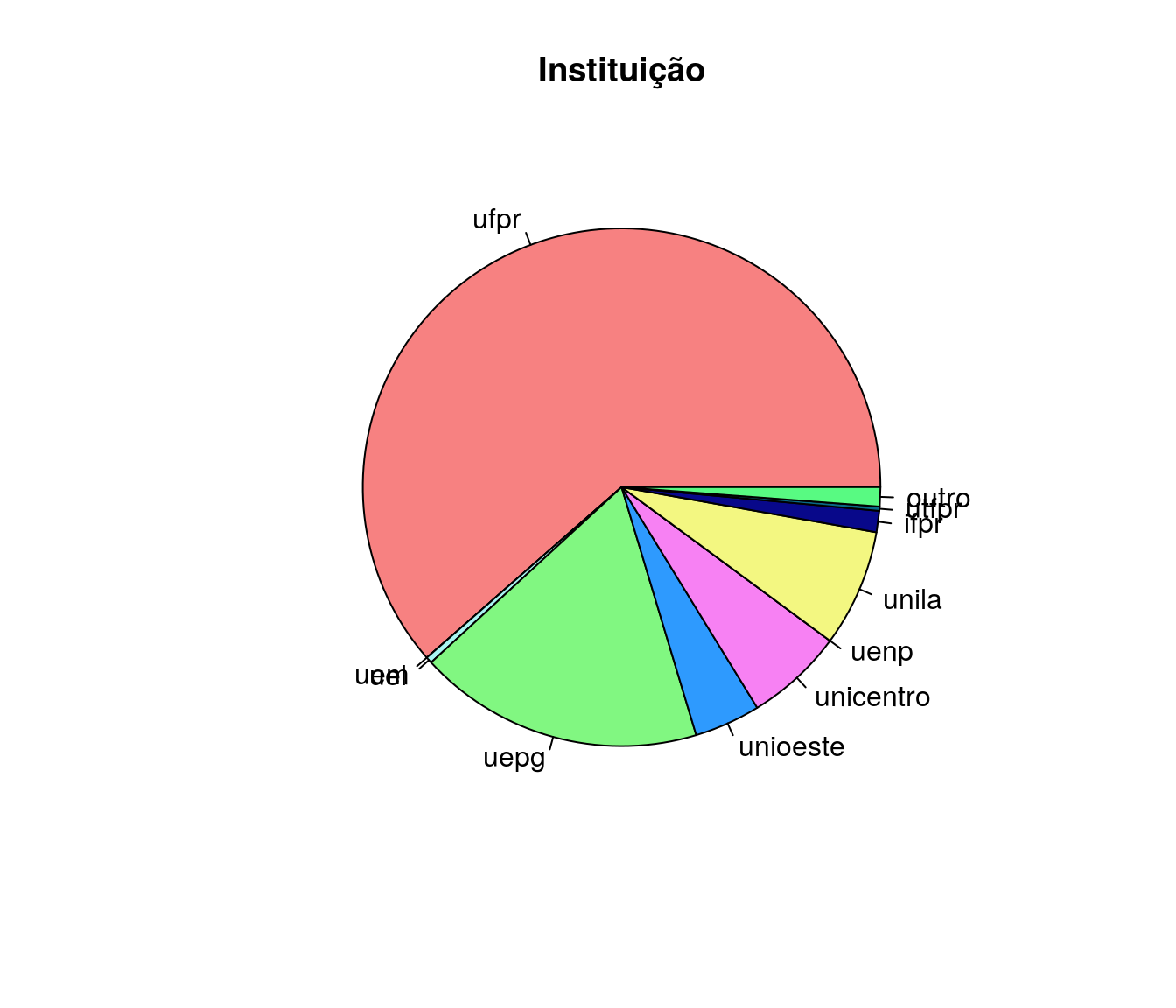
Gráfico 2
pie(inst$freq, col = paleta,
main = 'Instituição',
labels = percent(inst$freq_r))
legend("topleft", legend = inst$niveis, fill = paleta, cex = .8)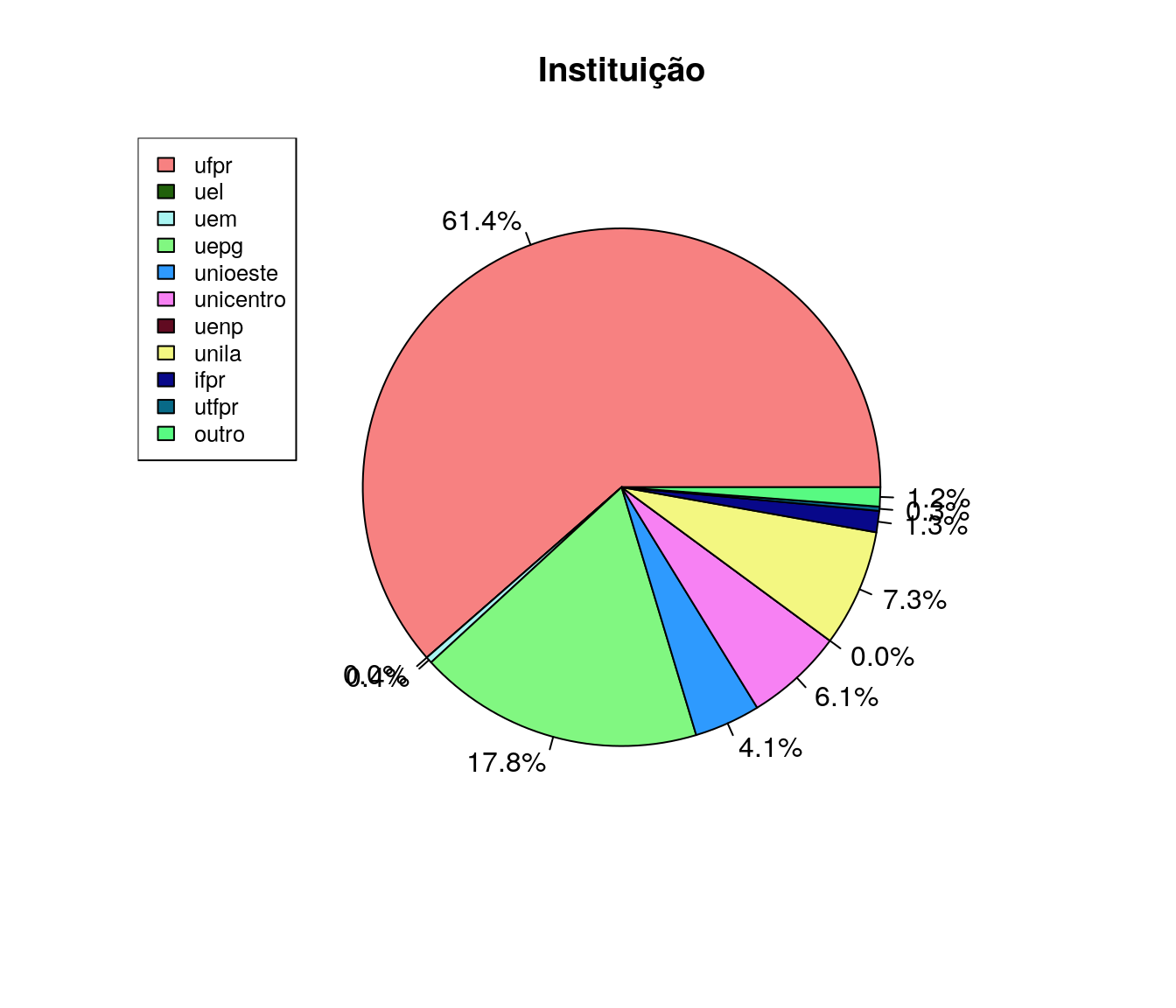
Se você estuda na UFPR, em qual setor você está inserido?
Tabela 1
Sem subset de alunos da UFPR
quest$ln_setorAtuacao <- tolower(iconv(quest$ln_setorAtuacao,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$ln_setorAtuacao <- factor(quest$ln_setorAtuacao,
levels = c("ac - artes, comunicacao e design",
"ag - agrarias",
"bl - ciencias biologiccas",
"ch - humanas",
"ct - ciencias da terra",
"ed - educacao",
"ep - educacao profissional e tecnologica",
"et - exatas",
"jd - juridicas",
"sa - sociais aplicadas",
"sd - saude",
"sl - litoral",
"sp - palotina",
"tc - tecnologia"))
tb.setorAtuacao <- as.data.frame(with(quest, table(ln_setorAtuacao)))
tb.setorAtuacao$Perc <- 100 * prop.table(tb.setorAtuacao$Freq)
names(tb.setorAtuacao)[1] <- "Setor de Atuação"
pander:::pander(tb.setorAtuacao)| Setor de Atuação | Freq | Perc |
|---|---|---|
| ac - artes, comunicacao e design | 2 | 0.4065 |
| ag - agrarias | 101 | 20.53 |
| bl - ciencias biologiccas | 58 | 11.79 |
| ch - humanas | 25 | 5.081 |
| ct - ciencias da terra | 21 | 4.268 |
| ed - educacao | 14 | 2.846 |
| ep - educacao profissional e tecnologica | 1 | 0.2033 |
| et - exatas | 34 | 6.911 |
| jd - juridicas | 0 | 0 |
| sa - sociais aplicadas | 35 | 7.114 |
| sd - saude | 121 | 24.59 |
| sl - litoral | 4 | 0.813 |
| sp - palotina | 31 | 6.301 |
| tc - tecnologia | 45 | 9.146 |
Tabela 2
Subset de alunos UFPR
quest$ln_setorAtuacao <- tolower(iconv(quest$ln_setorAtuacao,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$ln_setorAtuacao <- factor(quest$ln_setorAtuacao,
levels = c("ac - artes, comunicacao e design",
"ag - agrarias",
"bl - ciencias biologiccas",
"ch - humanas",
"ct - ciencias da terra",
"ed - educacao",
"ep - educacao profissional e tecnologica",
"et - exatas",
"jd - juridicas",
"sa - sociais aplicadas",
"sd - saude",
"sl - litoral",
"sp - palotina",
"tc - tecnologia"))
quest_ufpr <- subset(quest, ln_instituicao == 'ufpr')
tb.setorAtuacao <- as.data.frame(with(quest_ufpr, table(ln_setorAtuacao)))
tb.setorAtuacao$Perc <- 100 * prop.table(tb.setorAtuacao$Freq)
names(tb.setorAtuacao)[1] <- "Setor de Atuação"
pander:::pander(tb.setorAtuacao)| Setor de Atuação | Freq | Perc |
|---|---|---|
| ac - artes, comunicacao e design | 2 | 0.4396 |
| ag - agrarias | 94 | 20.66 |
| bl - ciencias biologiccas | 55 | 12.09 |
| ch - humanas | 23 | 5.055 |
| ct - ciencias da terra | 18 | 3.956 |
| ed - educacao | 13 | 2.857 |
| ep - educacao profissional e tecnologica | 1 | 0.2198 |
| et - exatas | 31 | 6.813 |
| jd - juridicas | 0 | 0 |
| sa - sociais aplicadas | 32 | 7.033 |
| sd - saude | 107 | 23.52 |
| sl - litoral | 4 | 0.8791 |
| sp - palotina | 30 | 6.593 |
| tc - tecnologia | 45 | 9.89 |
Gráfico
setor <- tb.setorAtuacao
setor$`Setor de Atuação` <- c("AC", "AG", "BL", "CH",
"CT", "ED", "EP", "ET",
"JD", "SA", "SD", "SL",
"SP", "TC")
setor <- arrange(setor, setor$Freq)
barplot(setor$Freq, col = '#A9F5D0',
names.arg = setor$`Setor de Atuação`, horiz = T,
xlim = c(0, max(setor$Freq + 30)),
main = "Setor de atividade na UFPR",
las = 2)
text(y = as.vector(barplot(setor$Freq, plot = FALSE)),
x = as.vector(setor$Freq) + 2,
labels = setor$Freq, cex = .8)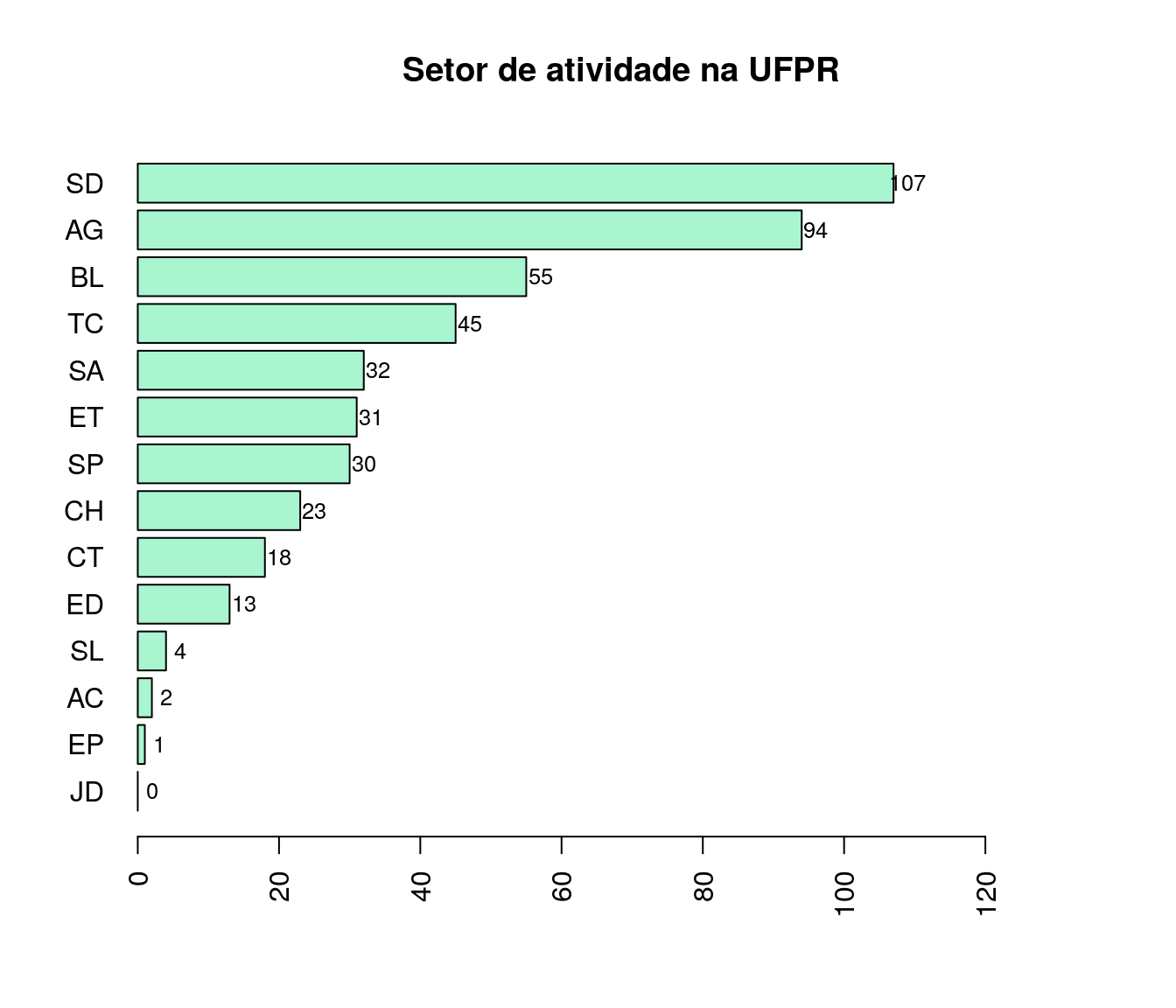
2019
antigo$ln_setorAtuacao <- tolower(iconv(antigo$ln_setorAtuacao,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
antigo$ln_setorAtuacao <- factor(antigo$ln_setorAtuacao,
levels = c("ac - artes, comunicacao e design",
"ag - agrarias",
"bl - ciencias biologicas",
"ch - humanas",
"ct - ciencias da terra",
"ed - educacao",
"ep - educacao profissional e tecnologica",
"et - exatas",
"jd - juridicas",
"sa - sociais aplicadas",
"sd - saude",
"sl - litoral",
"sp - palotina",
"tc - tecnologia"))
tb.setorAtuacao <- as.data.frame(with(antigo, table(ln_setorAtuacao)))
tb.setorAtuacao$Perc <- 100 * prop.table(tb.setorAtuacao$Freq)
names(tb.setorAtuacao)[1] <- "Setor de Atuação"
#pander:::pander(tb.setorAtuacao)
setor <- tb.setorAtuacao
setor$`Setor de Atuação` <- c("AC", "AG", "BL", "CH",
"CT", "ED", "EP", "ET",
"JD", "SA", "SD", "SL",
"SP", "TC")
setor <- arrange(setor, setor$Freq)
barplot(setor$Freq, col = '#A9F5D0',
names.arg = setor$`Setor de Atuação`, horiz = T,
xlim = c(0, max(setor$Freq + 30)),
main = "Setor de atividade na UFPR",
las = 2)
text(y = as.vector(barplot(setor$Freq, plot = FALSE)),
x = as.vector(setor$Freq) + 2,
labels = setor$Freq, cex = .8)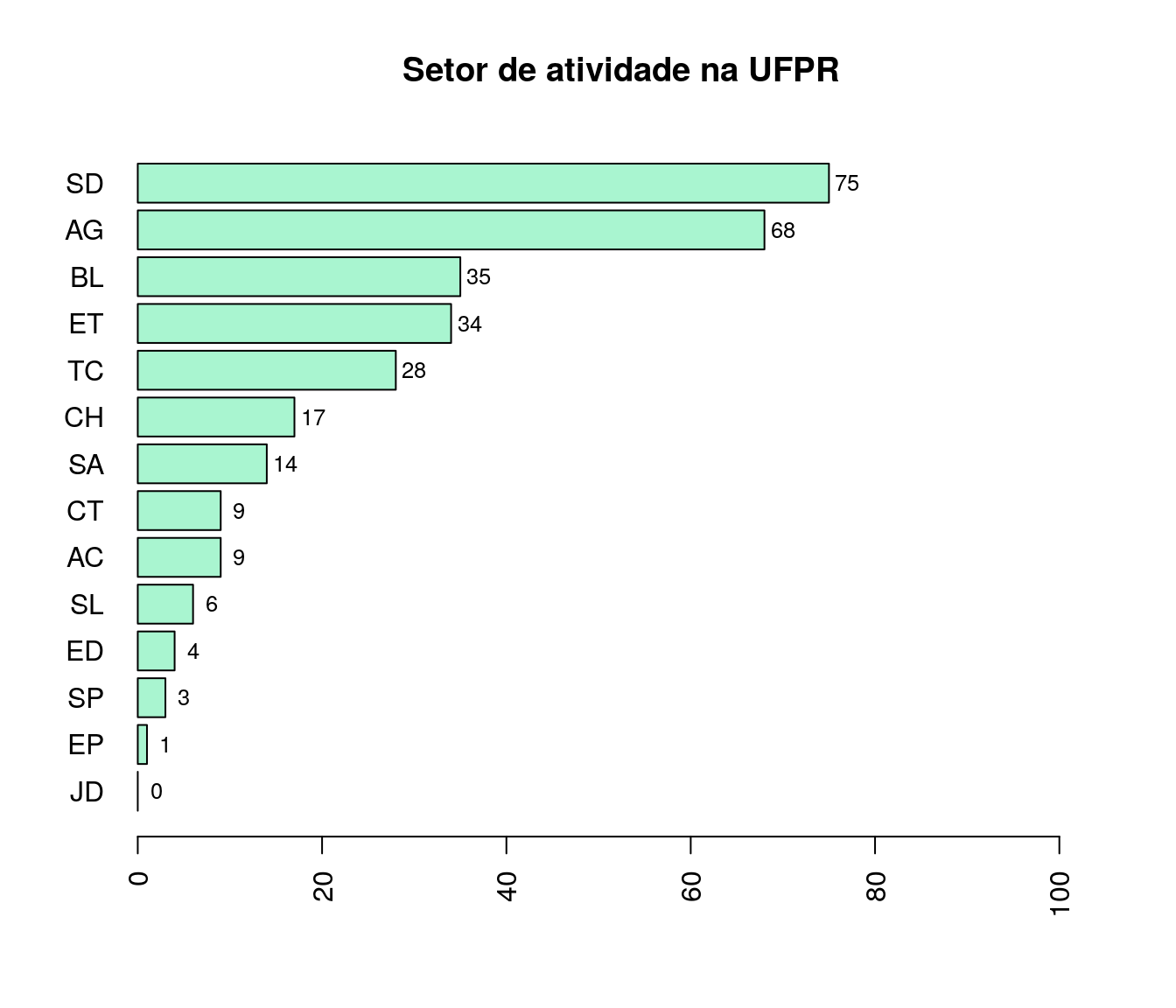
Comparativo 1
# 2020
quest$ln_setorAtuacao <- tolower(iconv(quest$ln_setorAtuacao,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$ln_setorAtuacao <- factor(quest$ln_setorAtuacao,
levels = c("ac - artes, comunicacao e design",
"ag - agrarias",
"bl - ciencias biologiccas",
"ch - humanas",
"ct - ciencias da terra",
"ed - educacao",
"ep - educacao profissional e tecnologica",
"et - exatas",
"jd - juridicas",
"sa - sociais aplicadas",
"sd - saude",
"sl - litoral",
"sp - palotina",
"tc - tecnologia"))
quest_ufpr <- subset(quest, ln_instituicao == 'ufpr')
fa_at <- table(quest_ufpr$ln_setorAtuacao) # frequência absoluta
fr_at <- prop.table(fa_at) # frequência relativa
#fac_at <- cumsum(fr_at) # frequência acumulada
at <- data.frame(niveis = names(fa_at),
#freq = as.vector(fa_at),
freq_r = as.vector(fr_at),
ano = rep(2020, length(fr_at)))
# 2019
antigo$ln_setorAtuacao <- tolower(iconv(antigo$ln_setorAtuacao,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
antigo$ln_setorAtuacao <- factor(antigo$ln_setorAtuacao,
levels = c("ac - artes, comunicacao e design",
"ag - agrarias",
"bl - ciencias biologiccas",
"ch - humanas",
"ct - ciencias da terra",
"ed - educacao",
"ep - educacao profissional e tecnologica",
"et - exatas",
"jd - juridicas",
"sa - sociais aplicadas",
"sd - saude",
"sl - litoral",
"sp - palotina",
"tc - tecnologia"))
fa_at <- table(antigo$ln_setorAtuacao) # frequência absoluta
fr_at <- prop.table(fa_at) # frequência relativa
#fac_at <- cumsum(fr_at) # frequência acumulada
at2 <- data.frame(niveis = names(fa_at),
#freq = as.vector(fa_at),
freq_r = as.vector(fr_at),
ano = rep(2019, length(fr_at)))
##
at[15:28,] <- at2
at$freq_r <- round(at$freq_r, 2)
at$ano <- as.factor(at$ano)
at <- arrange(at, niveis)
ggplot(at,
aes(x=niveis, y=freq_r, fill=ano)) +
geom_bar(stat="identity", alpha = 0.8, col = 1) +
xlab("") + ylab("Frequência relativa") + theme_classic()+
coord_flip() + ggtitle("Comparativo das Turmas")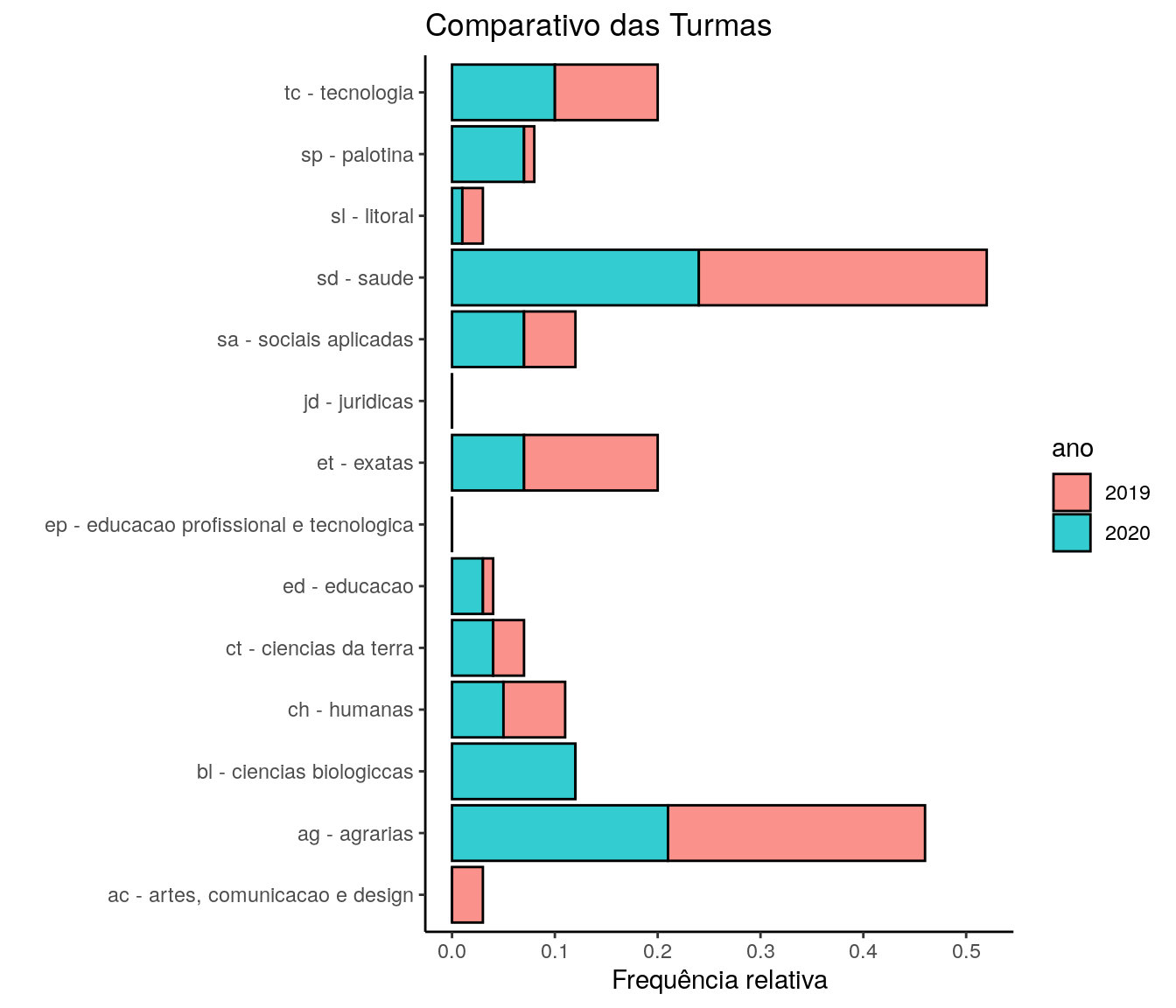
Qual sua atividade atual na sua universidade (relacionada à presença nesta disciplina)?
Tabela 1
quest$lo_ativAtuacao <- tolower(iconv(quest$lo_ativAtuacao,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
fa_at <- table(quest$lo_ativAtuacao) # frequência absoluta
fr_at <- prop.table(fa_at) # frequência relativa
fac_at <- cumsum(fr_at) # frequência acumulada
at <- data.frame(niveis = names(fa_at),
freq = as.vector(fa_at),
freq_r = as.vector(fr_at),
freq_ac = as.vector(fac_at))
pander:::pander(at)| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| aluna externa no mestrado. | 1 | 0.00133 | 0.00133 |
| doutorado | 332 | 0.4415 | 0.4428 |
| mestrado academico | 376 | 0.5 | 0.9428 |
| mestrado profissional | 26 | 0.03457 | 0.9774 |
| professor | 17 | 0.02261 | 1 |
Tabela 2
quest$lo_ativAtuacao <- tolower(iconv(quest$lo_ativAtuacao,
to ='ASCII//TRANSLIT', from = "UTF-8"))
classOpcoes <- c("mestrado academico", "professor", "doutorado",
"mestrado profissional", "pos-doutorado")
quest$lo_ativAtuacao[ !quest$lo_ativAtuacao %in% classOpcoes ] <- "outro"
quest$lo_ativAtuacao <- factor(quest$lo_ativAtuacao,
levels = c("mestrado profissional",
"mestrado academico",
"doutorado",
"pos-doutorado", "professor", "outro"))
fa_at <- table(quest$lo_ativAtuacao) # frequência absoluta
fr_at <- prop.table(fa_at) # frequência relativa
fac_at <- cumsum(fr_at) # frequência acumulada
at <- data.frame(niveis = names(fa_at),
freq = as.vector(fa_at),
freq_r = as.vector(fr_at),
freq_ac = as.vector(fac_at))
pander:::pander(at)| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| mestrado profissional | 26 | 0.03457 | 0.03457 |
| mestrado academico | 376 | 0.5 | 0.5346 |
| doutorado | 332 | 0.4415 | 0.9761 |
| pos-doutorado | 0 | 0 | 0.9761 |
| professor | 17 | 0.02261 | 0.9987 |
| outro | 1 | 0.00133 | 1 |
Gráfico
at_ord <- arrange(at, at$freq)
barplot(at_ord$freq,
#names.arg = at_ord$niveis,
col = paleta,
main = 'Atual atividade ',
ylab = 'Frequência',
xlab = '',
ylim = c(0, max(at_ord$freq)+30)
#horiz = T,
#las=2,
)
legend("topleft",
legend = at_ord$niveis,
fill = paleta,
cex = .8)
text(x = as.vector(barplot(at_ord$freq, plot = FALSE)),
y = as.vector(at_ord$freq) + 10,
labels = at_ord$freq, cex = .8)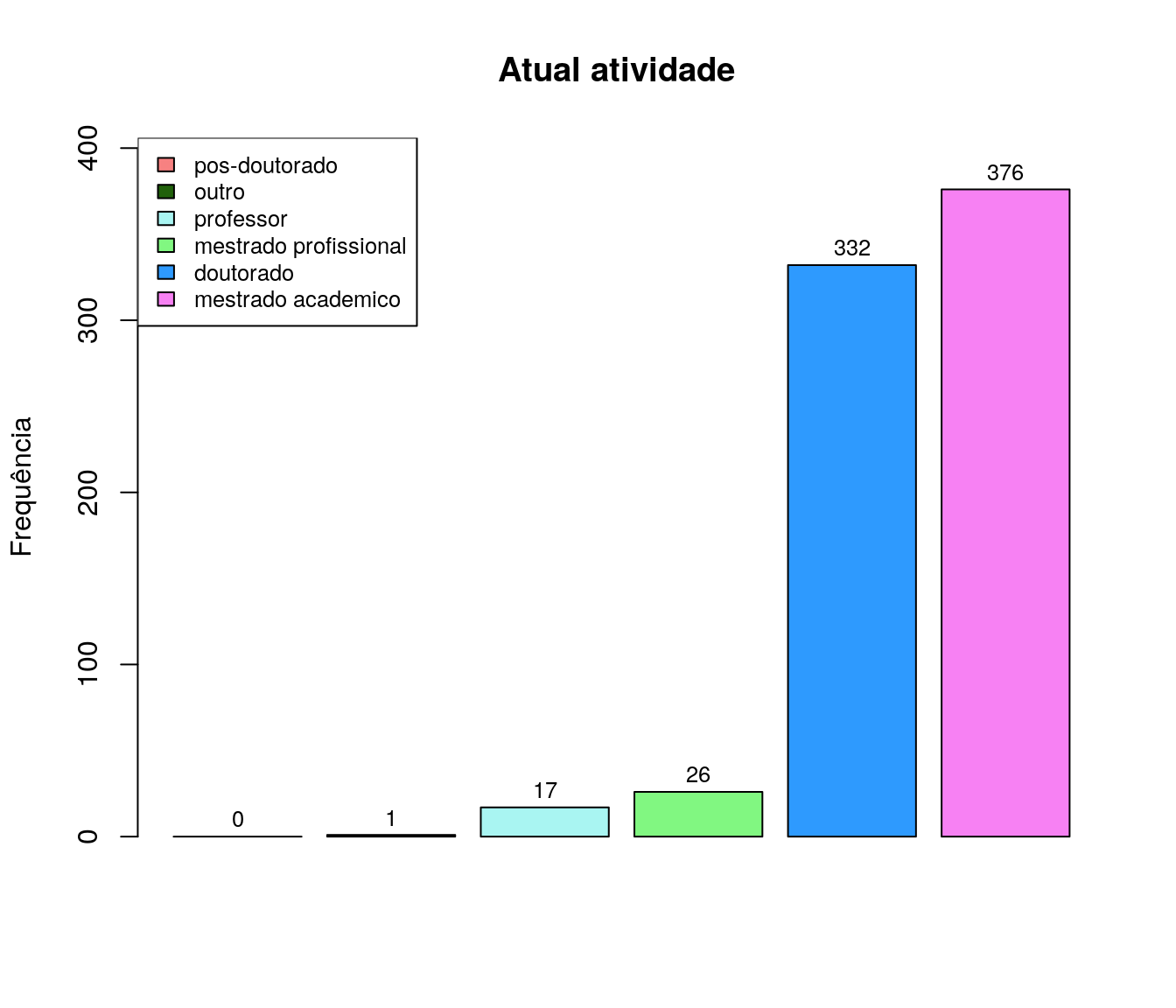
2019
antigo$lo_ativAtuacao <- tolower(iconv(antigo$lo_ativAtuacao,
to ='ASCII//TRANSLIT', from = "UTF-8"))
classOpcoes <- c("mestrado academico", "professor", "doutorado",
"mestrado profissional", "pos-doutorado")
antigo$lo_ativAtuacao[ !antigo$lo_ativAtuacao %in% classOpcoes ] <- "outro"
antigo$lo_ativAtuacao <- factor(antigo$lo_ativAtuacao,
levels = c("mestrado profissional",
"mestrado academico",
"doutorado",
"pos-doutorado", "professor", "outro"))
fa_at <- table(antigo$lo_ativAtuacao) # frequência absoluta
fr_at <- prop.table(fa_at) # frequência relativa
fac_at <- cumsum(fr_at) # frequência acumulada
at <- data.frame(niveis = names(fa_at),
freq = as.vector(fa_at),
freq_r = as.vector(fr_at),
freq_ac = as.vector(fac_at))
#pander:::pander(at)
at_ord <- arrange(at, at$freq)
barplot(at_ord$freq,
#names.arg = at_ord$niveis,
col = paleta,
main = 'Atual atividade ',
ylab = 'Frequência',
xlab = '',
ylim = c(0, max(at_ord$freq)+30)
#horiz = T,
#las=2,
)
legend("topleft",
legend = at_ord$niveis,
fill = paleta,
cex = .8)
text(x = as.vector(barplot(at_ord$freq, plot = FALSE)),
y = as.vector(at_ord$freq) + 10,
labels = at_ord$freq, cex = .8)
Em qual grande área do conhecimento sua pesquisa está inserida hoje?
Tabela
quest$ln_setorArea <- tolower(iconv(quest$ln_setorArea,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- c("ciencias humanas", "ciencias exatas",
"ciencias biologicas", "nao sei")
quest$ln_setorArea[ !quest$ln_setorArea %in% classOpcoes ] <- "outro"
fa_area <- table(quest$ln_setorArea) # frequência absoluta
fr_area <- prop.table(fa_area) # frequência relativa
fac_area <- cumsum(fr_area) # frequência acumulada
area <- data.frame(niveis = names(fa_area),
freq = as.vector(fa_area),
freq_r = as.vector(fr_area),
freq_ac = as.vector(fac_area))
pander:::pander(area)| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| ciencias biologicas | 401 | 0.5332 | 0.5332 |
| ciencias exatas | 227 | 0.3019 | 0.8351 |
| ciencias humanas | 124 | 0.1649 | 1 |
Gráfico
area$niveis <- c('Biologicas', 'Exatas', 'Humanas')
area_ord <- arrange(area, area$freq)
barplot(area_ord$freq,
names.arg = area_ord$niveis,
col = '#BCF5A9',
main = 'Área do conhecimento',
ylab = 'Frequência',
xlab = '',
ylim = c(0, max(area_ord$freq)+20)
#horiz = T,
#las=2,
)
text(x = as.vector(barplot(area_ord$freq, plot = FALSE)),
y = as.vector(area_ord$freq) + 10,
labels = area_ord$freq, cex = 1.5)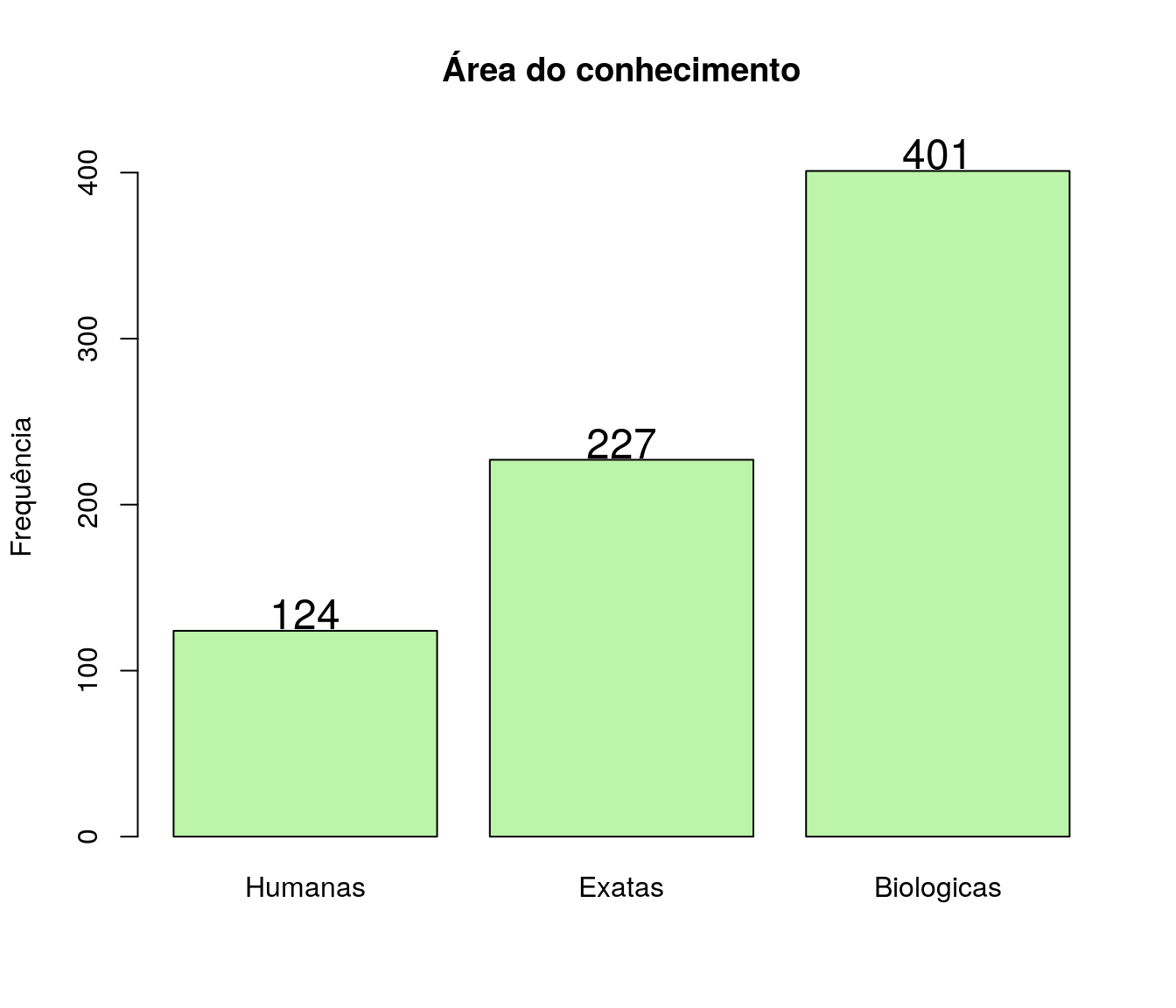
Em qual ano você concluiu sua graduação?
Tabela 1
fa_anog <- table(quest$tc_anoFimGrad) # frequência absoluta
fr_anog <- prop.table(fa_anog) # frequência relativa
fac_anog <- cumsum(fr_anog) # frequência acumulada
anog <- data.frame(niveis = names(fa_anog),
freq = as.vector(fa_anog),
freq_r = as.vector(fr_anog),
freq_ac = as.vector(fac_anog)) # unindo as informações
pander:::pander(anog) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| 1989 | 1 | 0.00133 | 0.00133 |
| 1990 | 5 | 0.006649 | 0.007979 |
| 1991 | 4 | 0.005319 | 0.0133 |
| 1992 | 2 | 0.00266 | 0.01596 |
| 1993 | 2 | 0.00266 | 0.01862 |
| 1994 | 5 | 0.006649 | 0.02527 |
| 1995 | 1 | 0.00133 | 0.0266 |
| 1996 | 3 | 0.003989 | 0.03059 |
| 1997 | 7 | 0.009309 | 0.03989 |
| 1998 | 7 | 0.009309 | 0.0492 |
| 1999 | 3 | 0.003989 | 0.05319 |
| 2000 | 9 | 0.01197 | 0.06516 |
| 2001 | 9 | 0.01197 | 0.07713 |
| 2002 | 15 | 0.01995 | 0.09707 |
| 2003 | 4 | 0.005319 | 0.1024 |
| 2004 | 12 | 0.01596 | 0.1184 |
| 2005 | 17 | 0.02261 | 0.141 |
| 2006 | 16 | 0.02128 | 0.1622 |
| 2007 | 25 | 0.03324 | 0.1955 |
| 2008 | 34 | 0.04521 | 0.2407 |
| 2009 | 14 | 0.01862 | 0.2593 |
| 2010 | 16 | 0.02128 | 0.2806 |
| 2011 | 22 | 0.02926 | 0.3098 |
| 2012 | 25 | 0.03324 | 0.3431 |
| 2013 | 39 | 0.05186 | 0.3949 |
| 2014 | 36 | 0.04787 | 0.4428 |
| 2015 | 55 | 0.07314 | 0.516 |
| 2016 | 64 | 0.08511 | 0.6011 |
| 2017 | 94 | 0.125 | 0.7261 |
| 2018 | 72 | 0.09574 | 0.8218 |
| 2019 | 112 | 0.1489 | 0.9707 |
| 2020 | 13 | 0.01729 | 0.988 |
| 2021 | 3 | 0.003989 | 0.992 |
| 2022 | 1 | 0.00133 | 0.9934 |
| 2023 | 1 | 0.00133 | 0.9947 |
| 2024 | 2 | 0.00266 | 0.9973 |
| 20032013 | 1 | 0.00133 | 0.9987 |
| 20132003 | 1 | 0.00133 | 1 |
Tabela 2
ar_anoFimGrad <- quest$tc_anoFimGrad[which(quest$tc_anoFimGrad > 1950 & quest$tc_anoFimGrad <= 2020)]
#excluindo respostas antes de 1950
h <- hist(ar_anoFimGrad, plot = FALSE) #histograma
breaks <- h$breaks #armazenando os breaks do histograma
classes <- cut(ar_anoFimGrad, breaks = breaks,
include.lowest = TRUE, right = TRUE) #gerando classes
tb.anoFimGrad <- as.data.frame(table(classes)) #gerando tabela com faixas
tb.anoFimGrad$Perc <- prop.table(tb.anoFimGrad$Freq)
names(tb.anoFimGrad)[1] <- "Ano"
pander:::pander(tb.anoFimGrad)| Ano | Freq | Perc |
|---|---|---|
| [1985,1990] | 6 | 0.008075 |
| (1990,1995] | 14 | 0.01884 |
| (1995,2000] | 29 | 0.03903 |
| (2000,2005] | 57 | 0.07672 |
| (2005,2010] | 105 | 0.1413 |
| (2010,2015] | 177 | 0.2382 |
| (2015,2020] | 355 | 0.4778 |
Tabela 3
medidas <- data.frame(minimo = quantile(ar_anoFimGrad)[1],
quart1 = quantile(ar_anoFimGrad)[2],
media = mean(ar_anoFimGrad),
mediana = quantile(ar_anoFimGrad)[3],
moda = names(sort(table(ar_anoFimGrad),
decreasing = TRUE)[1]),
quart3 = quantile(ar_anoFimGrad)[4],
max = quantile(ar_anoFimGrad)[5])
row.names(medidas) <- NULL
pander(medidas)| minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|
| 1989 | 2009 | 2013 | 2015 | 2019 | 2018 | 2020 |
disp <- data.frame(amplitude = diff(range(ar_anoFimGrad)),
variancia = var(ar_anoFimGrad),
desv_pad = sd(ar_anoFimGrad),
coef_var = 100*sd(ar_anoFimGrad)/mean(ar_anoFimGrad))
pander(disp)| amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|
| 31 | 44.02 | 6.635 | 0.3296 |
Gráfico 1
Variável sem tratamento
quest$tc_anoFimGrad <- as.integer(quest$tc_anoFimGrad)
plot(table(quest$tc_anoFimGrad),
t = "h", xlab = "Ano", ylab = "Frequência", lwd = 3,
cex.axis = 0.8, las = 2,
main = "Ano de Conclusão da Graduação")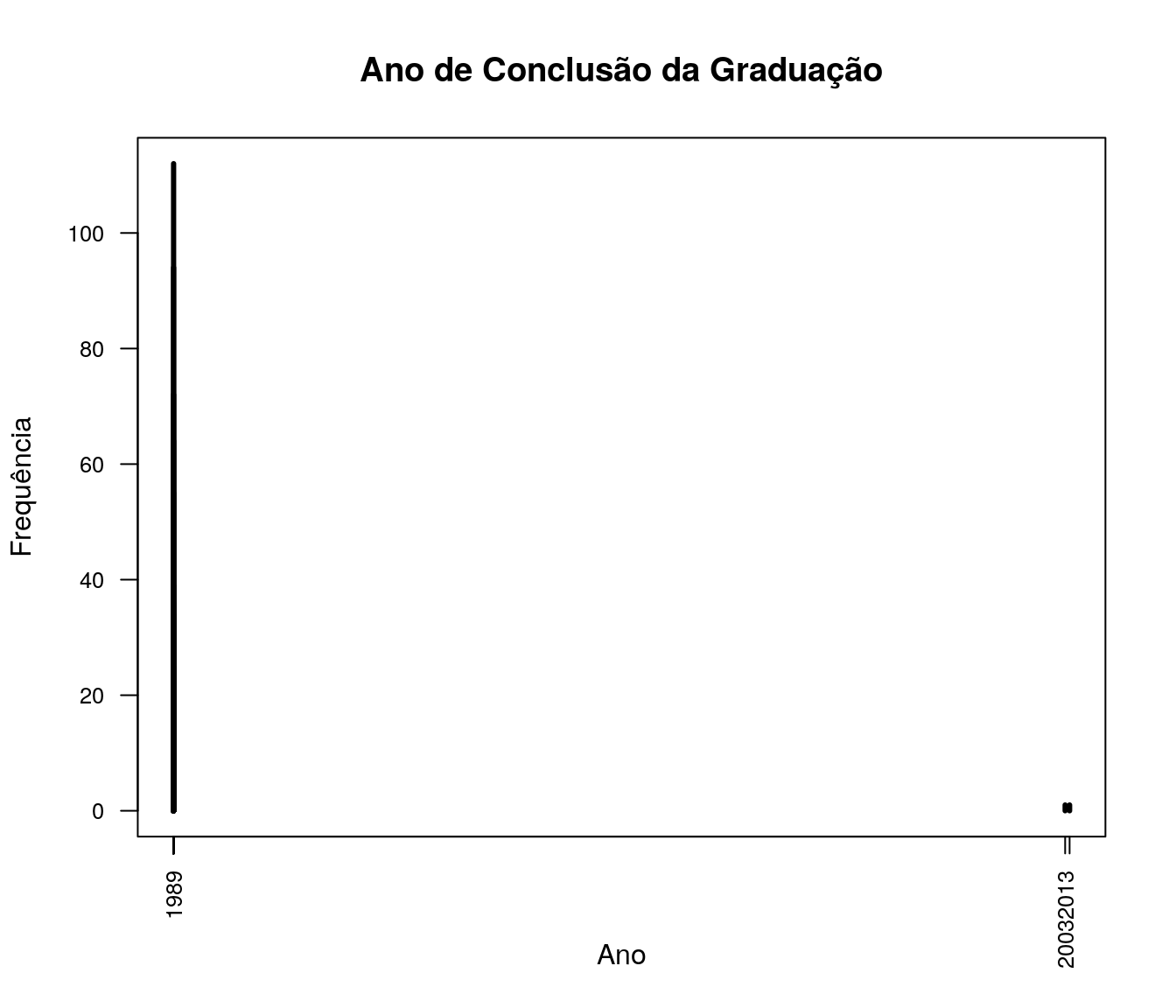
Gráfico 2
Variável com tratamento
plot(table(ar_anoFimGrad),
t = "h", xlab = "Ano", ylab = "Frequência", lwd = 3,
cex.axis = 0.8, las = 2,
main = "Ano de Conclusão da Graduação")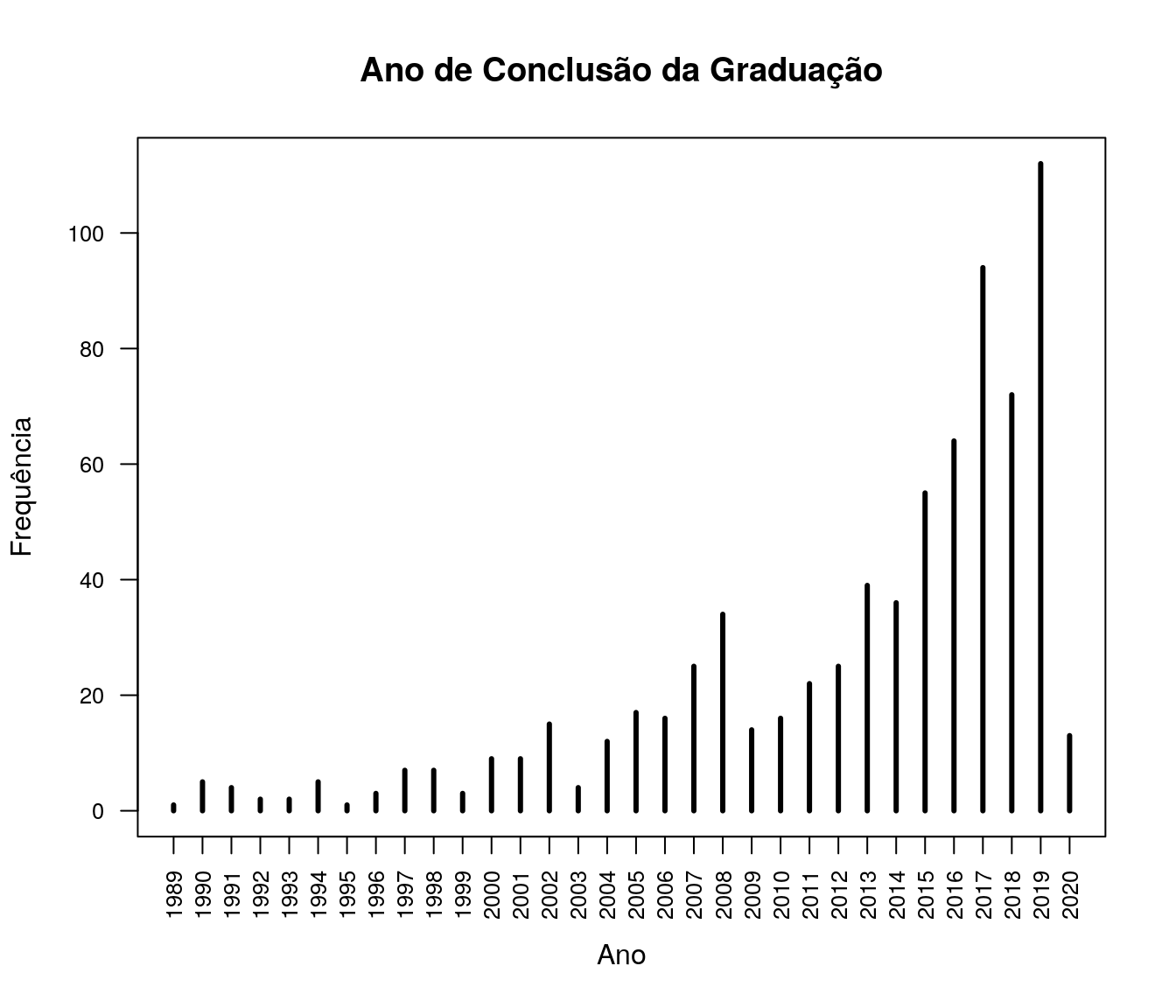
Gráfico 3
hist(ar_anoFimGrad, breaks = breaks, include.lowest = TRUE,
col = "#A9F5E1",
main = "Ano de Conclusão da Graduação", xlab = "Ano",
ylab = "Frequência")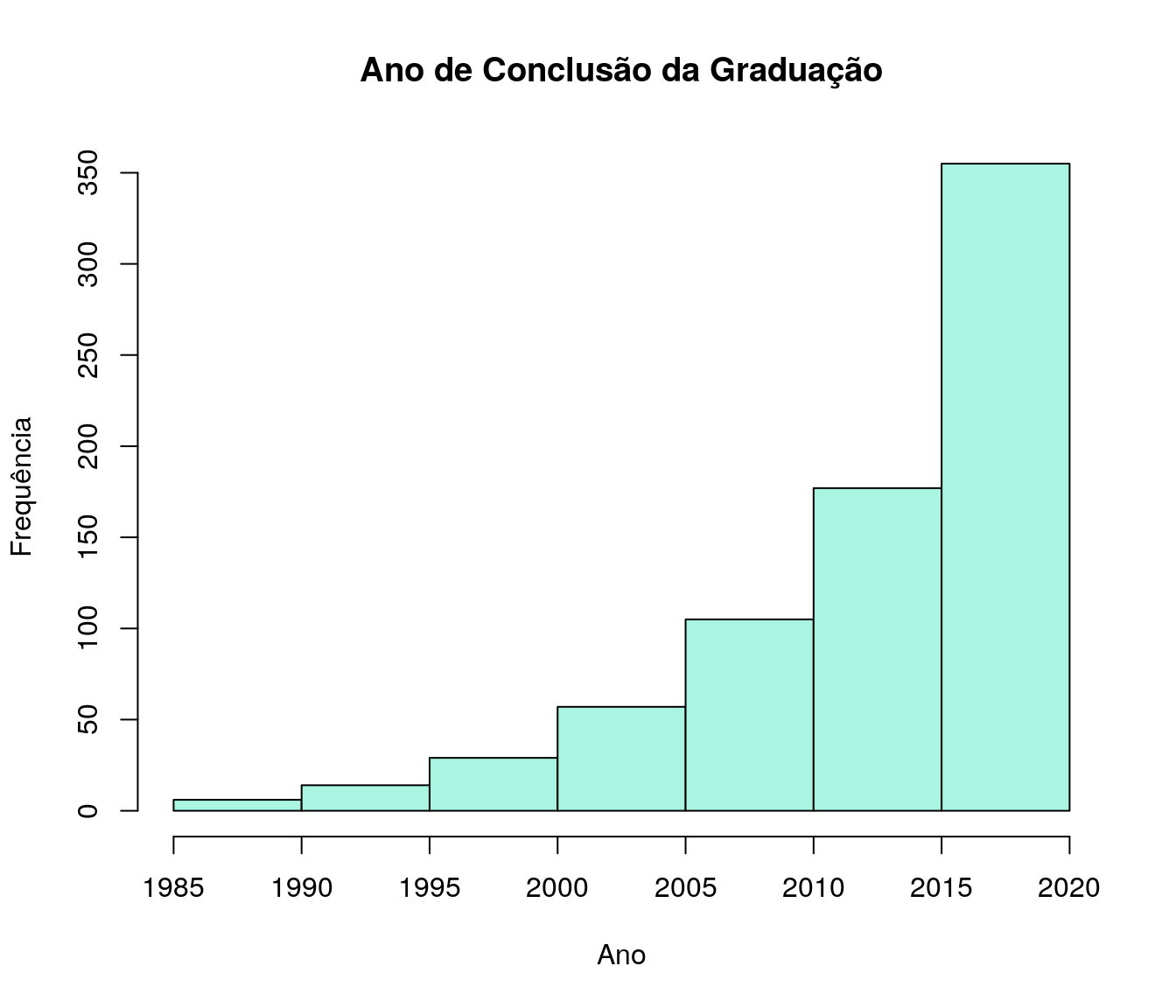
Gráfico 4
par(mfrow = c(2,1))
boxplot(ar_anoFimGrad, horizontal=T, col = "#A9D0F5", width = 1,
main = "Ano de Conclusão da Graduação")
boxplot(ar_anoFimGrad, horizontal=T, width = 1, col = "#A9D0F5")
stripchart(ar_anoFimGrad, vertical=F, add=T, method="jitter", pch=19, cex=0.5, jitter=0.3)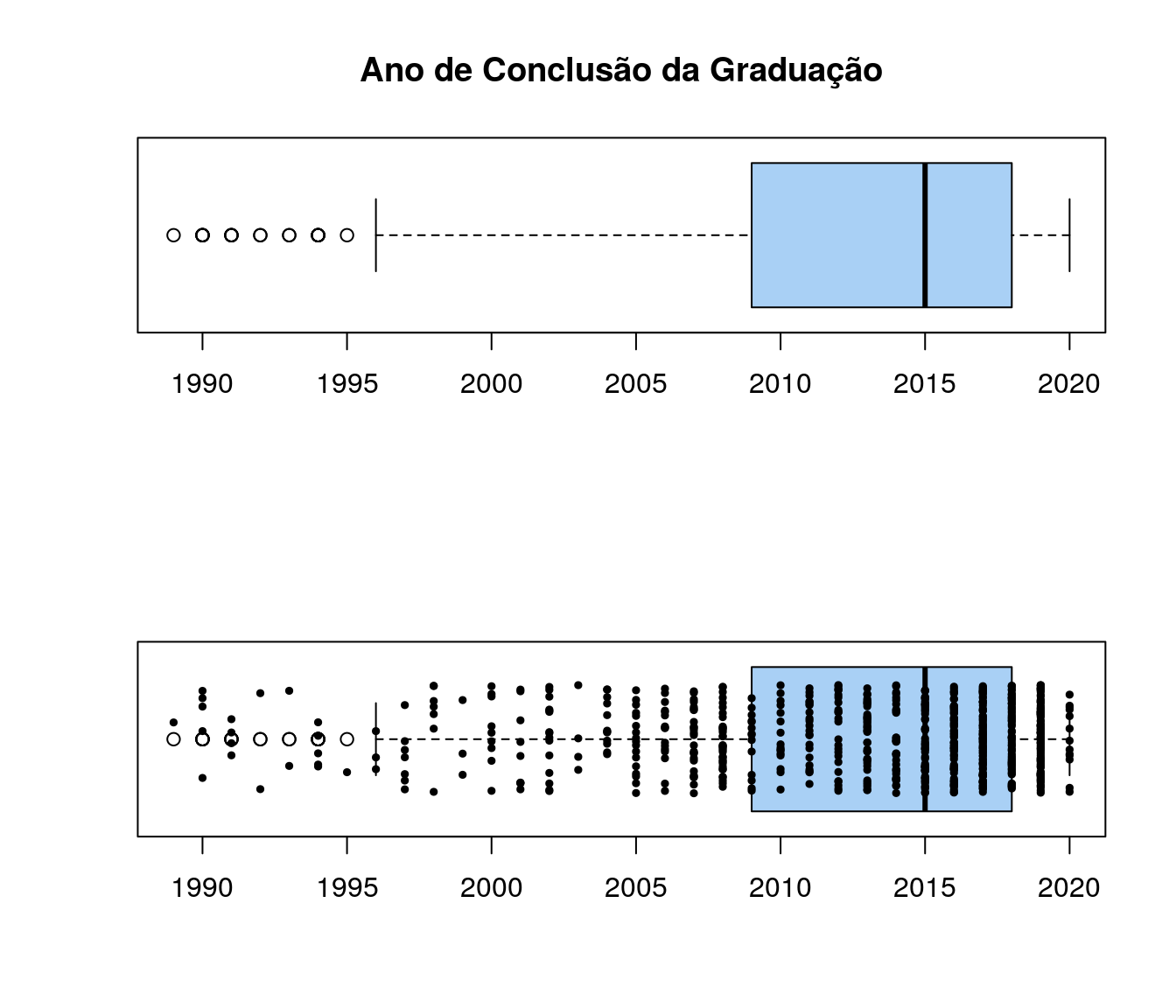
Gráfico 5
layout(mat = matrix(c(1,2),2,1, byrow=TRUE), height = c(3,1))
par(mar=c(3.1, 3.1, 1.1, 2.1))
hist(ar_anoFimGrad,col = "#CEF6D8",
main = "Ano de Conclusão da Graduação",
xlab = "Ano",
ylab = "Frequência")
boxplot(ar_anoFimGrad,
horizontal=TRUE,
outline=TRUE,
frame=F,
col = "#CEF6D8",
width = 10)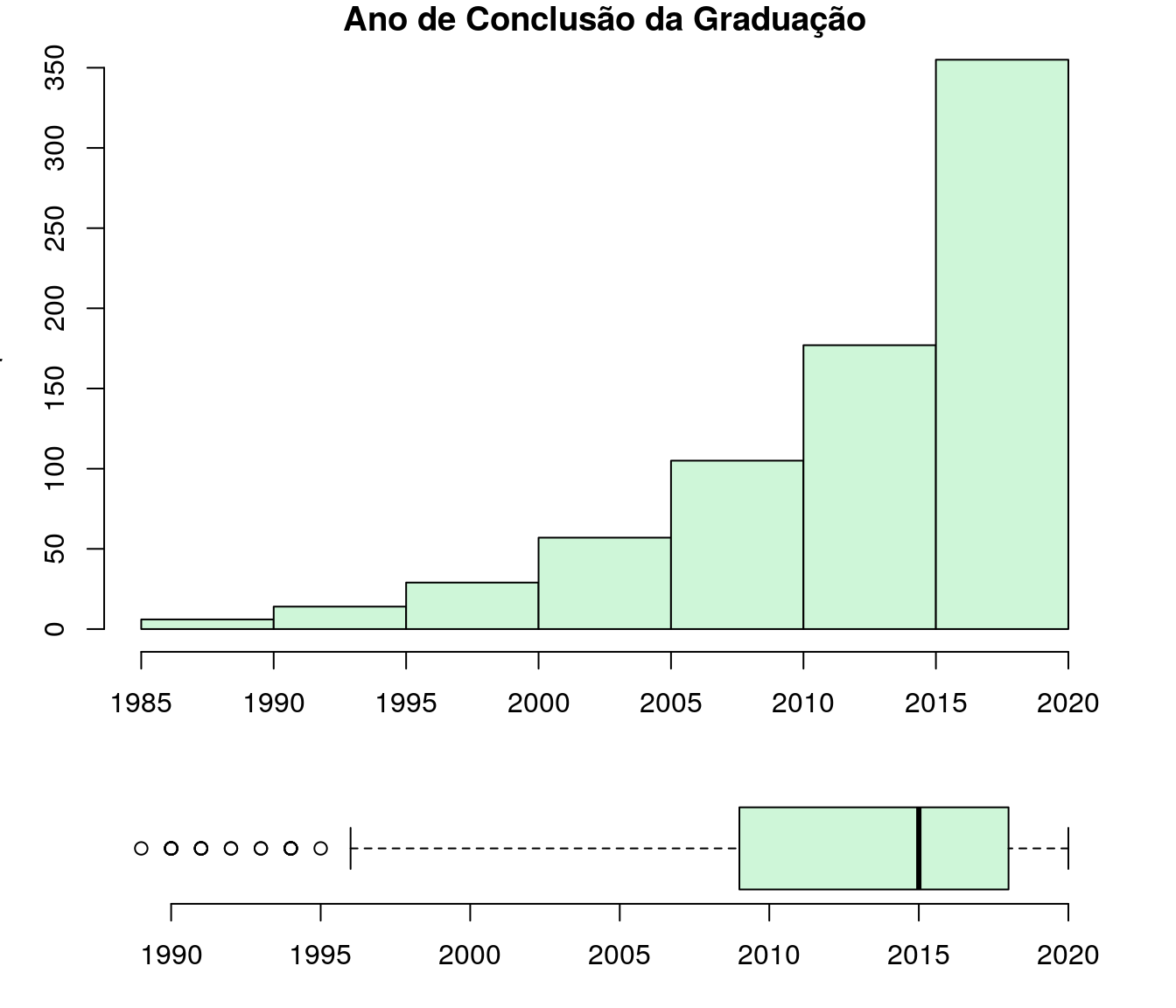
2019
ar_anoFimGrad <- antigo$tc_anoFimGrad[which(antigo$tc_anoFimGrad > 1950)]
#excluindo respostas antes de 1950
h <- hist(ar_anoFimGrad, plot = FALSE) #histograma
breaks <- h$breaks #armazenando os breaks do histograma
classes <- cut(ar_anoFimGrad, breaks = breaks,
include.lowest = TRUE, right = TRUE) #gerando classes
tb.anoFimGrad <- as.data.frame(table(classes)) #gerando tabela com faixas
tb.anoFimGrad$Perc <- prop.table(tb.anoFimGrad$Freq)
names(tb.anoFimGrad)[1] <- "Ano"
#pander:::pander(tb.anoFimGrad)
layout(mat = matrix(c(1,2),2,1, byrow=TRUE), height = c(3,1))
par(mar=c(3.1, 3.1, 1.1, 2.1))
hist(ar_anoFimGrad,col = "#CEF6D8",
main = "Ano de Conclusão da Graduação",
xlab = "Ano",
ylab = "Frequência")
boxplot(ar_anoFimGrad,
horizontal=TRUE,
outline=TRUE,
frame=F,
col = "#CEF6D8",
width = 10)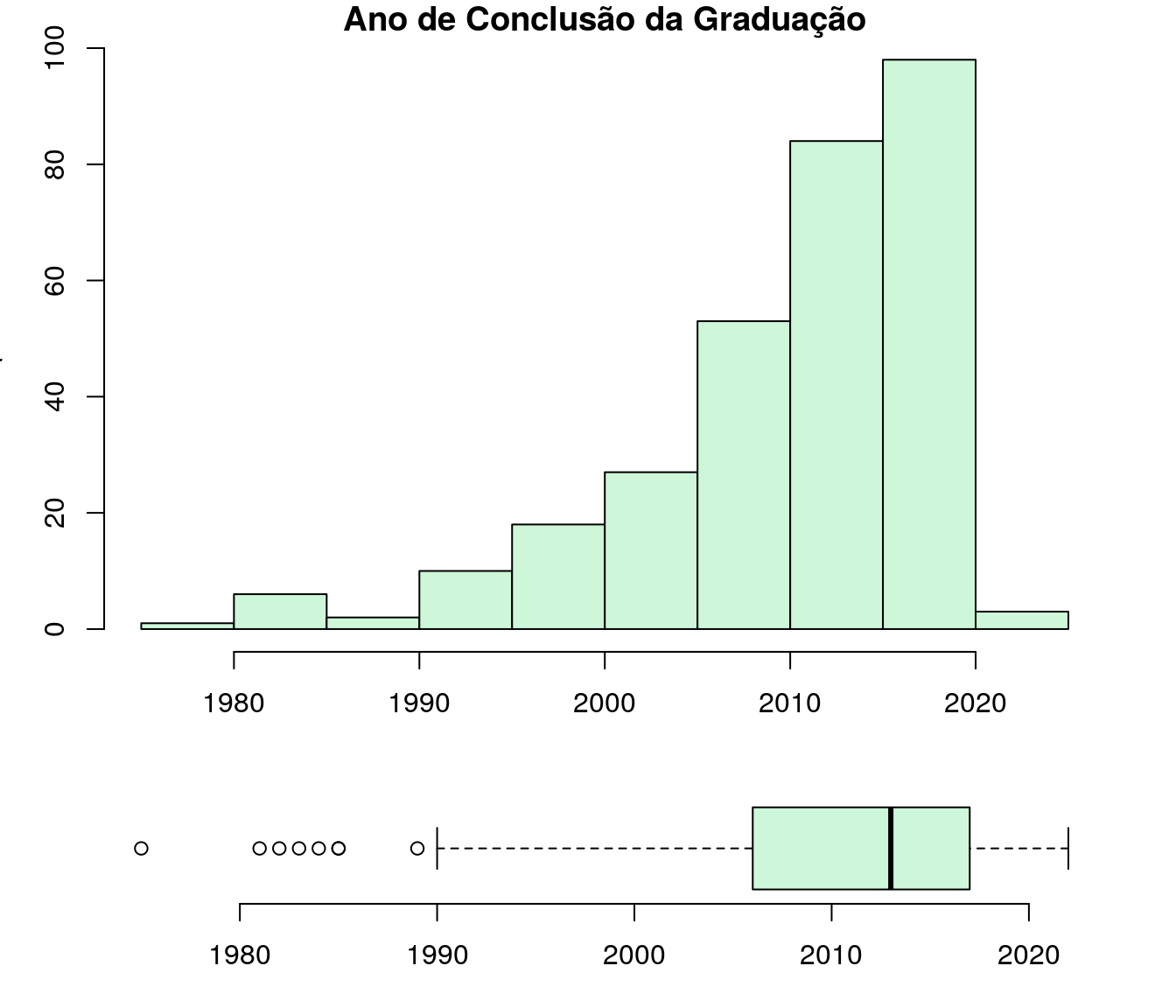
Em qual instituição você concluiu sua graduação?
Tabela
quest$ln_localGrad <- tolower(iconv(quest$ln_localGrad,
to ='ASCII//TRANSLIT', from = "UTF-8"))
classOpcoes <- tolower(c('UEL', 'UEM', 'UEPG', "UNIOESTE",
"UNICENTRO", "UENP", "UNILA",
"IFPR", "UTFPR", "UFPR"))
quest$ln_localGrad[ !quest$ln_localGrad %in% classOpcoes ] <- "outro"
quest$ln_localGrad <- factor(quest$ln_localGrad,
levels = tolower(c('UEL', 'UEM', 'UEPG',
"UNIOESTE",
"UNICENTRO", "UENP",
"UNILA", "IFPR",
"UTFPR", "UFPR",
"OUTRO")))
fa_loc <- table(quest$ln_localGrad) # frequência absoluta
fr_loc <- prop.table(fa_loc) # frequência relativa
fac_loc <- cumsum(fr_loc) # frequência acumulada
loc <- data.frame(niveis = names(fa_loc),
freq = as.vector(fa_loc),
freq_r = as.vector(fr_loc),
freq_ac = as.vector(fac_loc)) # unindo as informações
pander:::pander(loc) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| uel | 5 | 0.006649 | 0.006649 |
| uem | 8 | 0.01064 | 0.01729 |
| uepg | 88 | 0.117 | 0.1343 |
| unioeste | 31 | 0.04122 | 0.1755 |
| unicentro | 28 | 0.03723 | 0.2128 |
| uenp | 2 | 0.00266 | 0.2154 |
| unila | 10 | 0.0133 | 0.2287 |
| ifpr | 2 | 0.00266 | 0.2314 |
| utfpr | 21 | 0.02793 | 0.2593 |
| ufpr | 172 | 0.2287 | 0.488 |
| outro | 385 | 0.512 | 1 |
Gráfico
loc_ord <- arrange(loc, loc$freq)
barplot(loc_ord$freq, col = '#BEF781',
names.arg = loc_ord$niveis, horiz = T,
xlim = c(0, max(loc_ord$freq + 30)),
main = "Graduação",
las = 2)
text(y = as.vector(barplot(loc_ord$freq, plot = FALSE)),
x = as.vector(loc_ord$freq) + 10,
labels = loc_ord$freq, cex = .8)
abline(v=50, lty=3, col = 2)
abline(v=100, lty=3, col = 2)
abline(v=150, lty=3, col = 2)
abline(v=200, lty=3, col = 2)
abline(v=250, lty=3, col = 2)
abline(v=300, lty=3, col = 2)
abline(v=350, lty=3, col = 2)
abline(v=400, lty=3, col = 2)
abline(v=450, lty=3, col = 2)
abline(v=500, lty=3, col = 2)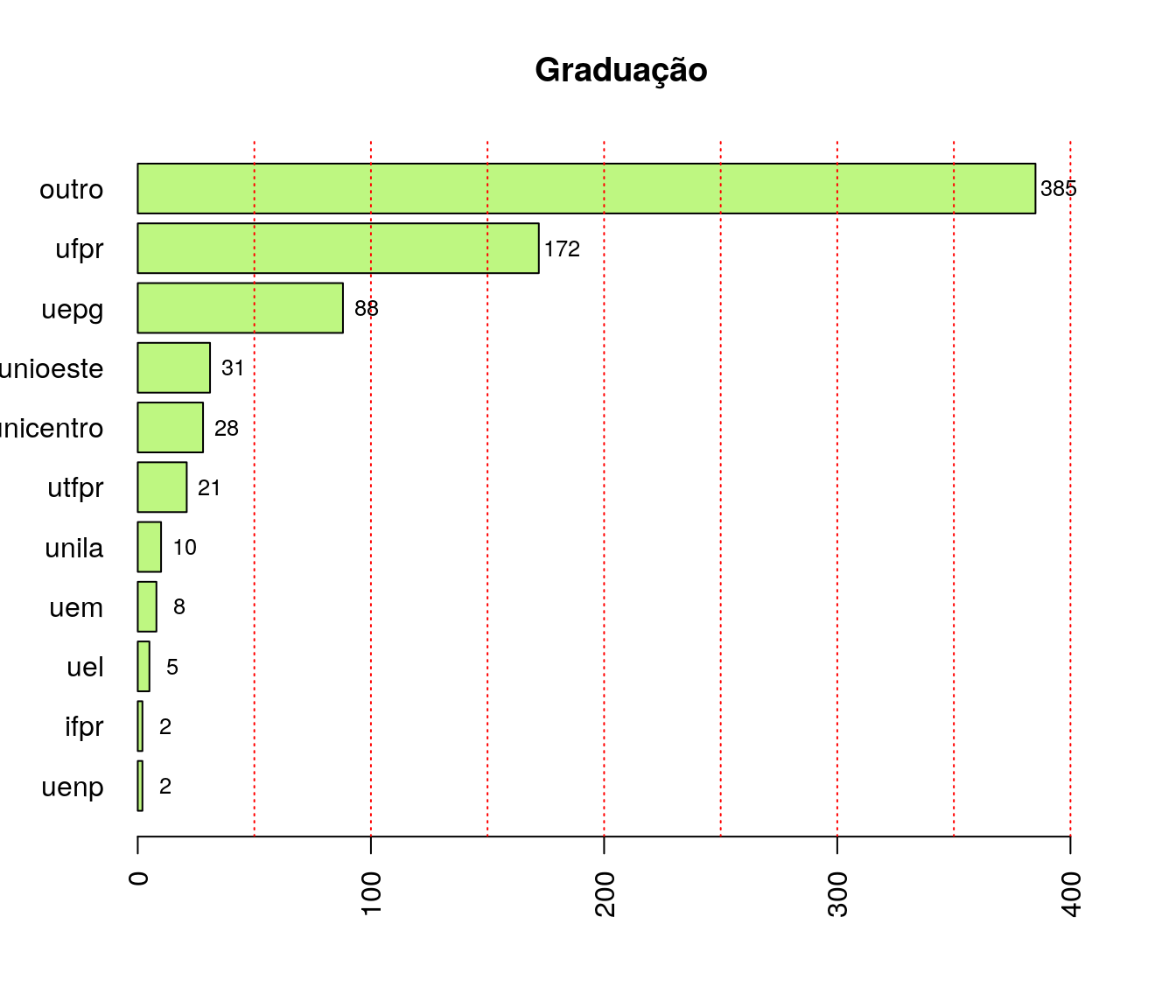
2019
antigo$ln_localGrad <- tolower(iconv(antigo$ln_localGrad,
to ='ASCII//TRANSLIT', from = "UTF-8"))
classOpcoes <- tolower(c('UEL', 'UEM', 'UEPG', "UNIOESTE",
"UNICENTRO", "UENP", "UNILA",
"IFPR", "UTFPR", "UFPR"))
antigo$ln_localGrad[ !antigo$ln_localGrad %in% classOpcoes ] <- "outro"
antigo$ln_localGrad <- factor(antigo$ln_localGrad,
levels = tolower(c('UEL', 'UEM', 'UEPG',
"UNIOESTE",
"UNICENTRO", "UENP",
"UNILA", "IFPR",
"UTFPR", "UFPR",
"OUTRO")))
fa_loc <- table(antigo$ln_localGrad) # frequência absoluta
fr_loc <- prop.table(fa_loc) # frequência relativa
fac_loc <- cumsum(fr_loc) # frequência acumulada
loc <- data.frame(niveis = names(fa_loc),
freq = as.vector(fa_loc),
freq_r = as.vector(fr_loc),
freq_ac = as.vector(fac_loc)) # unindo as informações
#pander:::pander(loc) # gerando a tabela
loc_ord <- arrange(loc, loc$freq)
barplot(loc_ord$freq, col = '#BEF781',
names.arg = loc_ord$niveis, horiz = T,
xlim = c(0, max(loc_ord$freq + 30)),
main = "Graduação",
las = 2)
text(y = as.vector(barplot(loc_ord$freq, plot = FALSE)),
x = as.vector(loc_ord$freq) + 10,
labels = loc_ord$freq, cex = .8)
abline(v=50, lty=3, col = 2)
abline(v=100, lty=3, col = 2)
abline(v=150, lty=3, col = 2)
abline(v=200, lty=3, col = 2)
abline(v=250, lty=3, col = 2)
abline(v=300, lty=3, col = 2)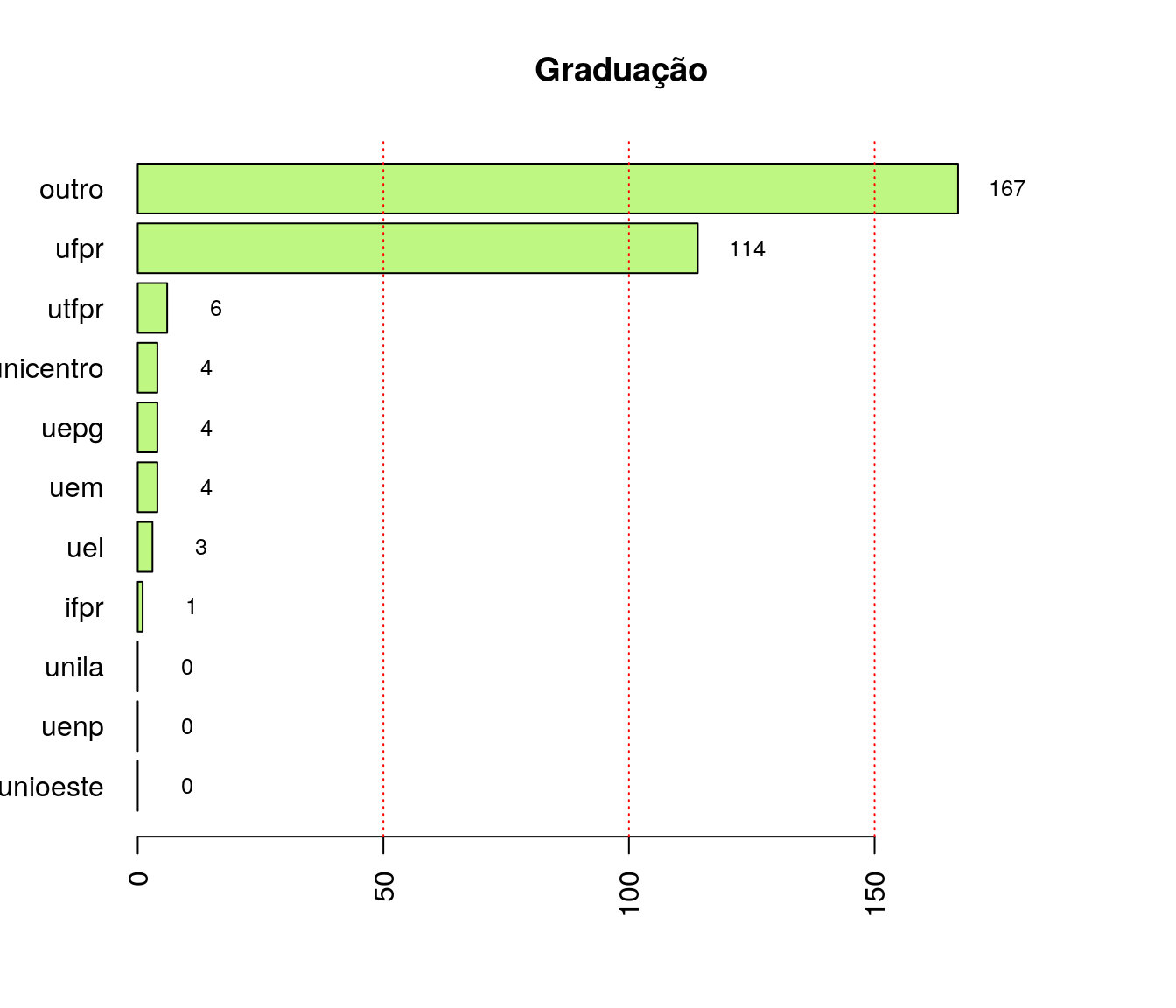
De quais programas de graduação você participou?
Tabela
quest$ln_progGrad <- tolower(iconv(quest$ln_progGrad,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$ln_progGrad <- ifelse(quest$ln_progGrad == "", NA, quest$ln_progGrad)
quest$ln_progGrad <- gsub(",",";",quest$ln_progGrad)
ar_progGrad <- cSplit(quest, "ln_progGrad", sep = ";",
direction = "long")$ln_progGrad
ar_progGrad <- as.character(ar_progGrad)
ar_progGrad[ which(is.na(ar_progGrad)) ] <- "nenhum"
classOpcoes <- c("iniciacao cientifica",
"pet",
"monitoria",
"projeto de extensao",
"empresa junior",
"nenhum")
ar_progGrad[ !ar_progGrad %in% classOpcoes ] <- "outro"
ar_progGrad <- as.factor(ar_progGrad)
ar_progGrad <- factor(ar_progGrad,
levels = c("iniciacao cientifica",
"pet", "monitoria",
"projeto de extensao",
"empresa junior",
"outro", "nenhum"))
fa_prog <- table(ar_progGrad) # frequência absoluta
fr_prog <- prop.table(fa_prog) # frequência relativa
fac_prog <- cumsum(fr_prog) # frequência acumulada
prog <- data.frame(niveis = names(fa_prog),
freq = as.vector(fa_prog),
freq_r = as.vector(fr_prog),
freq_ac = as.vector(fac_prog)) # unindo as informações
pander:::pander(prog) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| iniciacao cientifica | 415 | 0.3079 | 0.3079 |
| pet | 46 | 0.03412 | 0.342 |
| monitoria | 325 | 0.2411 | 0.5831 |
| projeto de extensao | 332 | 0.2463 | 0.8294 |
| empresa junior | 31 | 0.023 | 0.8524 |
| outro | 45 | 0.03338 | 0.8858 |
| nenhum | 154 | 0.1142 | 1 |
Gráfico
prog_ord <- arrange(prog, prog$freq)
bp <- barplot(prog_ord$freq,
#names.arg = at_ord$niveis,
col = paleta,
main = 'Programas',
ylab = 'Frequência',
xlab = 'Programas',
ylim = c(0,max(prog_ord$freq+50))
#horiz = T,
#las=2,
)
legend("topleft",
legend = prog_ord$niveis,
fill = paleta,
cex = .8)
text(x = c(bp),
y = prog_ord$freq,
labels = prog_ord$freq,
pos = 3)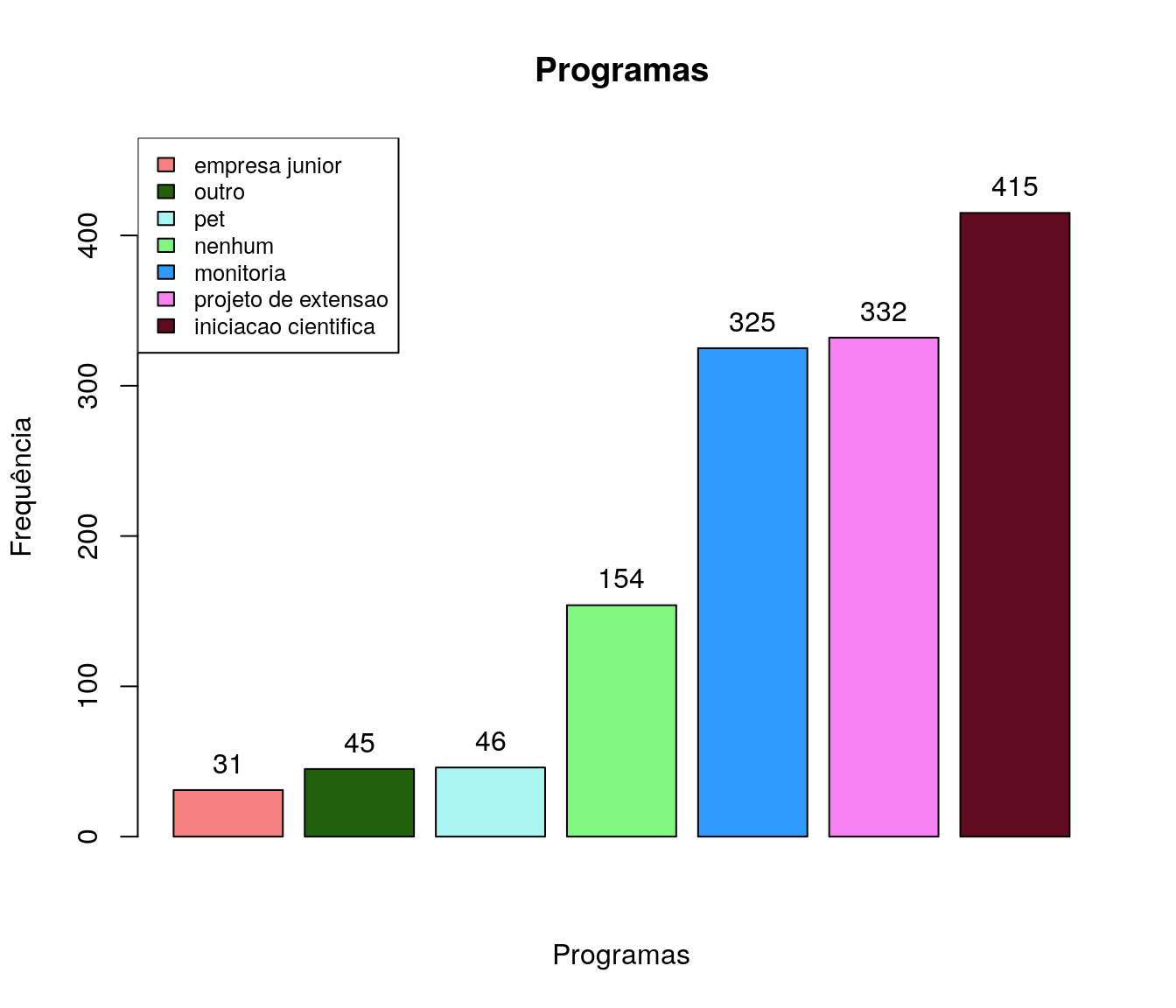
2019
antigo$ln_progGrad <- tolower(iconv(antigo$ln_progGrad,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
antigo$ln_progGrad <- ifelse(antigo$ln_progGrad == "", NA, antigo$ln_progGrad)
antigo$ln_progGrad <- gsub(",",";",antigo$ln_progGrad)
ar_progGrad <- cSplit(antigo, "ln_progGrad", sep = ";",
direction = "long")$ln_progGrad
ar_progGrad <- as.character(ar_progGrad)
ar_progGrad[ which(is.na(ar_progGrad)) ] <- "nenhum"
classOpcoes <- c("iniciacao cientifica",
"pet",
"monitoria",
"projeto de extensao",
"empresa junior",
"nenhum")
ar_progGrad[ !ar_progGrad %in% classOpcoes ] <- "outro"
ar_progGrad <- as.factor(ar_progGrad)
ar_progGrad <- factor(ar_progGrad,
levels = c("iniciacao cientifica",
"pet", "monitoria",
"projeto de extensao",
"empresa junior",
"outro", "nenhum"))
fa_prog <- table(ar_progGrad) # frequência absoluta
fr_prog <- prop.table(fa_prog) # frequência relativa
fac_prog <- cumsum(fr_prog) # frequência acumulada
prog <- data.frame(niveis = names(fa_prog),
freq = as.vector(fa_prog),
freq_r = as.vector(fr_prog),
freq_ac = as.vector(fac_prog)) # unindo as informações
#pander:::pander(prog) # gerando a tabela
prog_ord <- arrange(prog, prog$freq)
bp <- barplot(prog_ord$freq,
#names.arg = at_ord$niveis,
col = paleta,
main = 'Programas',
ylab = 'Frequência',
xlab = 'Programas',
ylim = c(0,max(prog_ord$freq+50))
#horiz = T,
#las=2,
)
legend("topleft",
legend = prog_ord$niveis,
fill = paleta,
cex = .8)
text(x = c(bp),
y = prog_ord$freq,
labels = prog_ord$freq,
pos = 3)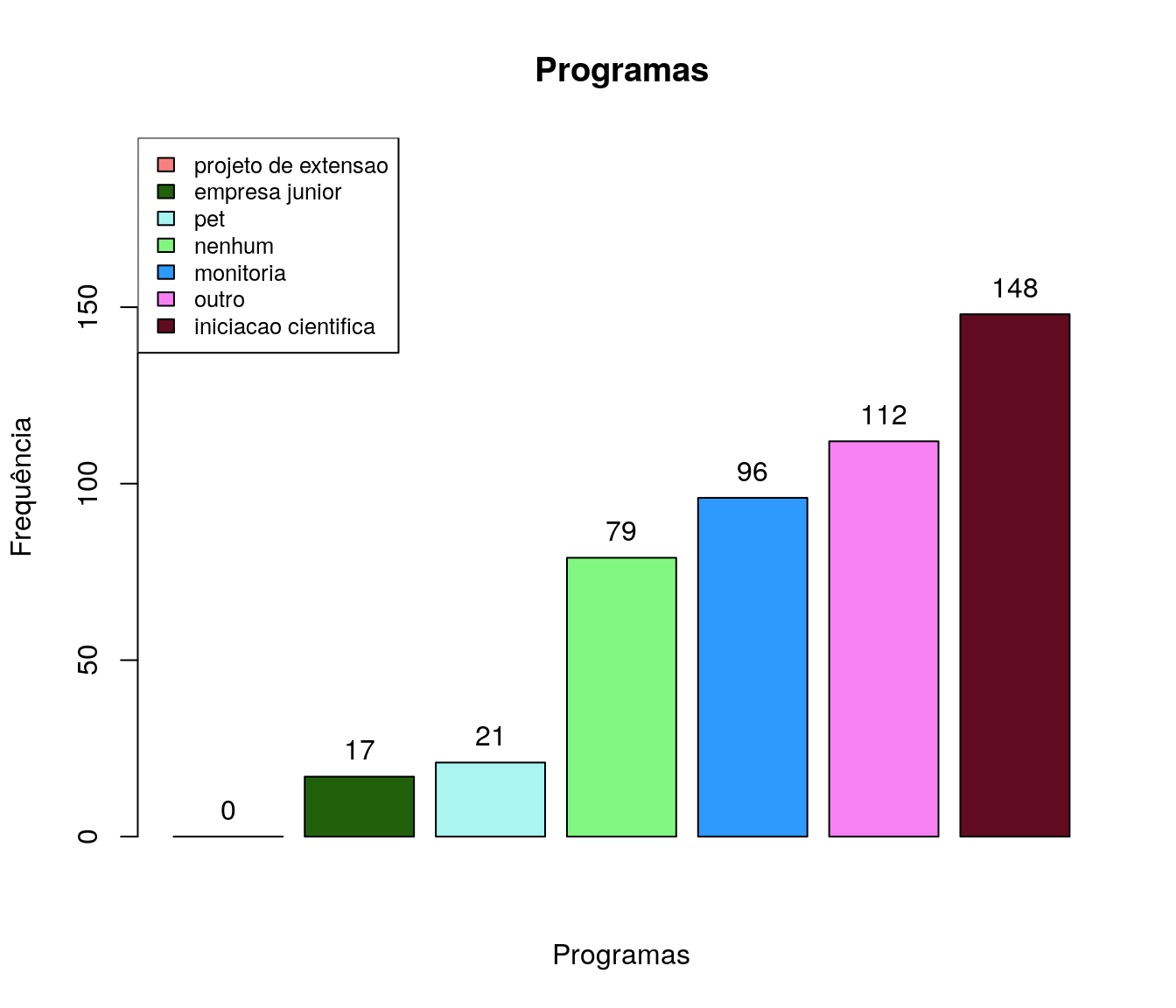
Se você já concluiu o mestrado, qual o ano de início do mestrado? E qual o ano de conclusão do seu mestrado?
Tabela
qtddFimMestrado <- sum(at$freq) - sum(at$freq[unique(at$niveis) == c("mestrado profissional", "mestrado academico")])
quest$tc_inicMest <- as.integer(quest$tc_inicMest)
quest$tc_fimMest <- as.integer(quest$tc_fimMest)
indices <- which(!(is.na(quest$tc_inicMest) | is.na(quest$tc_fimMest)))
tempoMest <- quest$tc_fimMest[indices] - quest$tc_inicMest[indices]
tempoMestValido <- tempoMest[which(tempoMest > 0)]
tb.tempoMest <- as.data.frame(table(tempoMestValido))
tb.tempoMest$Perc <- 100 * prop.table(tb.tempoMest$Freq)
names(tb.tempoMest)[1] <- "Duração do Mestrado"
pander:::pander(tb.tempoMest)| Duração do Mestrado | Freq | Perc |
|---|---|---|
| 1 | 27 | 7.849 |
| 2 | 294 | 85.47 |
| 3 | 22 | 6.395 |
| 4 | 1 | 0.2907 |
Gráfico
plot(table(tempoMestValido), t = "h", xlab = "Duração", ylab = "Frequência", lwd = 6,
cex.axis = 0.8, main = "Duração do Mestrado")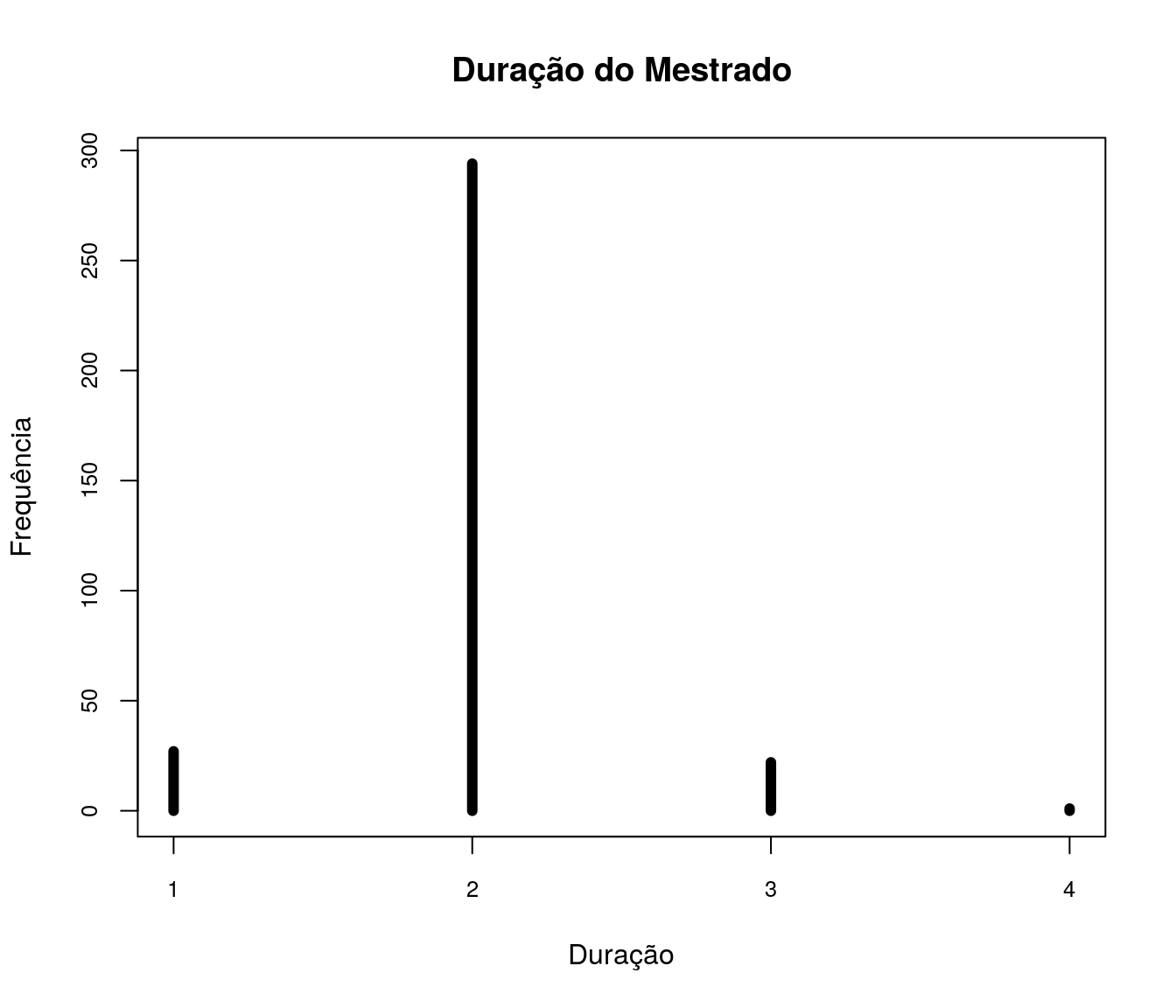
2019
qtddFimMestrado <- sum(at$freq) - sum(at$freq[unique(at$niveis) == c("mestrado profissional", "mestrado academico")])
antigo$tc_inicMest <- as.integer(antigo$tc_inicMest)
antigo$tc_fimMest <- as.integer(antigo$tc_fimMest)
indices <- which(!(is.na(antigo$tc_inicMest) | is.na(antigo$tc_fimMest)))
tempoMest <- antigo$tc_fimMest[indices] - antigo$tc_inicMest[indices]
tempoMestValido <- tempoMest[which(tempoMest > 0)]
tb.tempoMest <- as.data.frame(table(tempoMestValido))
tb.tempoMest$Perc <- 100 * prop.table(tb.tempoMest$Freq)
names(tb.tempoMest)[1] <- "Duração do Mestrado"
#pander:::pander(tb.tempoMest)
plot(table(tempoMestValido), t = "h", xlab = "Duração", ylab = "Frequência", lwd = 6,
cex.axis = 0.8, main = "Duração do Mestrado")
Em qual instituição você fez seu mestrado?
Tabela 1
Todas as respostas
quest$ln_localMest <- tolower(iconv(quest$ln_localMest,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- tolower(c('UEL', 'UEM', 'UEPG', "UNIOESTE",
"UNICENTRO", "UENP", "UNILA",
"IFPR", "UTFPR", "UFPR", ""))
quest$ln_localMest[ !quest$ln_localMest %in% classOpcoes ] <- "outro"
quest$ln_localMest <- factor(quest$ln_localMest,
levels = tolower(c('UEL', 'UEM', 'UEPG',
"UNIOESTE",
"UNICENTRO", "UENP",
"UNILA", "IFPR",
"UTFPR", "UFPR",
"OUTRO")))
fa_lmest <- table(quest$ln_localMest) # frequência absoluta
fr_lmest <- prop.table(fa_lmest) # frequência relativa
fac_lmest <- cumsum(fr_lmest) # frequência acumulada
lmest <- data.frame(niveis = names(fa_lmest),
freq = as.vector(fa_lmest),
freq_r = as.vector(fr_lmest),
freq_ac = as.vector(fac_lmest)) # unindo as informações
pander:::pander(lmest) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| uel | 2 | 0.005128 | 0.005128 |
| uem | 7 | 0.01795 | 0.02308 |
| uepg | 56 | 0.1436 | 0.1667 |
| unioeste | 28 | 0.07179 | 0.2385 |
| unicentro | 22 | 0.05641 | 0.2949 |
| uenp | 0 | 0 | 0.2949 |
| unila | 3 | 0.007692 | 0.3026 |
| ifpr | 0 | 0 | 0.3026 |
| utfpr | 6 | 0.01538 | 0.3179 |
| ufpr | 170 | 0.4359 | 0.7538 |
| outro | 96 | 0.2462 | 1 |
Tabela 2
Respostas válidas
quest$ln_localMest <- tolower(iconv(quest$ln_localMest,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- tolower(c('UEL', 'UEM', 'UEPG', "UNIOESTE",
"UNICENTRO", "UENP", "UNILA",
"IFPR", "UTFPR", "UFPR", ""))
quest$ln_localMest[ !quest$ln_localMest %in% classOpcoes ] <- "outro"
quest$ln_localMest <- factor(quest$ln_localMest,
levels = tolower(c('UEL', 'UEM', 'UEPG',
"UNIOESTE",
"UNICENTRO", "UENP",
"UNILA", "IFPR",
"UTFPR", "UFPR",
"OUTRO")))
quest_mest <- subset(quest, quest$tc_fimMest <= 2020)
fa_lmest <- table(quest_mest$ln_localMest) # frequência absoluta
fr_lmest <- prop.table(fa_lmest) # frequência relativa
fac_lmest <- cumsum(fr_lmest) # frequência acumulada
lmest <- data.frame(niveis = names(fa_lmest),
freq = as.vector(fa_lmest),
freq_r = as.vector(fr_lmest),
freq_ac = as.vector(fac_lmest)) # unindo as informações
pander:::pander(lmest) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| uel | 2 | 0.005848 | 0.005848 |
| uem | 7 | 0.02047 | 0.02632 |
| uepg | 50 | 0.1462 | 0.1725 |
| unioeste | 27 | 0.07895 | 0.2515 |
| unicentro | 21 | 0.0614 | 0.3129 |
| uenp | 0 | 0 | 0.3129 |
| unila | 2 | 0.005848 | 0.3187 |
| ifpr | 0 | 0 | 0.3187 |
| utfpr | 6 | 0.01754 | 0.3363 |
| ufpr | 130 | 0.3801 | 0.7164 |
| outro | 97 | 0.2836 | 1 |
Gráfico
lmest_ord <- arrange(lmest, lmest$freq)
barplot(lmest_ord$freq, col = '#D0A9F5',
names.arg = lmest_ord$niveis, horiz = T,
xlim = c(0, max(lmest_ord$freq + 30)),
main = "Instituição em que fez o mestrado",
las = 2)
text(y = as.vector(barplot(lmest_ord$freq, plot = FALSE)),
x = as.vector(lmest_ord$freq) + 5,
labels = lmest_ord$freq, cex = .8)
abline(v=50, lty=3, col = 2)
abline(v=100, lty=3, col = 2)
abline(v=150, lty=3, col = 2)
abline(v=200, lty=3, col = 2)
abline(v=250, lty=3, col = 2)
abline(v=300, lty=3, col = 2)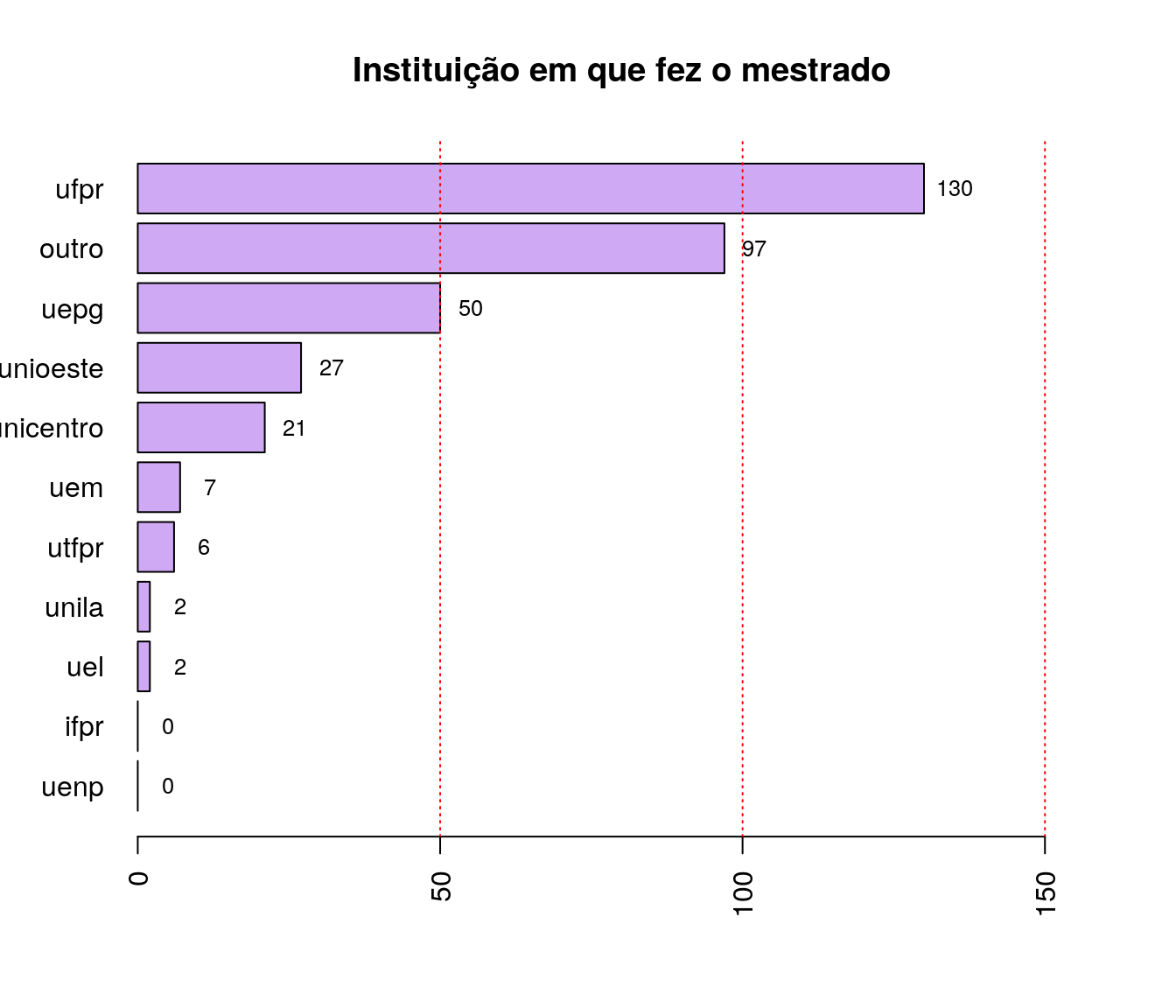
2019
antigo$ln_localMest <- tolower(iconv(antigo$ln_localMest,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- tolower(c('UEL', 'UEM', 'UEPG', "UNIOESTE",
"UNICENTRO", "UENP", "UNILA",
"IFPR", "UTFPR", "UFPR", ""))
antigo$ln_localMest[ !antigo$ln_localMest %in% classOpcoes ] <- "outro"
antigo$ln_localMest <- factor(antigo$ln_localMest,
levels = tolower(c('UEL', 'UEM', 'UEPG',
"UNIOESTE",
"UNICENTRO", "UENP",
"UNILA", "IFPR",
"UTFPR", "UFPR",
"OUTRO")))
antigo_mest <- subset(antigo, antigo$tc_fimMest <= 2020)
fa_lmest <- table(antigo_mest$ln_localMest) # frequência absoluta
fr_lmest <- prop.table(fa_lmest) # frequência relativa
fac_lmest <- cumsum(fr_lmest) # frequência acumulada
lmest <- data.frame(niveis = names(fa_lmest),
freq = as.vector(fa_lmest),
freq_r = as.vector(fr_lmest),
freq_ac = as.vector(fac_lmest)) # unindo as informações
#pander:::pander(lmest) # gerando a tabela
lmest_ord <- arrange(lmest, lmest$freq)
barplot(lmest_ord$freq, col = '#D0A9F5',
names.arg = lmest_ord$niveis, horiz = T,
xlim = c(0, max(lmest_ord$freq + 30)),
main = "Instituição em que fez o mestrado",
las = 2)
text(y = as.vector(barplot(lmest_ord$freq, plot = FALSE)),
x = as.vector(lmest_ord$freq) + 10,
labels = lmest_ord$freq, cex = .8)
abline(v=50, lty=3, col = 2)
abline(v=100, lty=3, col = 2)
abline(v=150, lty=3, col = 2)
abline(v=200, lty=3, col = 2)
abline(v=250, lty=3, col = 2)
abline(v=300, lty=3, col = 2)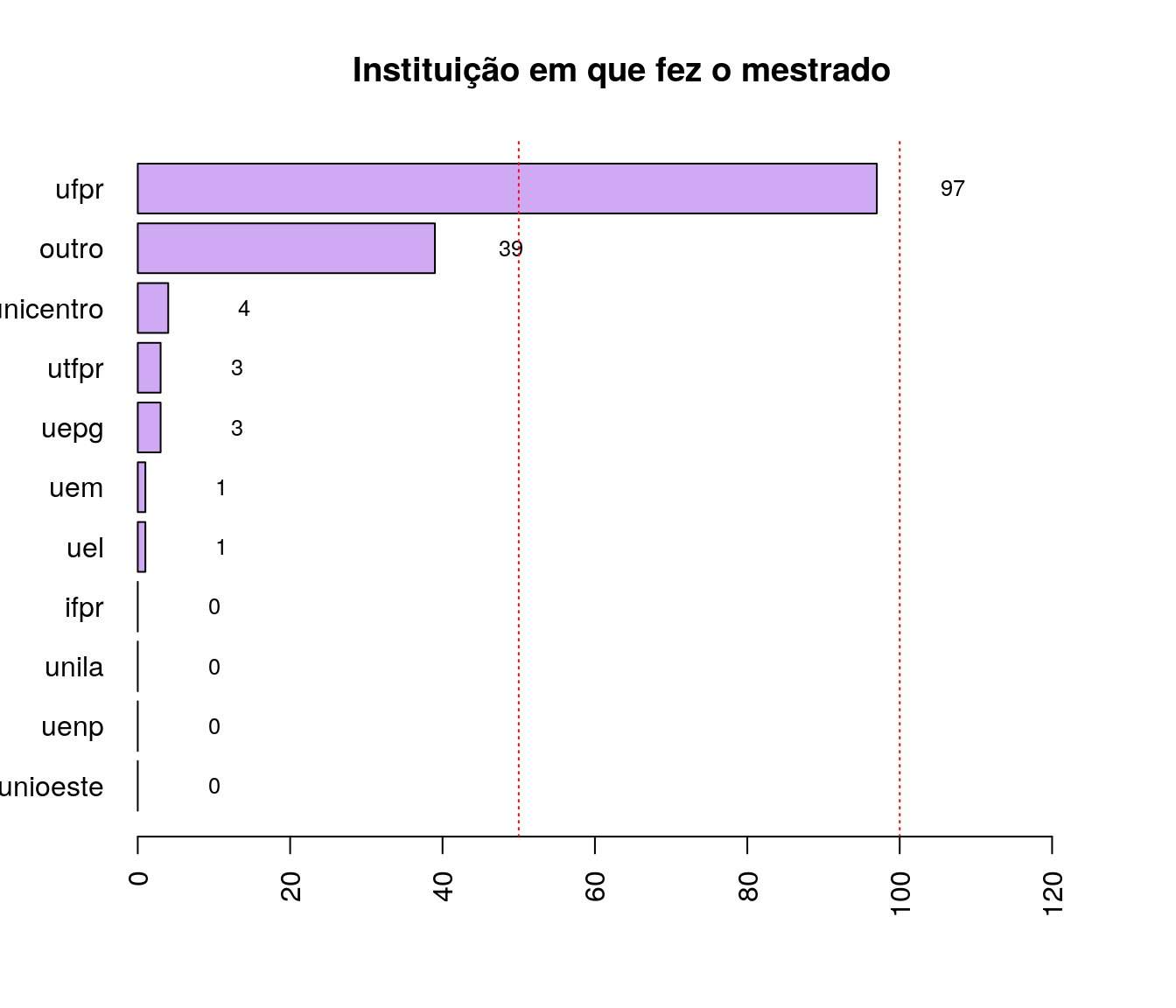
Quantos artigos (com qualis) você já publicou?
Tabela 1
quest$td_artigo <- as.integer(quest$td_artigo)
h <- hist(quest$td_artigo, plot = FALSE)
breaks <- h$breaks
classes <- cut(quest$td_artigo, breaks = breaks,
include.lowest = TRUE, right = TRUE)
tb.artigo <- as.data.frame(table(classes))
tb.artigo$Perc <- 100 * prop.table(tb.artigo$Freq)
names(tb.artigo)[1] <- "Quantidade Artigos"
pander:::pander(tb.artigo)| Quantidade Artigos | Freq | Perc |
|---|---|---|
| [0,10] | 725 | 96.41 |
| (10,20] | 15 | 1.995 |
| (20,30] | 4 | 0.5319 |
| (30,40] | 4 | 0.5319 |
| (40,50] | 1 | 0.133 |
| (50,60] | 1 | 0.133 |
| (60,70] | 0 | 0 |
| (70,80] | 0 | 0 |
| (80,90] | 0 | 0 |
| (90,100] | 2 | 0.266 |
Tabela 2
medidas <- data.frame(minimo = quantile(quest$td_artigo)[1],
quart1 = quantile(quest$td_artigo)[2],
media = mean(quest$td_artigo),
mediana = quantile(quest$td_artigo)[3],
moda = names(sort(table(quest$td_artigo),
decreasing = TRUE)[1]),
quart3 = quantile(quest$td_artigo)[4],
max = quantile(quest$td_artigo)[5])
row.names(medidas) <- NULL
pander(medidas)| minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|
| 0 | 0 | 2.443 | 1 | 0 | 2 | 97 |
disp <- data.frame(amplitude = diff(range(quest$td_artigo)),
variancia = var(quest$td_artigo),
desv_pad = sd(quest$td_artigo),
coef_var = 100*sd(quest$td_artigo)/mean(quest$td_artigo))
pander(disp)| amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|
| 97 | 46.49 | 6.819 | 279.1 |
Gráfico 1
plot(table(quest$td_artigo), t = "h", xlab = "Quantidade Artigos",
ylab = "Frequência", lwd = 6,
cex.axis = 0.8,
main = "Artigos (com Qualis) Publicados")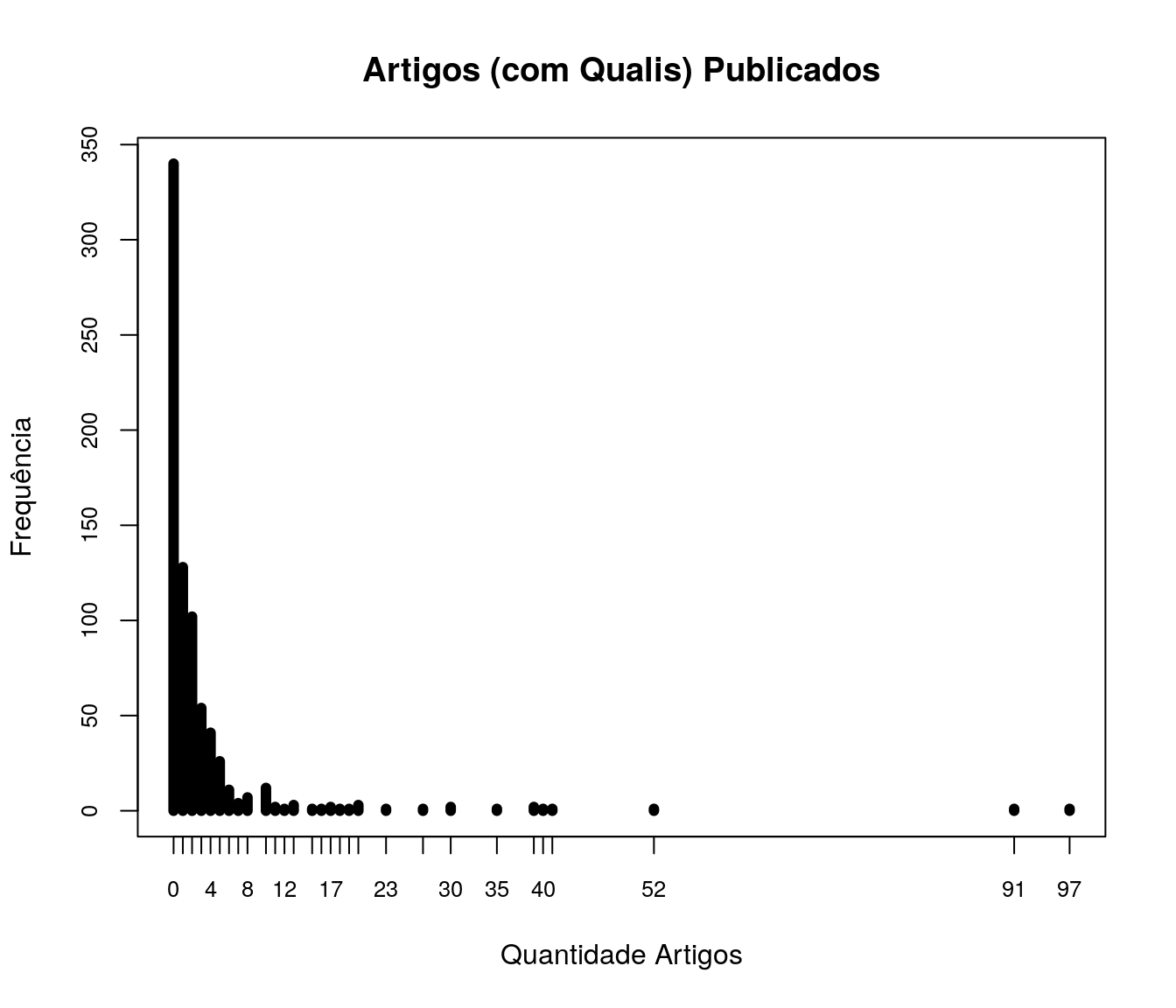
Gráfico 2
hist(quest$td_artigo, breaks = breaks, include.lowest = TRUE,
col = "#2EFE9A",
main = "Artigos Publicados", xlab = "Quant.", ylab = "Frequência")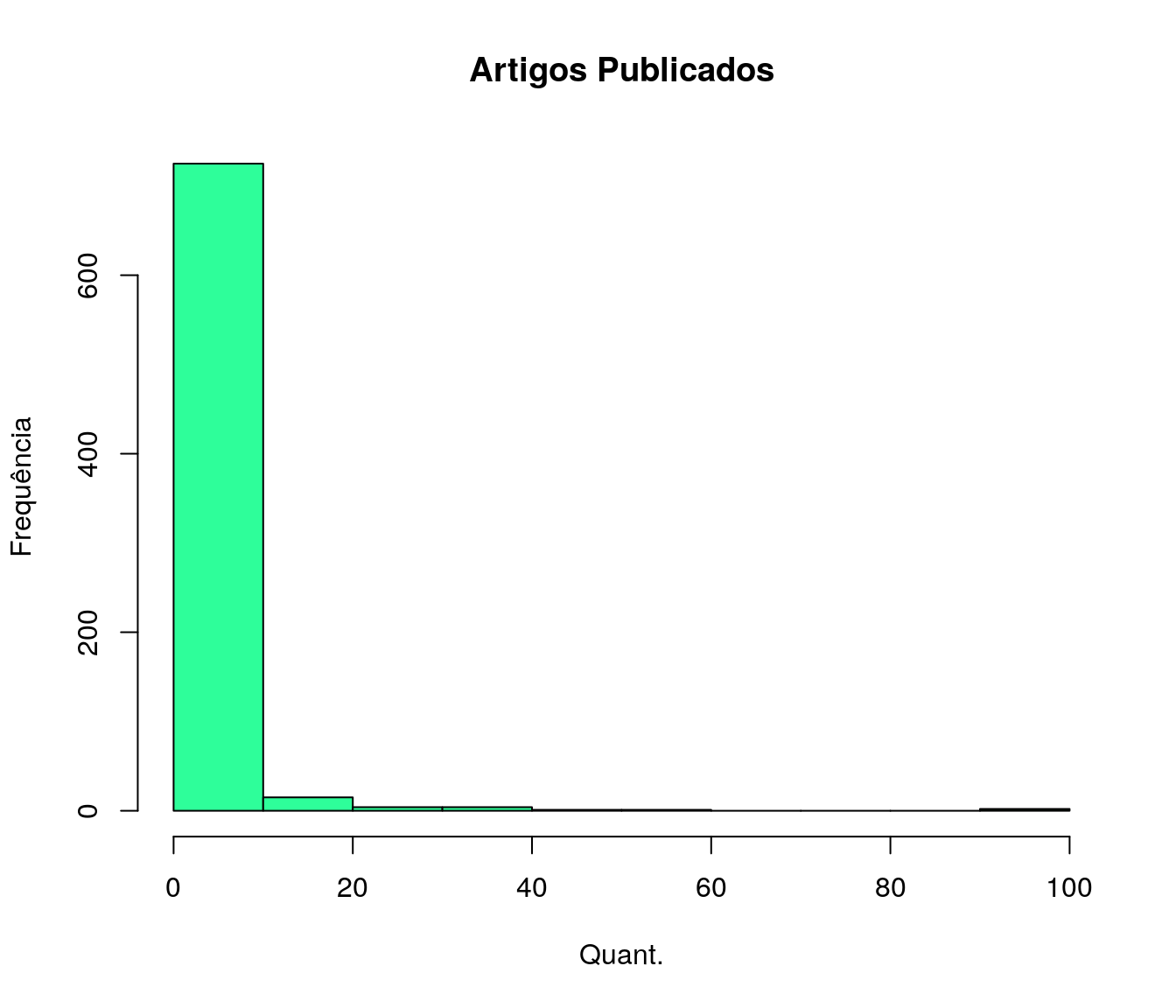
Gráfico 3
layout(mat = matrix(c(1,2),2,1, byrow=TRUE), height = c(3,1))
par(mar=c(3.1, 3.1, 1.1, 2.1))
hist(quest$td_artigo,col = "#2EFE9A", main = "Artigos publicados")
boxplot(quest$td_artigo, horizontal=TRUE,
outline=TRUE,
frame=F,
col = "#2EFE9A",
width = 10)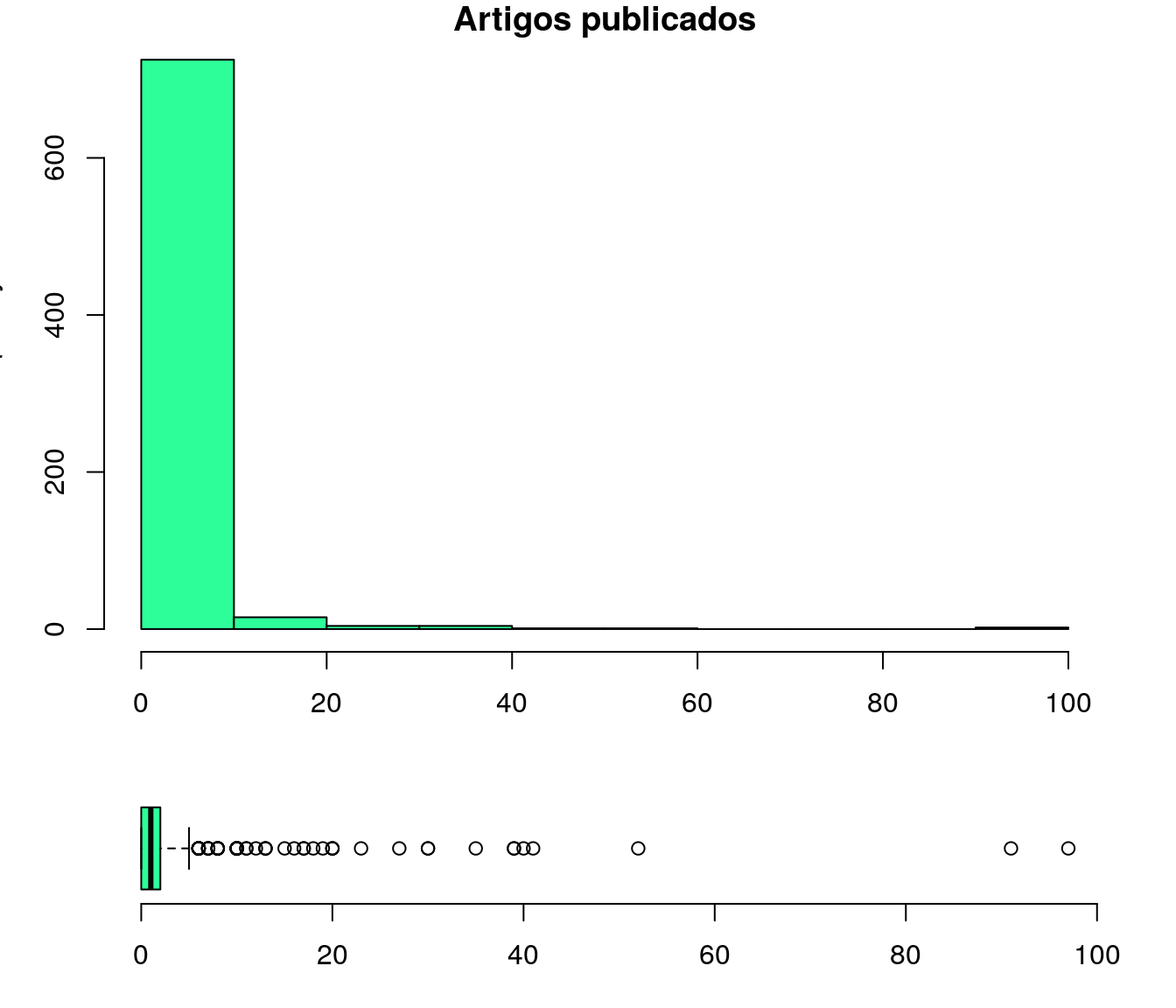
2019
antigo$td_artigo <- as.integer(antigo$td_artigo)
h <- hist(antigo$td_artigo, plot = FALSE)
breaks <- h$breaks
classes <- cut(antigo$td_artigo, breaks = breaks,
include.lowest = TRUE, right = TRUE)
tb.artigo <- as.data.frame(table(classes))
tb.artigo$Perc <- 100 * prop.table(tb.artigo$Freq)
names(tb.artigo)[1] <- "Quantidade Artigos"
#pander:::pander(tb.artigo)
layout(mat = matrix(c(1,2),2,1, byrow=TRUE), height = c(3,1))
par(mar=c(3.1, 3.1, 1.1, 2.1))
hist(antigo$td_artigo,col = "#2EFE9A", main = "Artigos publicados")
boxplot(antigo$td_artigo, horizontal=TRUE,
outline=TRUE,
frame=F,
col = "#2EFE9A",
width = 10)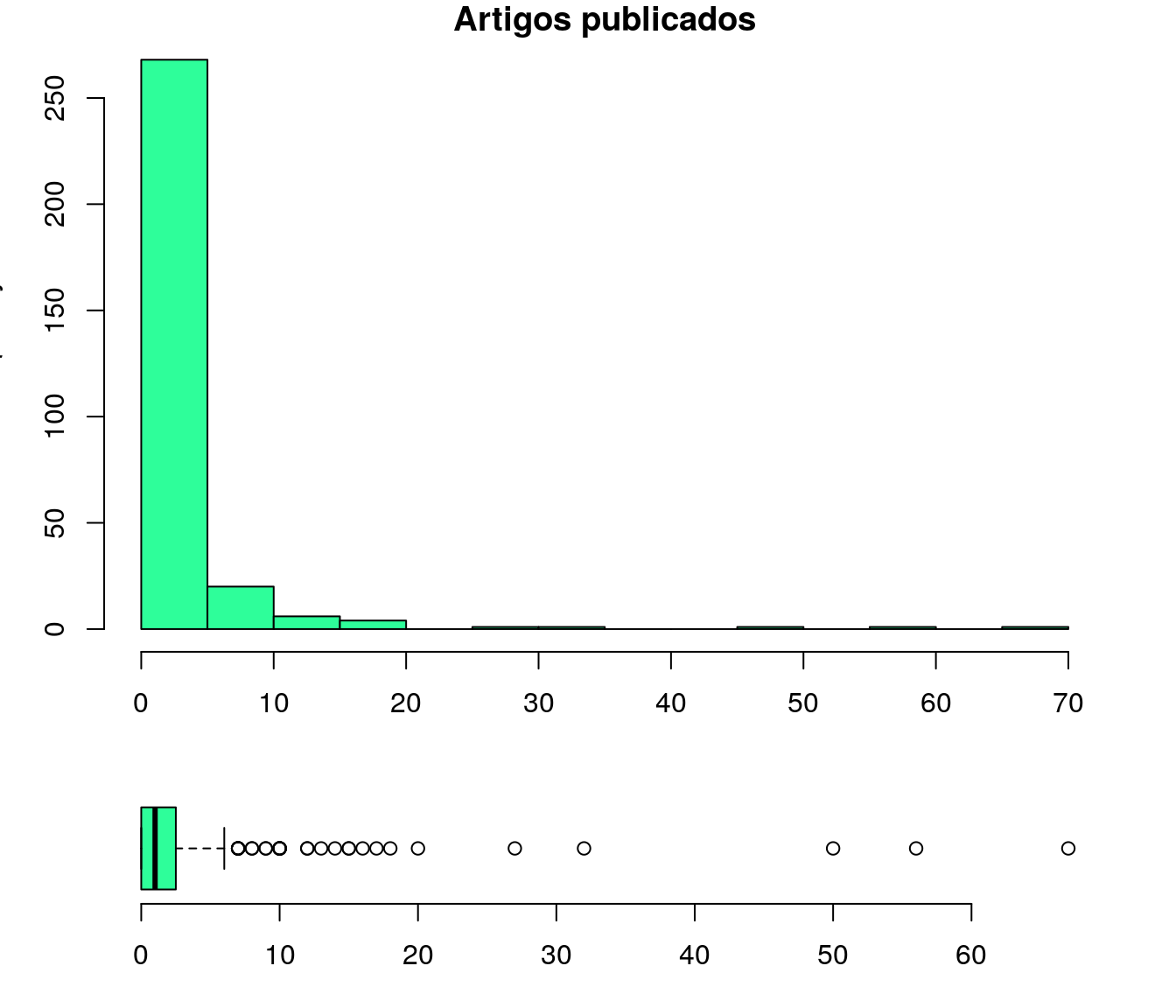
Você é bolsista remunerado de algum programa?
Tabela
quest$ln_bolsaEstudo <- tolower(iconv(quest$ln_bolsaEstudo,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- c("nao", "capes", "cnpq","lactec",
"simepar", "fundacao araucaria")
quest$ln_bolsaEstudo[ !quest$ln_bolsaEstudo %in% classOpcoes ] <- "outro"
quest$ln_bolsaEstudo <- factor(quest$ln_bolsaEstudo,
levels = c("nao", "capes", "cnpq","lactec",
"simepar", "fundacao araucaria",
"outro"))
fa_bolsa <- table(quest$ln_bolsaEstudo) # frequência absoluta
fr_bolsa <- prop.table(fa_bolsa) # frequência relativa
fac_bolsa <- cumsum(fr_bolsa) # frequência acumulada
bolsa <- data.frame(niveis = names(fa_bolsa),
freq = as.vector(fa_bolsa),
freq_r = as.vector(fr_bolsa),
freq_ac = as.vector(fac_bolsa)) # unindo as informações
pander:::pander(bolsa) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| nao | 431 | 0.5731 | 0.5731 |
| capes | 260 | 0.3457 | 0.9189 |
| cnpq | 40 | 0.05319 | 0.9721 |
| lactec | 2 | 0.00266 | 0.9747 |
| simepar | 0 | 0 | 0.9747 |
| fundacao araucaria | 2 | 0.00266 | 0.9774 |
| outro | 17 | 0.02261 | 1 |
Gráfico
bolsa_ord <- arrange(bolsa, bolsa$freq)
barplot(bolsa_ord$freq,
#names.arg = bolsa_ord$niveis,
col = paleta,
main = 'Bolsa de estudo',
ylab = 'Frequência',
xlab = '',
ylim = c(0, max(bolsa_ord$freq)+30)
#horiz = T,
#las=2,
)
legend("topleft",
legend = bolsa_ord$niveis,
fill = paleta,
cex = .8)
text(x = as.vector(barplot(bolsa_ord$freq, plot = FALSE)),
y = as.vector(bolsa_ord$freq) + 10,
labels = bolsa_ord$freq, cex = 1)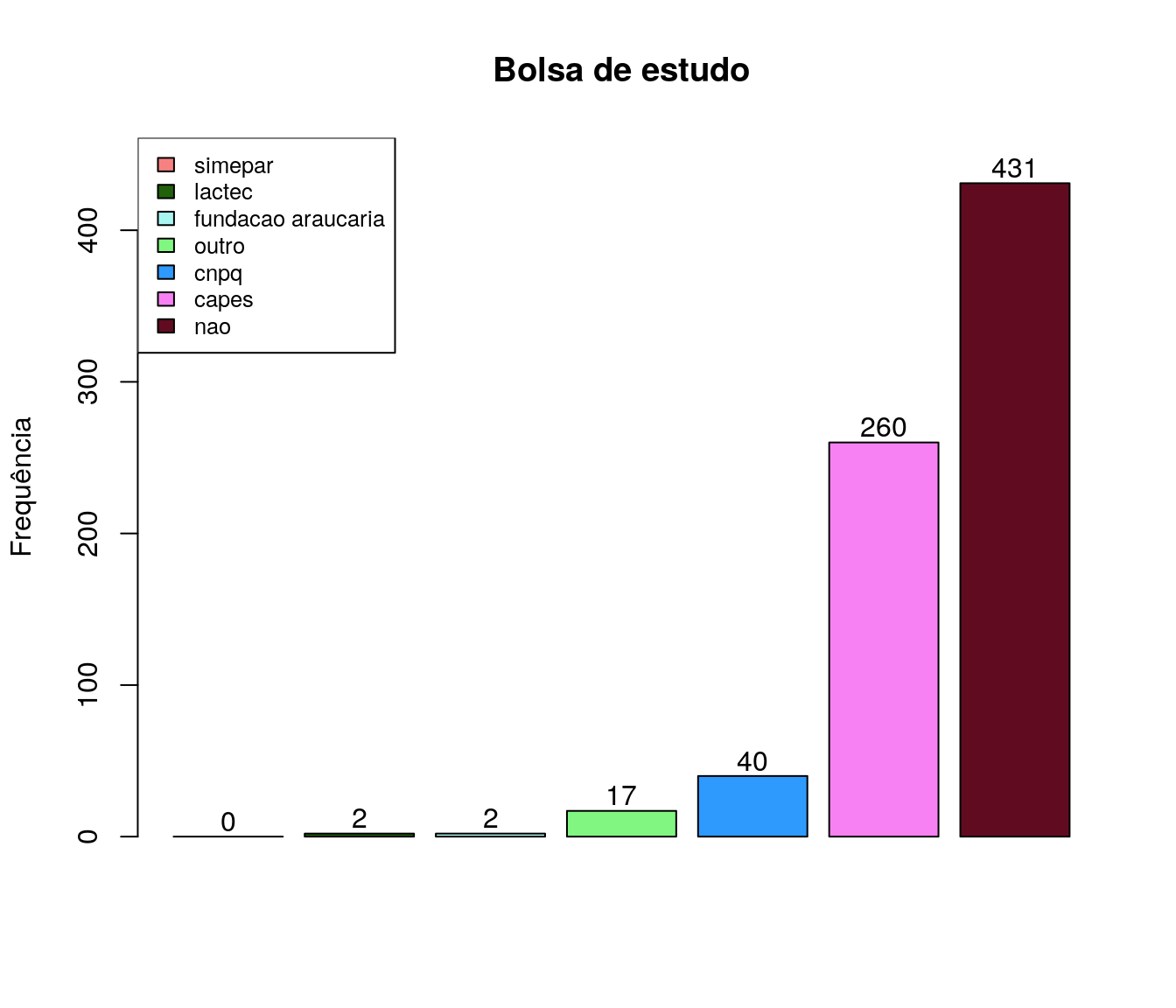
2019
antigo$ln_bolsaEstudo <- tolower(iconv(antigo$ln_bolsaEstudo,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- c("nao", "capes", "cnpq","lactec",
"simepar", "fundacao araucaria")
antigo$ln_bolsaEstudo[ !antigo$ln_bolsaEstudo %in% classOpcoes ] <- "outro"
antigo$ln_bolsaEstudo <- factor(antigo$ln_bolsaEstudo,
levels = c("nao", "capes", "cnpq","lactec",
"simepar", "fundacao araucaria",
"outro"))
fa_bolsa <- table(antigo$ln_bolsaEstudo) # frequência absoluta
fr_bolsa <- prop.table(fa_bolsa) # frequência relativa
fac_bolsa <- cumsum(fr_bolsa) # frequência acumulada
bolsa <- data.frame(niveis = names(fa_bolsa),
freq = as.vector(fa_bolsa),
freq_r = as.vector(fr_bolsa),
freq_ac = as.vector(fac_bolsa)) # unindo as informações
#pander:::pander(bolsa) # gerando a tabela
bolsa_ord <- arrange(bolsa, bolsa$freq)
barplot(bolsa_ord$freq,
#names.arg = bolsa_ord$niveis,
col = paleta,
main = 'Bolsa de estudo',
ylab = 'Frequência',
xlab = '',
ylim = c(0, max(bolsa_ord$freq)+30)
#horiz = T,
#las=2,
)
legend("topleft",
legend = bolsa_ord$niveis,
fill = paleta,
cex = .8)
text(x = as.vector(barplot(bolsa_ord$freq, plot = FALSE)),
y = as.vector(bolsa_ord$freq) + 10,
labels = bolsa_ord$freq, cex = 1)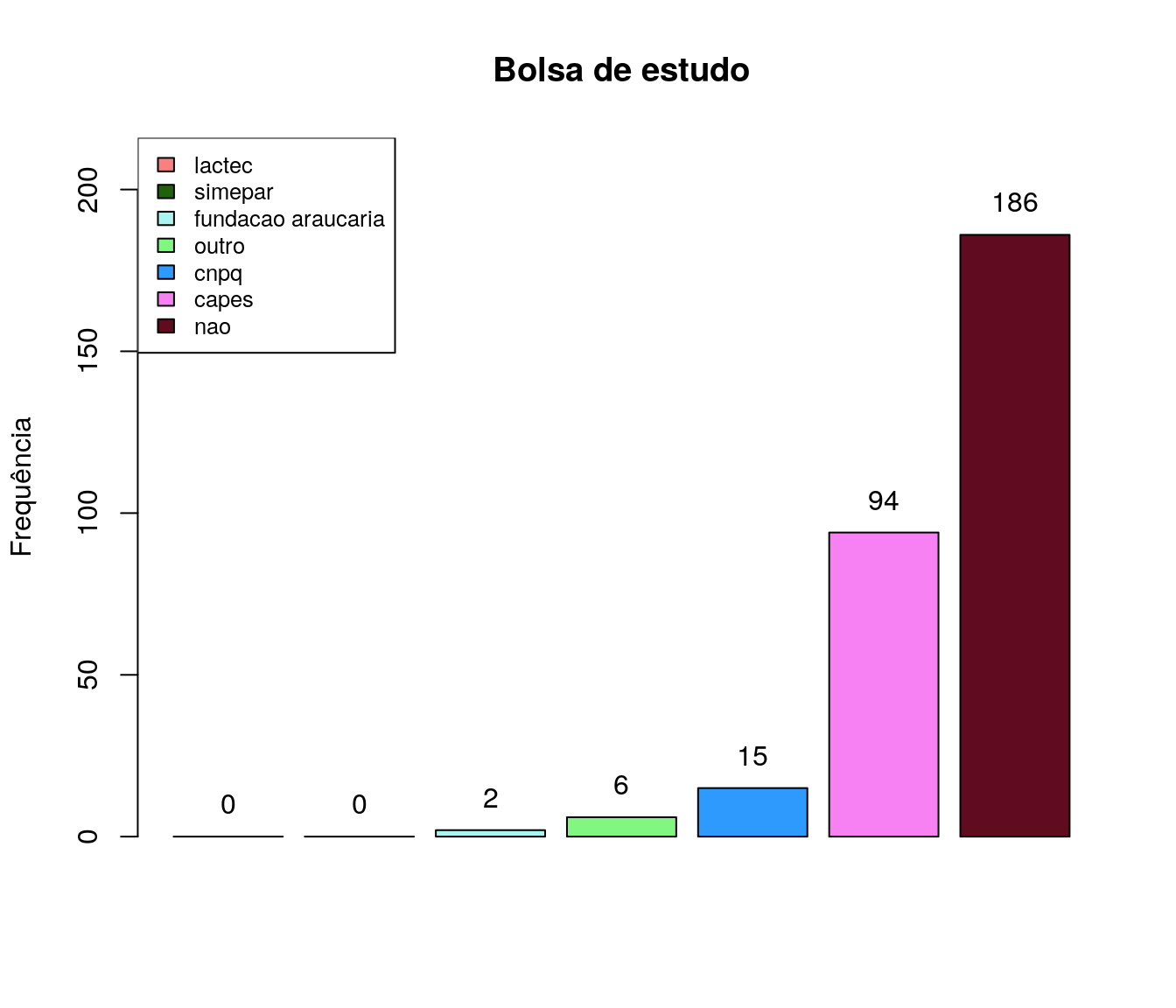
Quantas disciplinas de Estatística você cursou na graduação?
Tabela
quest$td_estatGrad <- as.integer(quest$td_estatGrad)
fa_estat <- table(quest$td_estatGrad) # frequência absoluta
fr_estat <- prop.table(fa_estat) # frequência relativa
fac_estat <- cumsum(fr_estat) # frequência acumulada
estat <- data.frame(niveis = names(fa_estat),
freq = as.vector(fa_estat),
freq_r = as.vector(fr_estat),
freq_ac = as.vector(fac_estat)) # unindo as informações
pander:::pander(estat) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| 0 | 138 | 0.1835 | 0.1835 |
| 1 | 466 | 0.6197 | 0.8032 |
| 2 | 127 | 0.1689 | 0.9721 |
| 3 | 10 | 0.0133 | 0.9854 |
| 4 | 6 | 0.007979 | 0.9934 |
| 5 | 1 | 0.00133 | 0.9947 |
| 10 | 1 | 0.00133 | 0.996 |
| 15 | 1 | 0.00133 | 0.9973 |
| 20 | 1 | 0.00133 | 0.9987 |
| 30 | 1 | 0.00133 | 1 |
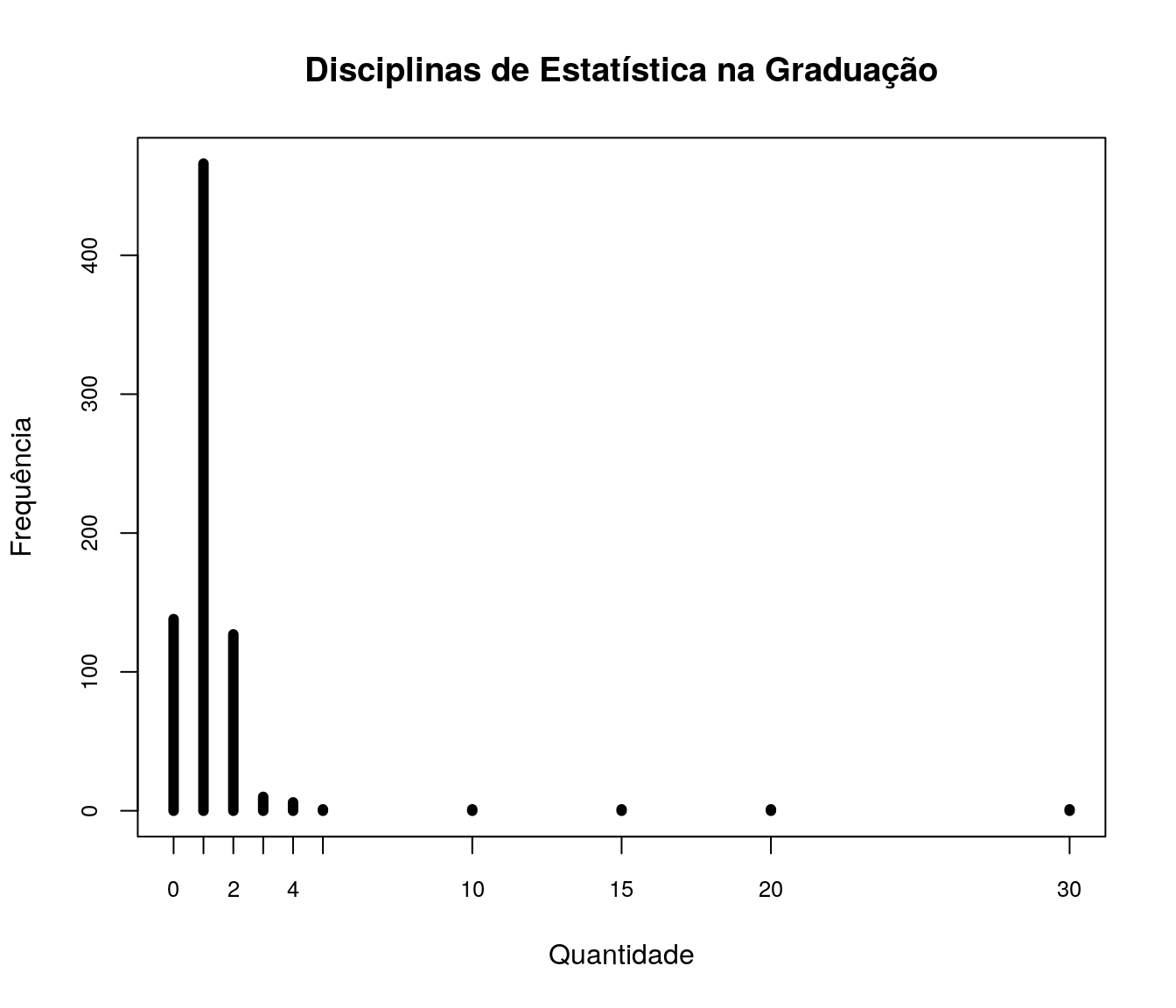
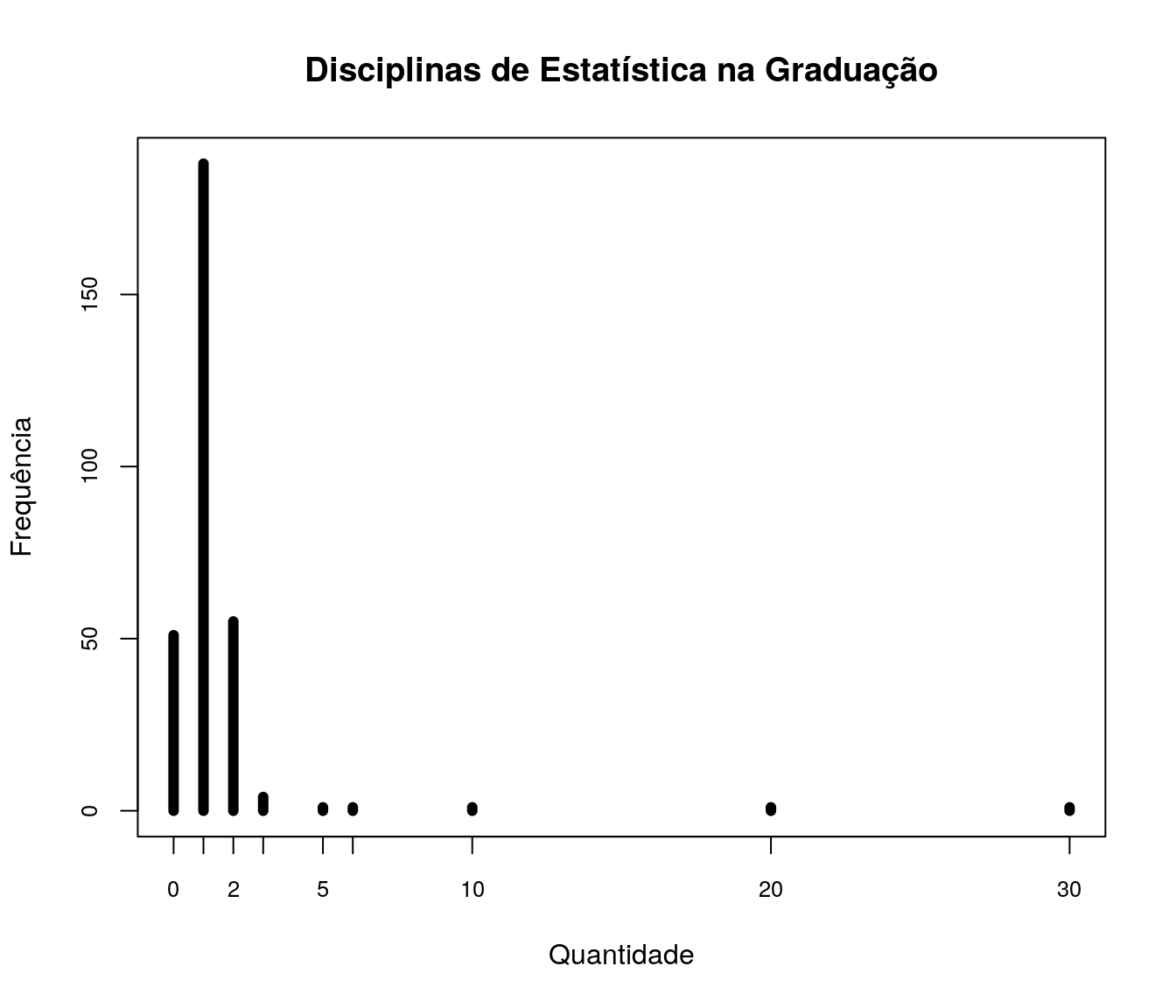
Quantas disciplinas diferentes de Estatística vc cursou na pós-graduação (mestrado + doutorado) no total?
Tabela 1
quest$td_estatPGrad <- as.integer(quest$td_estatPGrad)
fa_destat <- table(quest$td_estatPGrad) # frequência absoluta
fr_destat <- prop.table(fa_destat) # frequência relativa
fac_destat <- cumsum(fr_destat) # frequência acumulada
destat <- data.frame(niveis = names(fa_destat),
freq = as.vector(fa_destat),
freq_r = as.vector(fr_destat),
freq_ac = as.vector(fac_destat)) # unindo as informações
pander:::pander(destat) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| 0 | 319 | 0.4242 | 0.4242 |
| 1 | 114 | 0.1516 | 0.5758 |
| 2 | 68 | 0.09043 | 0.6662 |
| 3 | 24 | 0.03191 | 0.6981 |
| 4 | 20 | 0.0266 | 0.7247 |
| 5 | 27 | 0.0359 | 0.7606 |
| 6 | 24 | 0.03191 | 0.7926 |
| 7 | 21 | 0.02793 | 0.8205 |
| 8 | 32 | 0.04255 | 0.863 |
| 9 | 11 | 0.01463 | 0.8777 |
| 10 | 29 | 0.03856 | 0.9162 |
| 11 | 7 | 0.009309 | 0.9255 |
| 12 | 15 | 0.01995 | 0.9455 |
| 14 | 5 | 0.006649 | 0.9521 |
| 15 | 11 | 0.01463 | 0.9668 |
| 16 | 4 | 0.005319 | 0.9721 |
| 18 | 2 | 0.00266 | 0.9747 |
| 20 | 5 | 0.006649 | 0.9814 |
| 21 | 1 | 0.00133 | 0.9827 |
| 24 | 1 | 0.00133 | 0.984 |
| 25 | 1 | 0.00133 | 0.9854 |
| 27 | 2 | 0.00266 | 0.988 |
| 28 | 1 | 0.00133 | 0.9894 |
| 30 | 3 | 0.003989 | 0.9934 |
| 33 | 1 | 0.00133 | 0.9947 |
| 34 | 1 | 0.00133 | 0.996 |
| 37 | 1 | 0.00133 | 0.9973 |
| 50 | 1 | 0.00133 | 0.9987 |
| 94 | 1 | 0.00133 | 1 |
Gráfico 1
plot(table(quest$td_estatPGrad), t = "h", xlab = "Quantidade",
ylab = "Frequência", lwd = 6, cex.axis = 0.8,
main = "Disciplinas Estudadas na Pós-Graduação")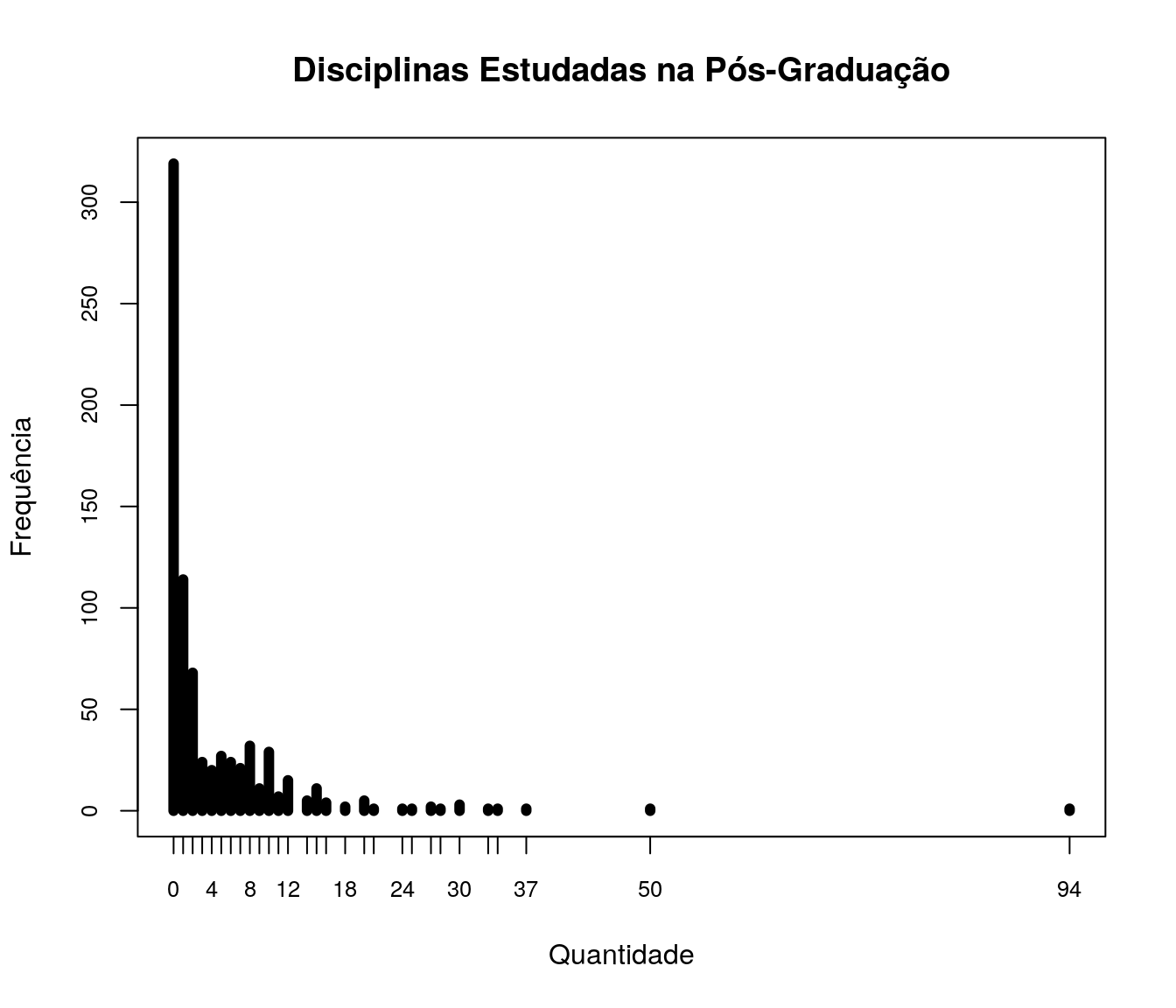
Gráfico 2
par(mfrow = c(2,1))
boxplot(quest$td_estatPGrad, horizontal=T,
col = "#A9D0F5", width = 1,
main = "Disciplinas Estudadas na Pós-Graduação")
boxplot(quest$td_estatPGrad,
horizontal=T, width = 1, col = "#A9D0F5")
stripchart(quest$td_estatPGrad,
vertical=F, add=T,
method="jitter",
pch=19, cex=0.5,
jitter=0.3)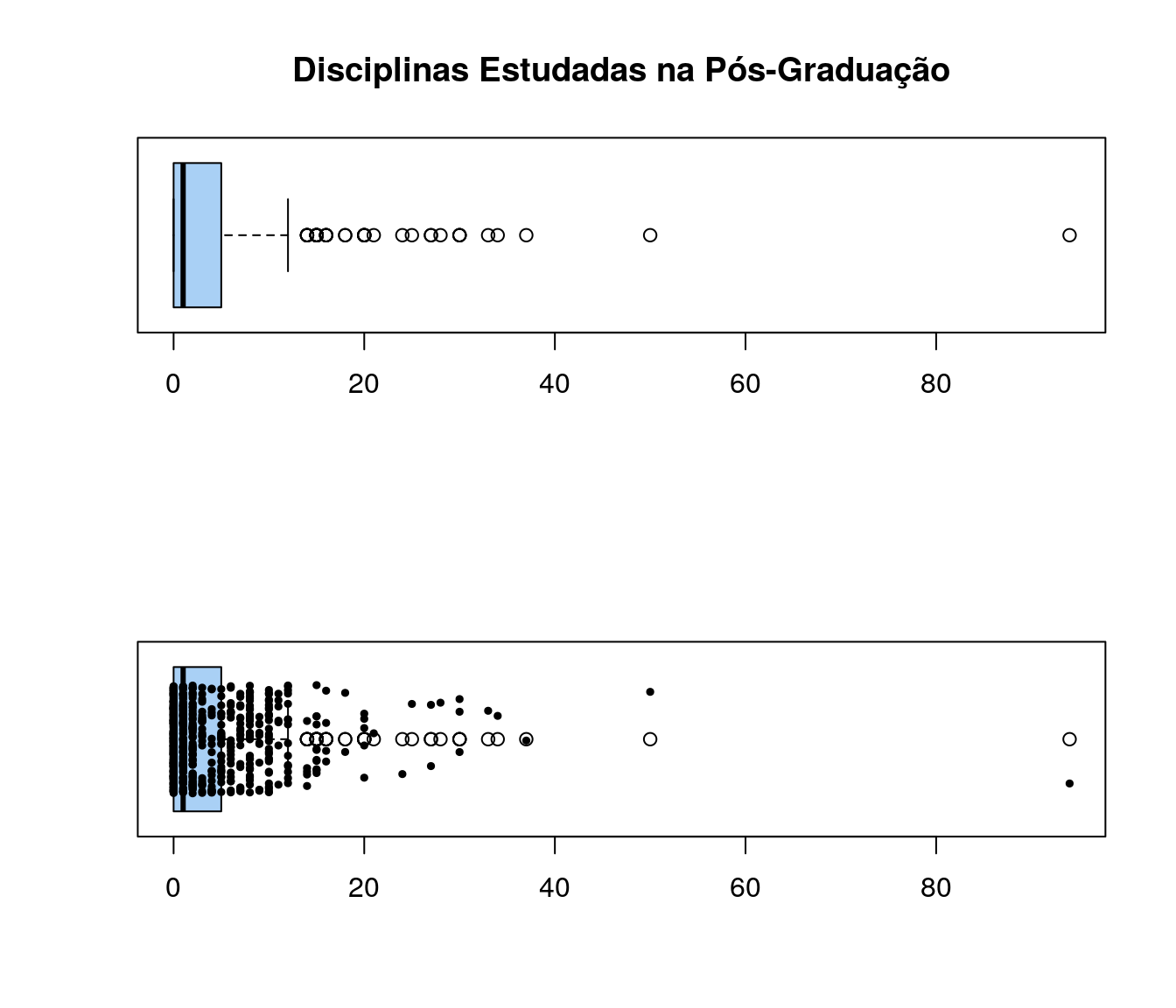
2019
par(mfrow = c(2,1))
boxplot(antigo$td_estatPGrad, horizontal=T,
col = "#A9D0F5", width = 1,
main = "Disciplinas Estudadas na Pós-Graduação")
boxplot(antigo$td_estatPGrad,
horizontal=T, width = 1, col = "#A9D0F5")
stripchart(antigo$td_estatPGrad,
vertical=F, add=T,
method="jitter",
pch=19, cex=0.5,
jitter=0.3)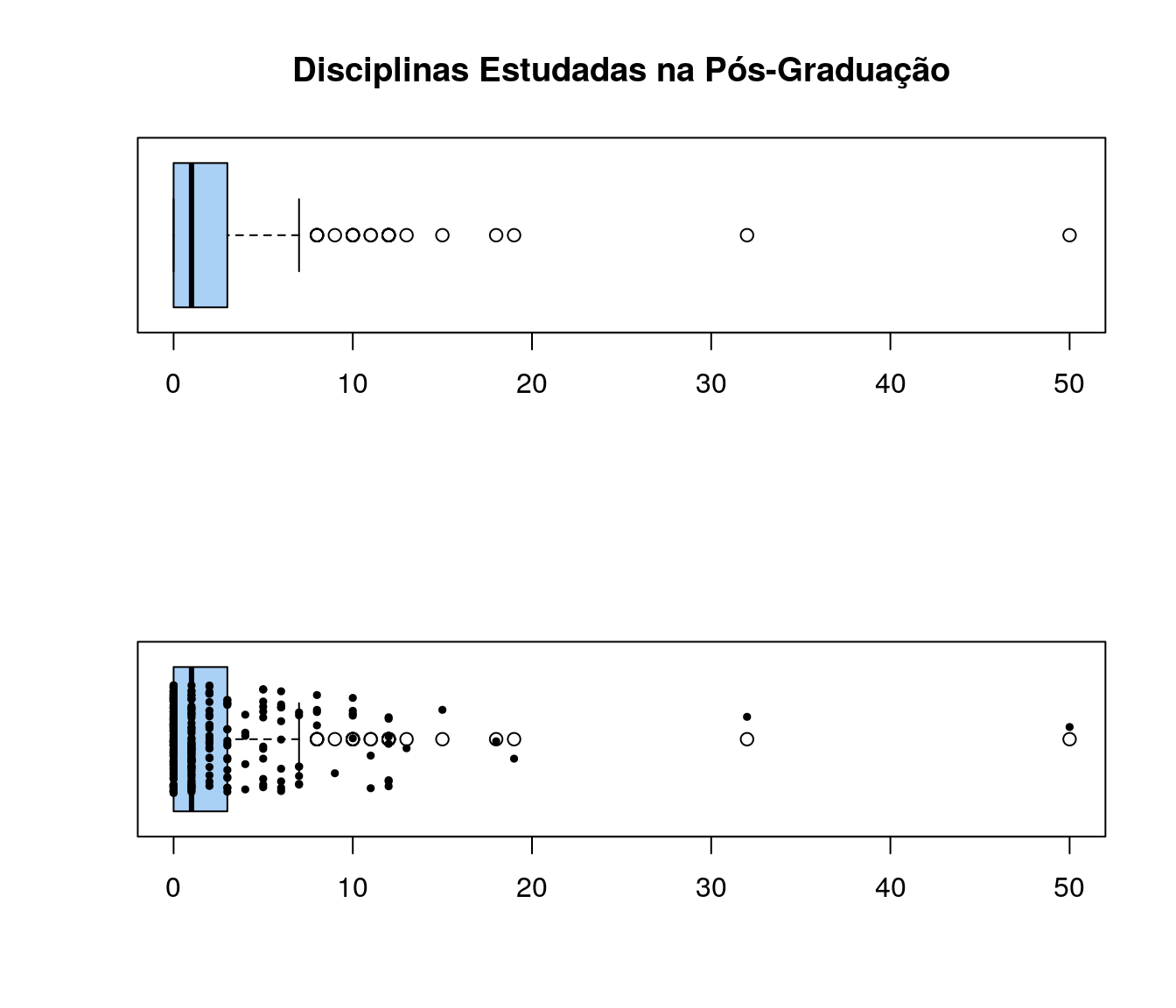
Já utilizou algum software com funcionalidades estatísticas?
Tabela
quest$lo_soft <- tolower(iconv(quest$lo_soft, to ='ASCII//TRANSLIT', from = "UTF-8"))
quest$lo_soft <- factor(quest$lo_soft, levels = c("sim", "nao"))
fa_soft <- table(quest$lo_soft) # frequência absoluta
fr_soft <- prop.table(fa_soft) # frequência relativa
fac_soft <- cumsum(fr_soft) # frequência acumulada
soft <- data.frame(niveis = names(fa_soft),
freq = as.vector(fa_soft),
freq_r = as.vector(fr_soft),
freq_ac = as.vector(fac_soft)) # unindo as informações
pander:::pander(soft) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| sim | 566 | 0.7527 | 0.7527 |
| nao | 186 | 0.2473 | 1 |
Gráfico
par(mfrow = c(1,2))
ar_color <- c("#81F7BE", "#F6E3CE")
pie(soft$freq, col = ar_color,
main = "Usou de Software \nEstatístico",
labels = percent(soft$freq_r))
legend("topleft", legend = soft$niveis, fill = ar_color, cex = 1)
barplot(soft$freq, col = ar_color,
main = "Uso de Software \nEstatístico",
names.arg = soft$niveis,
ylim = c(0, max(soft$freq + 20)))
text(x = as.vector(barplot(soft$freq, plot = FALSE)),
y = as.vector(soft$freq) + 10,
labels = soft$freq, cex = 1)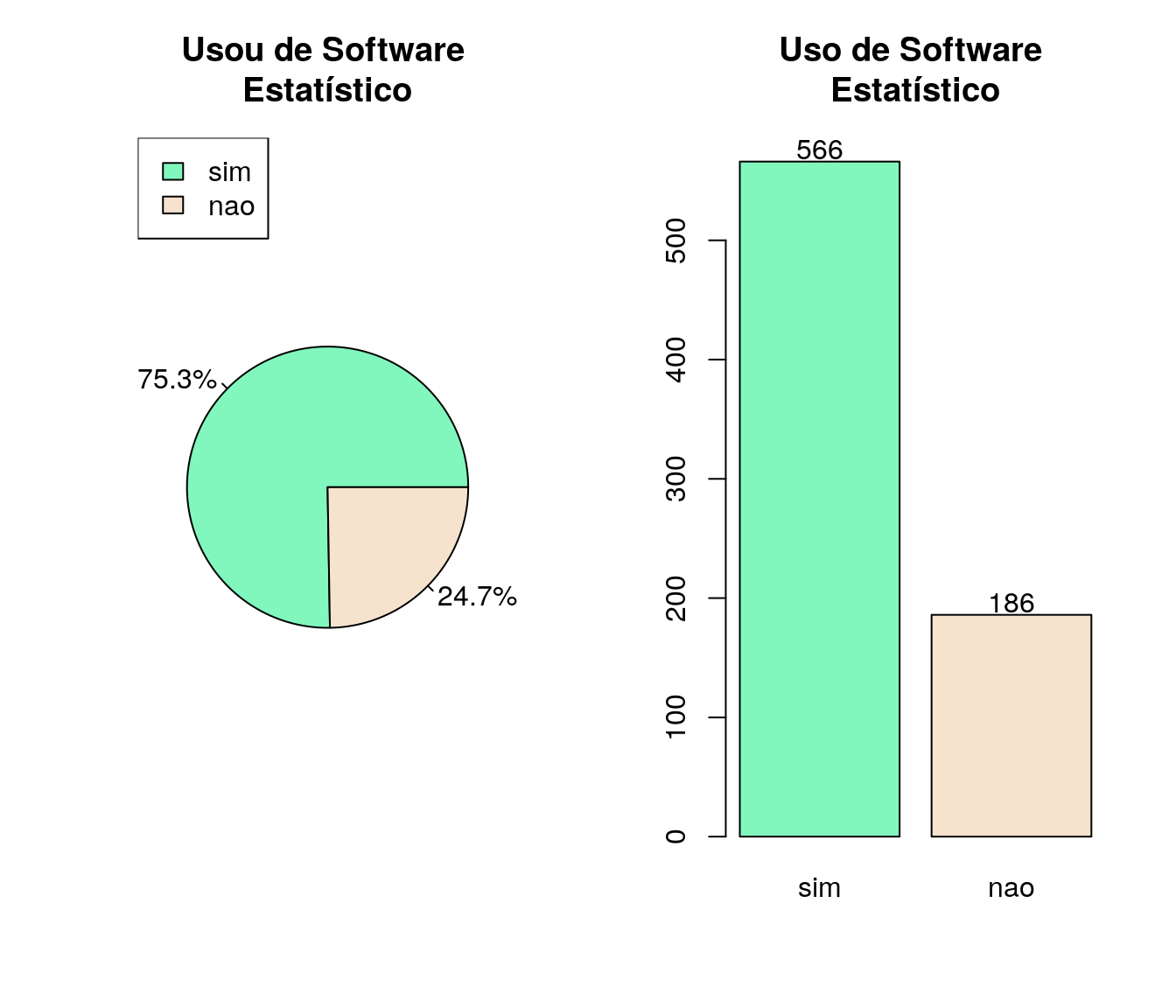
2019
antigo$lo_soft <- tolower(iconv(antigo$lo_soft, to ='ASCII//TRANSLIT', from = "UTF-8"))
antigo$lo_soft <- factor(antigo$lo_soft, levels = c("sim", "nao"))
fa_soft <- table(antigo$lo_soft) # frequência absoluta
fr_soft <- prop.table(fa_soft) # frequência relativa
fac_soft <- cumsum(fr_soft) # frequência acumulada
soft <- data.frame(niveis = names(fa_soft),
freq = as.vector(fa_soft),
freq_r = as.vector(fr_soft),
freq_ac = as.vector(fac_soft)) # unindo as informações
par(mfrow = c(1,2))
ar_color <- c("#81F7BE", "#F6E3CE")
pie(soft$freq, col = ar_color,
main = "Usou de Software \nEstatístico",
labels = percent(soft$freq_r))
legend("topleft", legend = soft$niveis, fill = ar_color, cex = 1)
barplot(soft$freq, col = ar_color,
main = "Uso de Software \nEstatístico",
names.arg = soft$niveis,
ylim = c(0, max(soft$freq + 20)))
text(x = as.vector(barplot(soft$freq, plot = FALSE)),
y = as.vector(soft$freq) + 10,
labels = soft$freq, cex = 1)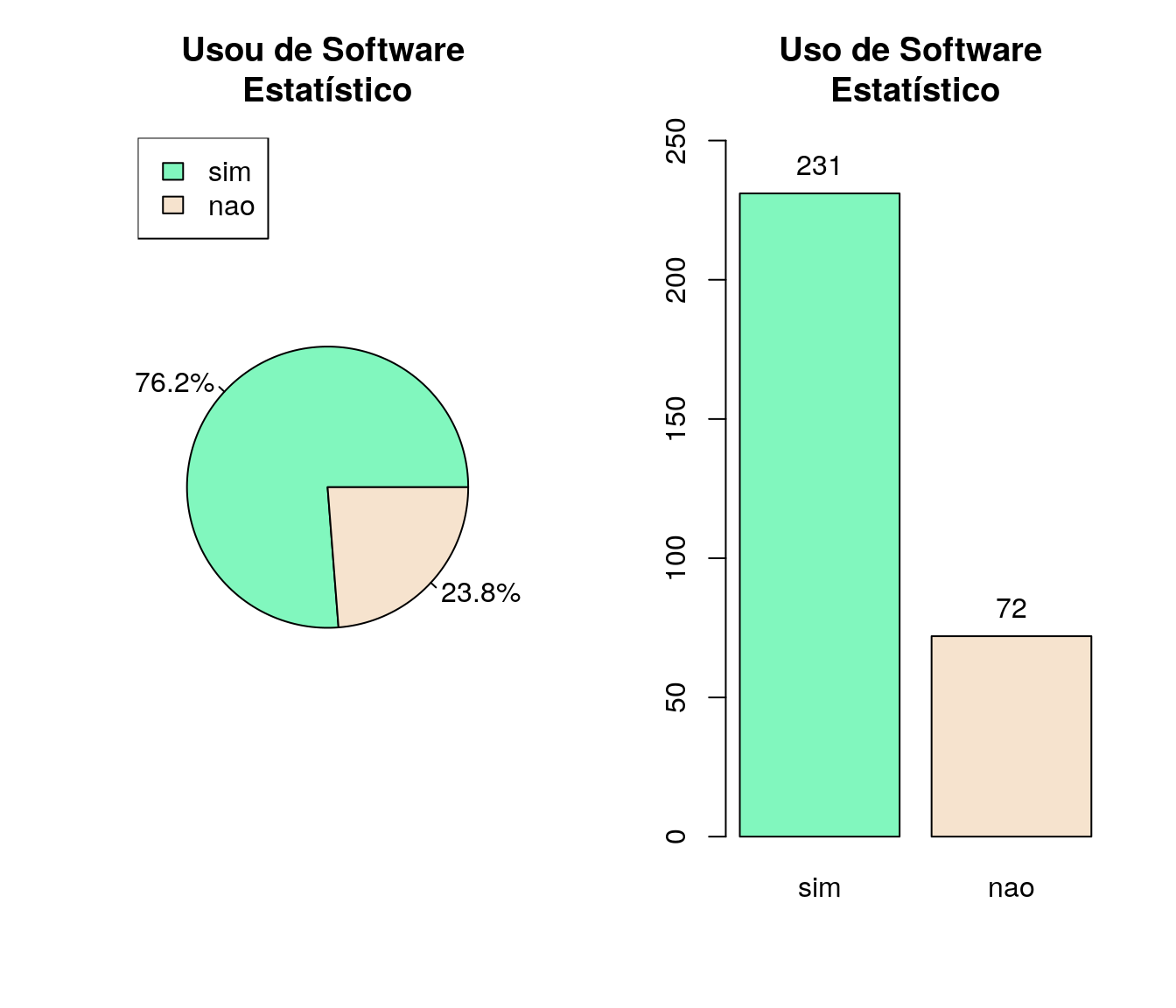
Qual(is) software(s) estatístico(s) você usa ou já usou?
Pergunta aplicada somente a quem já usou algum software estatístico. Na opção “Outros”, separe por ponto-e-vírgula.
Tabela
quest$ln_enumSoft <- tolower(iconv(quest$ln_enumSoft, to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$ln_enumSoft[ quest$ln_enumSoft %in% "statistica, sisvar e assistat" ] <- "statistica, sisvar, assistat"
quest$ln_enumSoft <- gsub(",",";",quest$ln_enumSoft)
ar_enumSoft<- cSplit(quest, "ln_enumSoft", sep = ";", direction = "long")$ln_enumSoft
ar_enumSoft <- as.character(ar_enumSoft)
classOpcoes <- c("nenhum", "nao usei", "nao utilizei", "nao", "nao se aplica", "0")
ar_enumSoft[ ar_enumSoft %in% classOpcoes ] <- "nao usou"
classOpcoes <- c("action", "action stat 3")
ar_enumSoft[ ar_enumSoft %in% classOpcoes ] <- "action stat"
classOpcoes <- c("epi-info")
ar_enumSoft[ ar_enumSoft %in% classOpcoes ] <- "epi info"
classOpcoes <- c("statigraphics")
ar_enumSoft[ ar_enumSoft %in% classOpcoes ] <- "statgraphics"
ar_enumSoft <- as.factor(ar_enumSoft)
fa_soft2 <- table(ar_enumSoft) # frequência absoluta
fr_soft2 <- prop.table(fa_soft2) # frequência relativa
fac_soft2 <- cumsum(fr_soft2) # frequência acumulada
soft2 <- data.frame(niveis = names(fa_soft2),
freq = as.vector(fa_soft2),
freq_r = as.vector(fr_soft2),
freq_ac = as.vector(fac_soft2)) # unindo as informações
pander:::pander(soft2) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| . | 1 | 0.0008525 | 0.0008525 |
| action stat | 4 | 0.00341 | 0.004263 |
| actionstat | 1 | 0.0008525 | 0.005115 |
| agreestat | 1 | 0.0008525 | 0.005968 |
| alguns softwares de sig. | 1 | 0.0008525 | 0.00682 |
| asistat | 1 | 0.0008525 | 0.007673 |
| assistat | 10 | 0.008525 | 0.0162 |
| assitat | 1 | 0.0008525 | 0.01705 |
| bioestat | 6 | 0.005115 | 0.02217 |
| bioestat5.0 | 1 | 0.0008525 | 0.02302 |
| biostat | 6 | 0.005115 | 0.02813 |
| epi info | 1 | 0.0008525 | 0.02899 |
| epiinfo | 1 | 0.0008525 | 0.02984 |
| excel | 472 | 0.4024 | 0.4322 |
| genes | 3 | 0.002558 | 0.4348 |
| geoda | 1 | 0.0008525 | 0.4356 |
| graphpad | 1 | 0.0008525 | 0.4365 |
| graphpad prism | 13 | 0.01108 | 0.4476 |
| graphpad prism 7 | 2 | 0.001705 | 0.4493 |
| graphpad prisma | 3 | 0.002558 | 0.4518 |
| graphprima | 1 | 0.0008525 | 0.4527 |
| jamovi | 2 | 0.001705 | 0.4544 |
| jmp | 3 | 0.002558 | 0.4569 |
| libreoffice calc | 1 | 0.0008525 | 0.4578 |
| maple | 1 | 0.0008525 | 0.4587 |
| matlab | 83 | 0.07076 | 0.5294 |
| microstrategy | 1 | 0.0008525 | 0.5303 |
| minitab | 56 | 0.04774 | 0.578 |
| mplus e amos | 1 | 0.0008525 | 0.5789 |
| numbers | 1 | 0.0008525 | 0.5797 |
| origin | 6 | 0.005115 | 0.5848 |
| origin 8.0 | 1 | 0.0008525 | 0.5857 |
| origin prolab | 1 | 0.0008525 | 0.5865 |
| pacotes e bibliotecas da plataforma anaconda da linguagem python | 1 | 0.0008525 | 0.5874 |
| pass | 1 | 0.0008525 | 0.5882 |
| past | 7 | 0.005968 | 0.5942 |
| phayton | 1 | 0.0008525 | 0.5951 |
| power bi | 1 | 0.0008525 | 0.5959 |
| prim | 1 | 0.0008525 | 0.5968 |
| prism | 6 | 0.005115 | 0.6019 |
| prisma | 7 | 0.005968 | 0.6078 |
| python | 2 | 0.001705 | 0.6095 |
| qgis | 2 | 0.001705 | 0.6113 |
| qlik | 1 | 0.0008525 | 0.6121 |
| r | 158 | 0.1347 | 0.7468 |
| rbio | 1 | 0.0008525 | 0.7477 |
| saeg | 1 | 0.0008525 | 0.7485 |
| sas | 39 | 0.03325 | 0.7818 |
| scilab | 1 | 0.0008525 | 0.7826 |
| sigma plot | 3 | 0.002558 | 0.7852 |
| sigmaplot | 3 | 0.002558 | 0.7877 |
| sisvar | 15 | 0.01279 | 0.8005 |
| sofa | 1 | 0.0008525 | 0.8014 |
| sphinks | 1 | 0.0008525 | 0.8022 |
| sphinx | 1 | 0.0008525 | 0.8031 |
| spss | 124 | 0.1057 | 0.9088 |
| stata | 2 | 0.001705 | 0.9105 |
| statgraphics | 2 | 0.001705 | 0.9122 |
| statistica | 92 | 0.07843 | 0.9906 |
| systat | 5 | 0.004263 | 0.9949 |
| tableau | 1 | 0.0008525 | 0.9957 |
| unscrambler | 1 | 0.0008525 | 0.9966 |
| winstat | 2 | 0.001705 | 0.9983 |
| xlstat | 2 | 0.001705 | 1 |
Gráfico
soft21 <- arrange(soft2, desc(soft2$freq))
barplot(soft21$freq[1:15], horiz = TRUE,
names.arg = soft21$niveis[1:15],
col = rainbow(length(unique(soft21$niveis))),
main = "15 Softwares Estatísticos mais Usados",
xlim = c(0, max(soft21$freq + 30)),
cex.names=0.8, las = 2)
abline(v=50, lty=3, col = 2)
abline(v=100, lty=3, col = 2)
abline(v=150, lty=3, col = 2)
abline(v=200, lty=3, col = 2)
abline(v=250, lty=3, col = 2)
abline(v=300, lty=3, col = 2)
abline(v=350, lty=3, col = 2)
abline(v=400, lty=3, col = 2)
abline(v=450, lty=3, col = 2)
abline(v=500, lty=3, col = 2)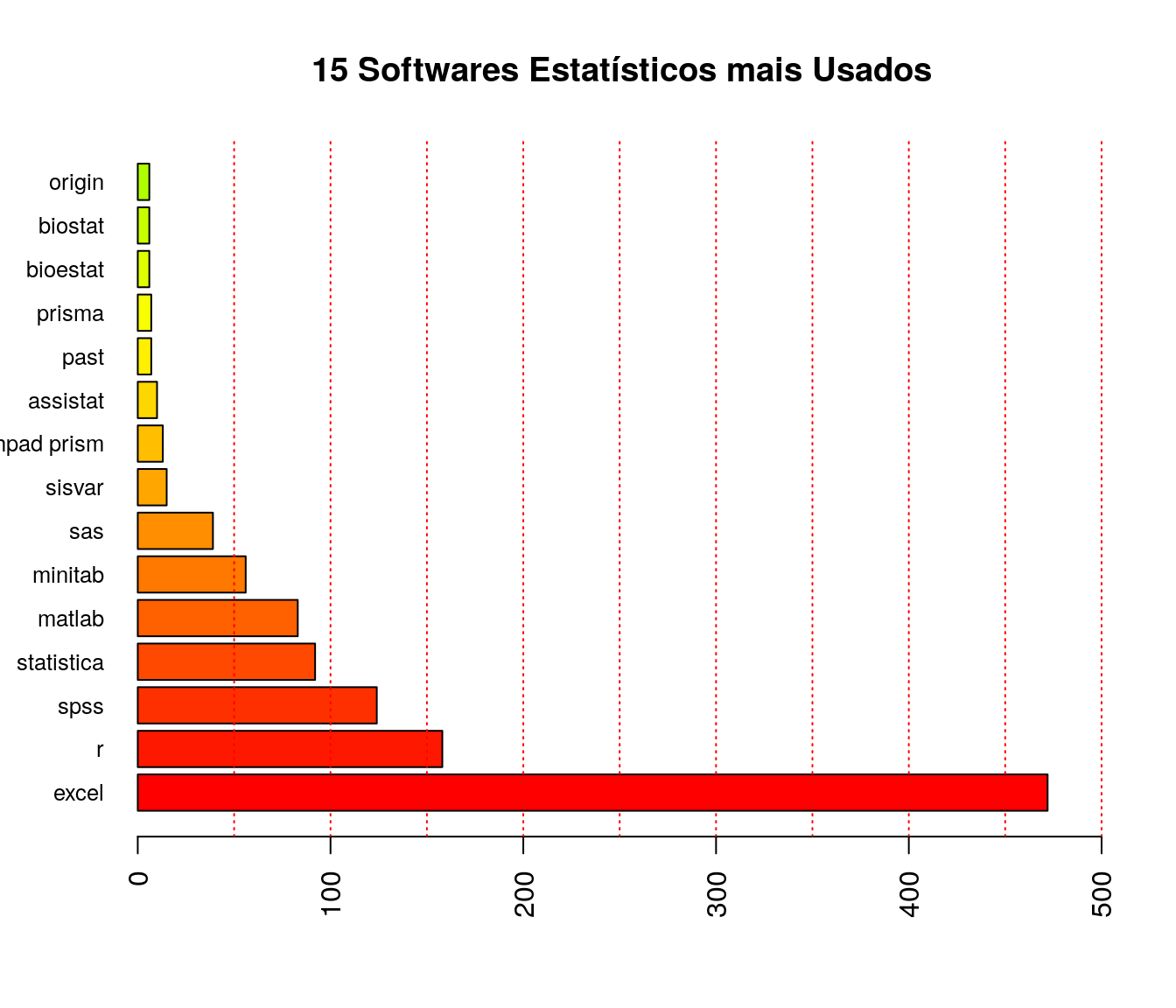
2019
antigo$ln_enumSoft <- tolower(iconv(antigo$ln_enumSoft, to ='ASCII//TRANSLIT',
from = "UTF-8"))
antigo$ln_enumSoft[ antigo$ln_enumSoft %in% "statistica, sisvar e assistat" ] <- "statistica, sisvar, assistat"
antigo$ln_enumSoft <- gsub(",",";",antigo$ln_enumSoft)
ar_enumSoft<- cSplit(antigo, "ln_enumSoft", sep = ";", direction = "long")$ln_enumSoft
ar_enumSoft <- as.character(ar_enumSoft)
classOpcoes <- c("nenhum", "nao usei", "nao utilizei", "nao", "nao se aplica", "0")
ar_enumSoft[ ar_enumSoft %in% classOpcoes ] <- "nao usou"
classOpcoes <- c("action", "action stat 3")
ar_enumSoft[ ar_enumSoft %in% classOpcoes ] <- "action stat"
classOpcoes <- c("epi-info")
ar_enumSoft[ ar_enumSoft %in% classOpcoes ] <- "epi info"
classOpcoes <- c("statigraphics")
ar_enumSoft[ ar_enumSoft %in% classOpcoes ] <- "statgraphics"
ar_enumSoft <- as.factor(ar_enumSoft)
fa_soft2 <- table(ar_enumSoft) # frequência absoluta
fr_soft2 <- prop.table(fa_soft2) # frequência relativa
fac_soft2 <- cumsum(fr_soft2) # frequência acumulada
soft2 <- data.frame(niveis = names(fa_soft2),
freq = as.vector(fa_soft2),
freq_r = as.vector(fr_soft2),
freq_ac = as.vector(fac_soft2)) # unindo as informações
# pander:::pander(soft2) # gerando a tabela
soft21 <- arrange(soft2, desc(soft2$freq))
barplot(soft21$freq[1:15], horiz = TRUE,
names.arg = soft21$niveis[1:15],
col = rainbow(length(unique(soft21$niveis))),
main = "15 Softwares Estatísticos Usados",
xlim = c(0, max(soft21$freq + 30)),
cex.names=0.8, las = 2)
abline(v=50, lty=3, col = 2)
abline(v=100, lty=3, col = 2)
abline(v=150, lty=3, col = 2)
abline(v=200, lty=3, col = 2)
abline(v=250, lty=3, col = 2)
abline(v=300, lty=3, col = 2)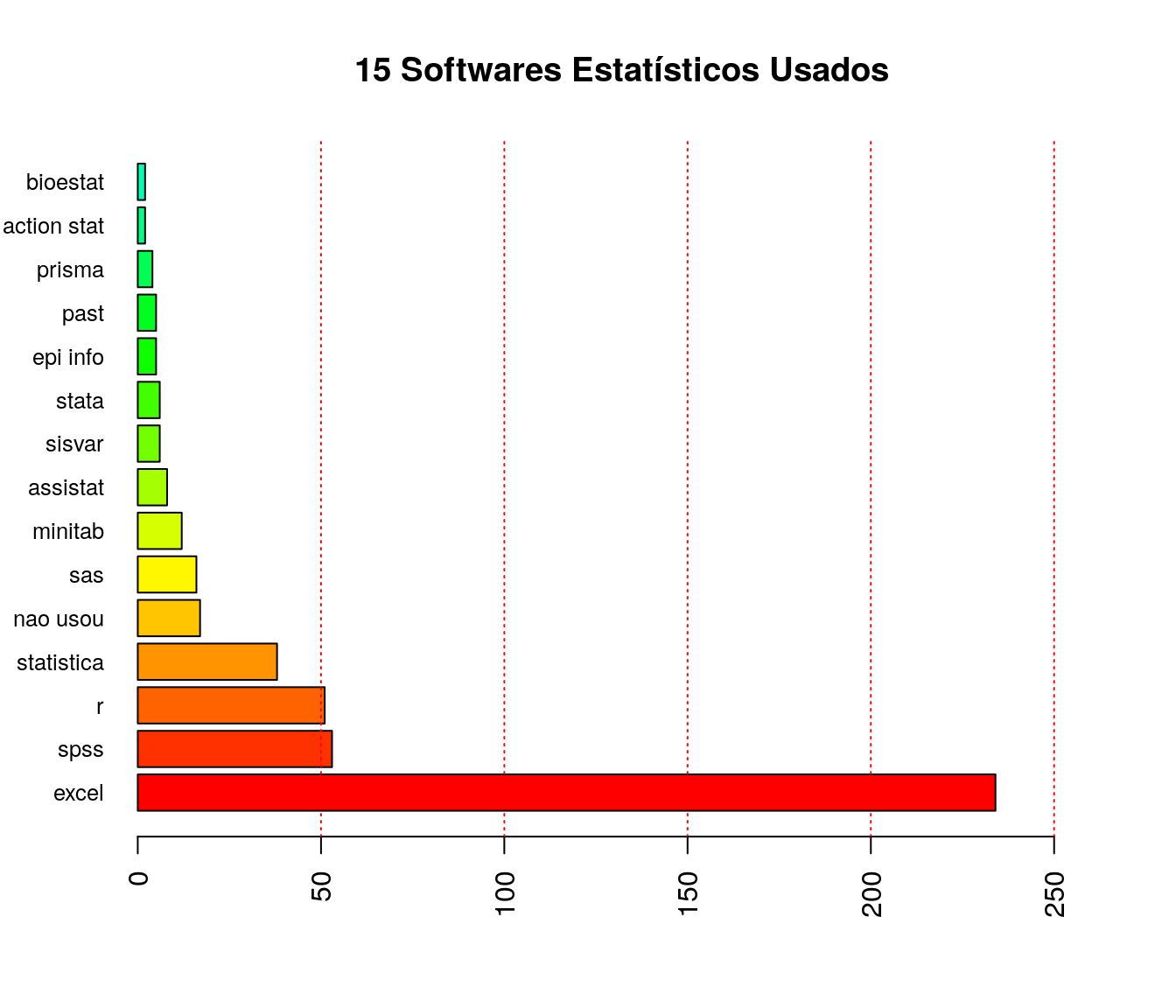
Você vai utilizar métodos estatísticos na sua Pós-Graduação/Pesquisa?
Tabela
quest$lo_importancia <- tolower(iconv(quest$lo_importancia,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$lo_importancia <- factor(quest$lo_importancia,
levels = c("certamente sim", "nao sei ainda",
"definitivamente nao"))
fa_uso <- table(quest$lo_importancia) # frequência absoluta
fr_uso <- prop.table(fa_uso) # frequência relativa
fac_uso <- cumsum(fr_uso) # frequência acumulada
uso <- data.frame(niveis = names(fa_uso),
freq = as.vector(fa_uso),
freq_r = as.vector(fr_uso),
freq_ac = as.vector(fac_uso)) # unindo as informações
pander:::pander(uso) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| certamente sim | 645 | 0.8577 | 0.8577 |
| nao sei ainda | 101 | 0.1343 | 0.992 |
| definitivamente nao | 6 | 0.007979 | 1 |
Gráfico
uso <- arrange(uso, uso$freq)
bp <-
barplot(uso$freq,
#horiz = TRUE,
names.arg = uso$niveis,
col = '#F5A9A9',
ylim = c(0, max(uso$freq + 40)),
cex.names=1,
main = 'Usará métodos estatísticos no trabalho',
#, las = 2
)
text(x = c(bp),
y = uso$freq,
labels = uso$freq,
pos = 3)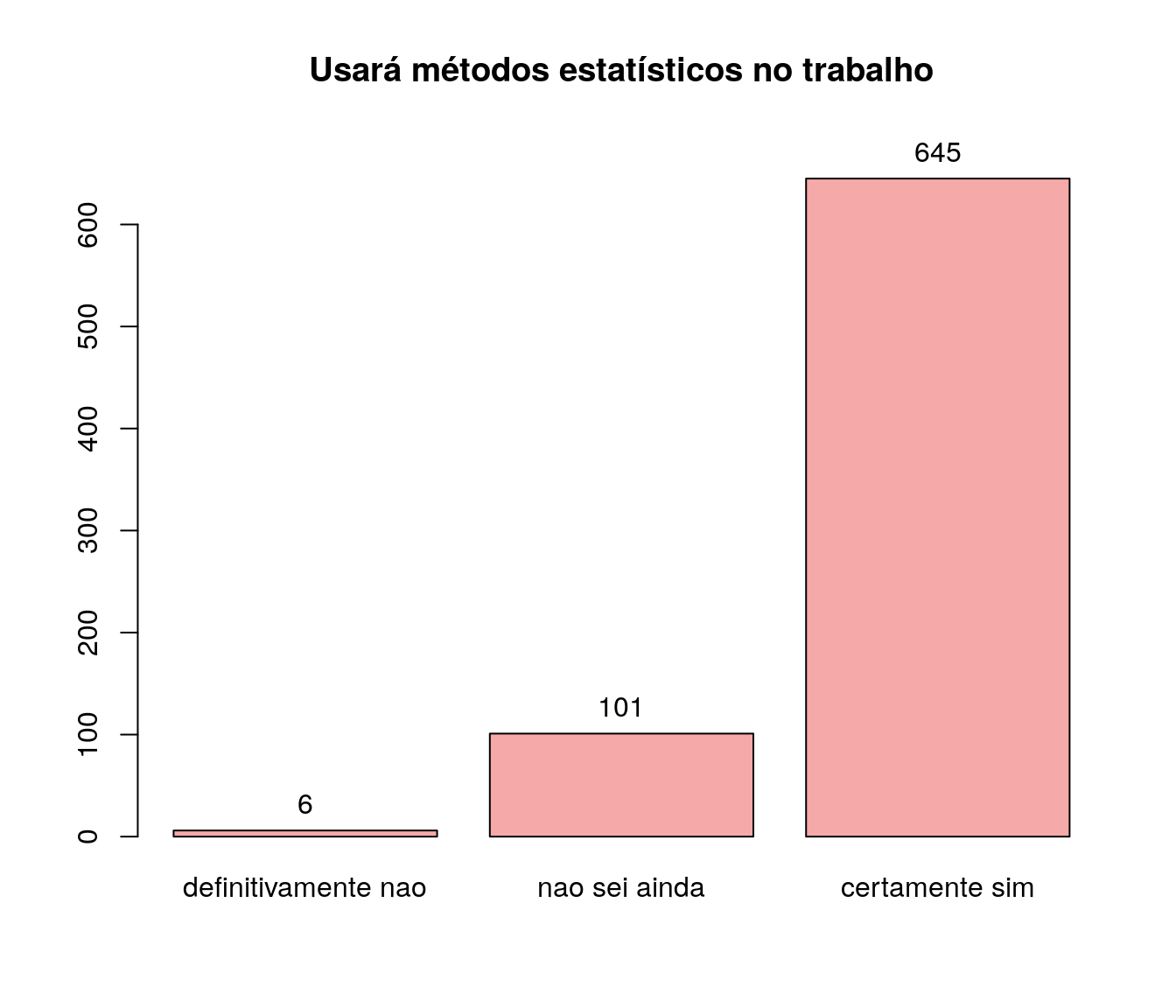
2019
antigo$lo_importancia <- tolower(iconv(antigo$lo_importancia,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
antigo$lo_importancia <- factor(antigo$lo_importancia,
levels = c("certamente sim", "nao sei ainda",
"definitivamente nao"))
fa_uso <- table(antigo$lo_importancia) # frequência absoluta
fr_uso <- prop.table(fa_uso) # frequência relativa
fac_uso <- cumsum(fr_uso) # frequência acumulada
uso <- data.frame(niveis = names(fa_uso),
freq = as.vector(fa_uso),
freq_r = as.vector(fr_uso),
freq_ac = as.vector(fac_uso)) # unindo as informações
#pander:::pander(uso) # gerando a tabela
uso <- arrange(uso, uso$freq)
bp <-
barplot(uso$freq,
#horiz = TRUE,
names.arg = uso$niveis,
col = '#F5A9A9',
ylim = c(0, max(uso$freq + 20)),
cex.names=1,
main = 'Usará métodos estatísticos no trabalho',
#, las = 2
)
text(x = c(bp),
y = uso$freq,
labels = uso$freq,
pos = 3)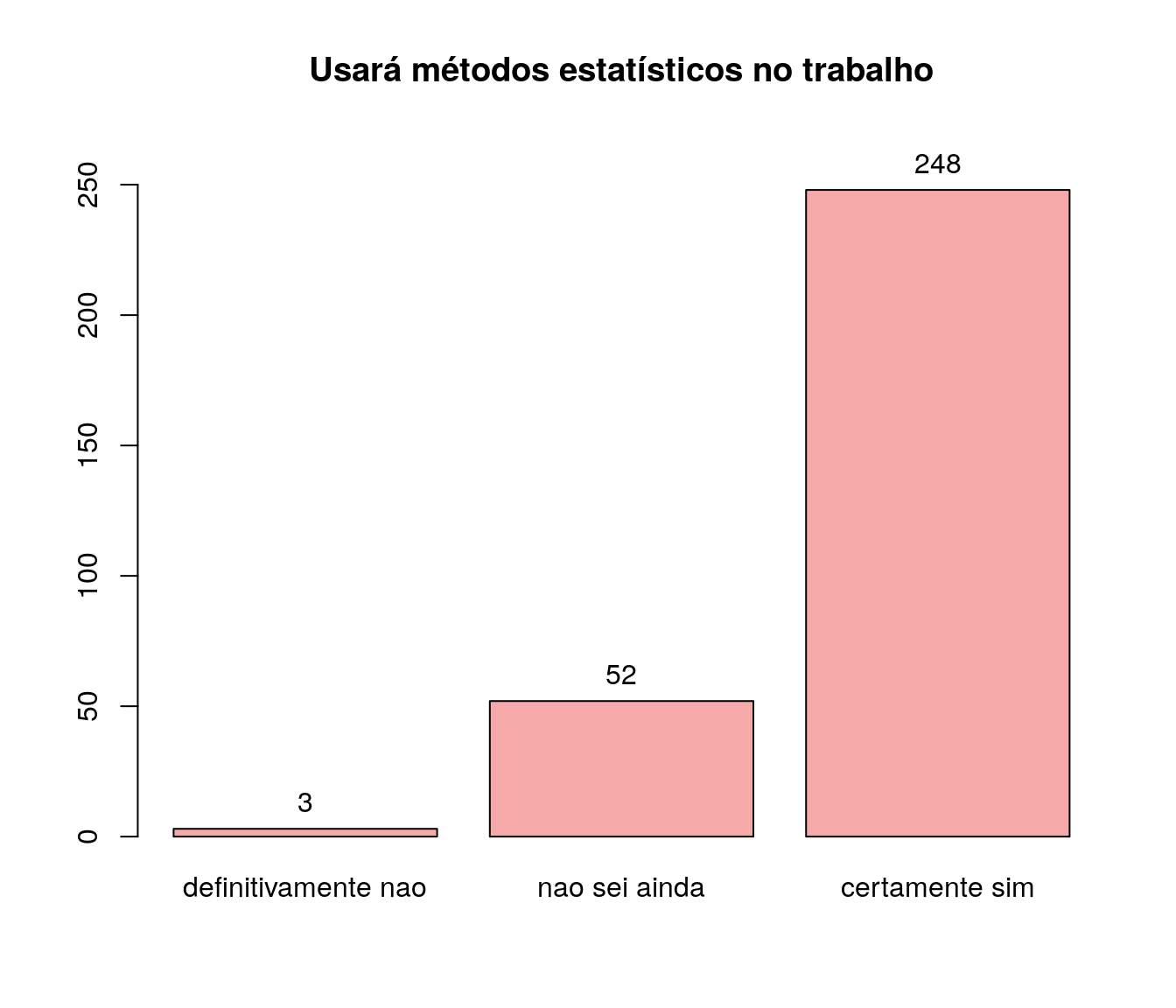
Qual a importância que você atribui à Estatística no seu trabalho de Pós-Graduação/Pesquisa?
Tabela 1
quest$td_notaImport <- as.integer(quest$td_notaImport)
fa_import <- table(quest$td_notaImport) # frequência absoluta
fr_import <- prop.table(fa_import) # frequência relativa
fac_import <- cumsum(fr_import) # frequência acumulada
import <- data.frame(niveis = names(fa_import),
freq = as.vector(fa_import),
freq_r = as.vector(fr_import),
freq_ac = as.vector(fac_import)) # unindo as informações
pander:::pander(import) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| 0 | 2 | 0.00266 | 0.00266 |
| 1 | 1 | 0.00133 | 0.003989 |
| 3 | 1 | 0.00133 | 0.005319 |
| 4 | 3 | 0.003989 | 0.009309 |
| 5 | 27 | 0.0359 | 0.04521 |
| 6 | 15 | 0.01995 | 0.06516 |
| 7 | 55 | 0.07314 | 0.1383 |
| 8 | 134 | 0.1782 | 0.3165 |
| 9 | 90 | 0.1197 | 0.4362 |
| 10 | 424 | 0.5638 | 1 |
Tabela 2
medidas <- data.frame(minimo = quantile(quest$td_notaImport)[1],
quart1 = quantile(quest$td_notaImport)[2],
media = mean(quest$td_notaImport),
mediana = quantile(quest$td_notaImport)[3],
moda = names(sort(table(quest$td_notaImport),
decreasing = TRUE)[1]),
quart3 = quantile(quest$td_notaImport)[4],
max = quantile(quest$td_notaImport)[5])
row.names(medidas) <- NULL
pander(medidas)| minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|
| 0 | 8 | 8.973 | 10 | 10 | 10 | 10 |
disp <- data.frame(amplitude = diff(range(quest$td_notaImport)),
variancia = var(quest$td_notaImport),
desv_pad = sd(quest$td_notaImport),
coef_var = 100*sd(quest$td_notaImport)/mean(quest$td_notaImport))
pander(disp)| amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|
| 10 | 2.239 | 1.496 | 16.68 |
Gráfico 1
plot(table(quest$td_notaImport), t = "h", xlab = "Nota",
ylab = "Frequência", lwd = 6, cex.axis = 0.8,
main = "Importância da Estatística na Pesquisa")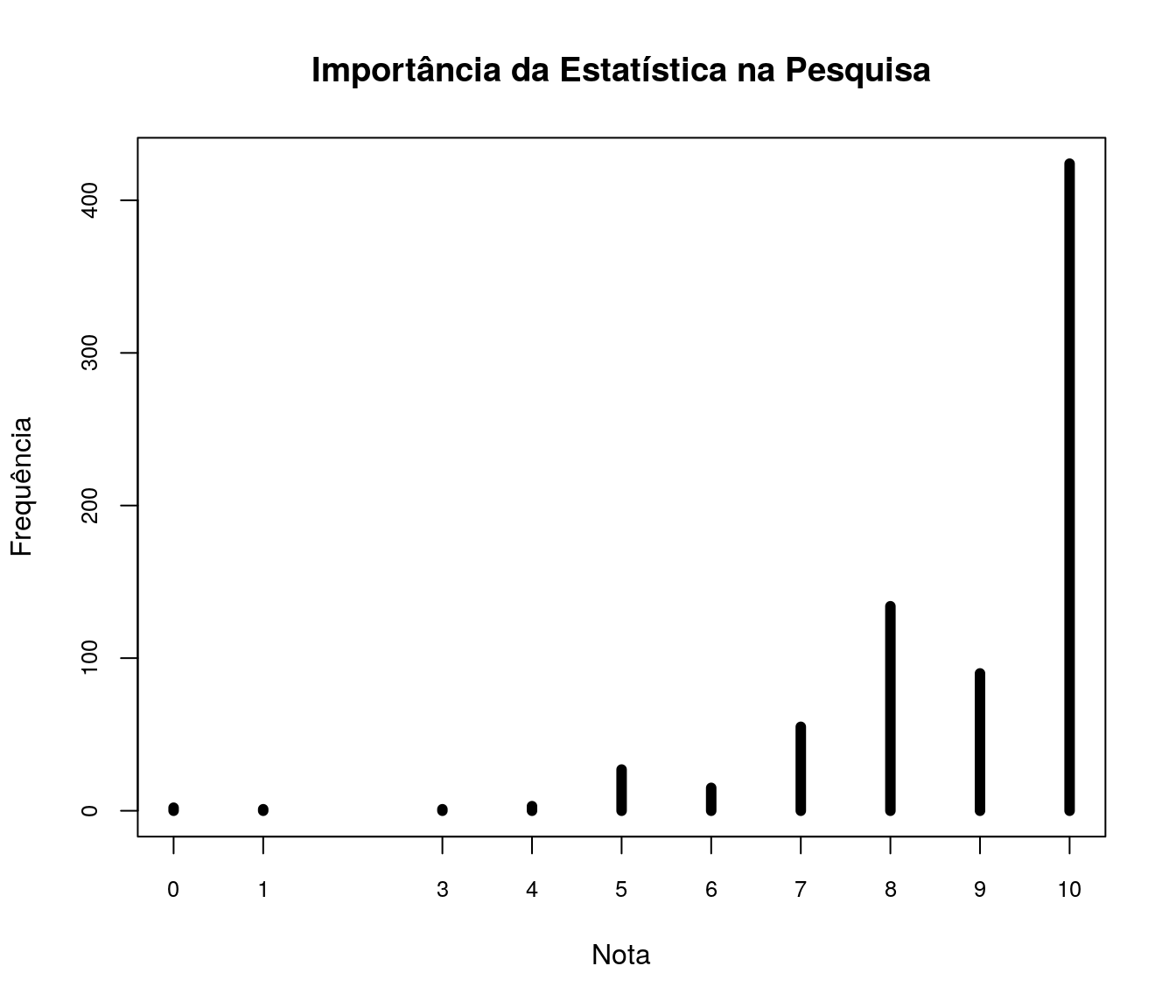
Gráfico 2
layout(mat = matrix(c(1,2),2,1, byrow=TRUE), height = c(3,1))
par(mar=c(3.1, 3.1, 1.1, 2.1))
hist(quest$td_notaImport,col = "#F6CEF5",
main = "Importância da Estatística na Pesquisa",
xlab = "Ano",
ylab = "Frequência")
boxplot(quest$td_notaImport,
horizontal=TRUE,
outline=TRUE,
frame=F,
col = "#F6CEF5",
width = 10)
stripchart(quest$td_notaImport,
vertical=F, add=T,
method="jitter",
pch=19, cex=0.5,
jitter=0.3)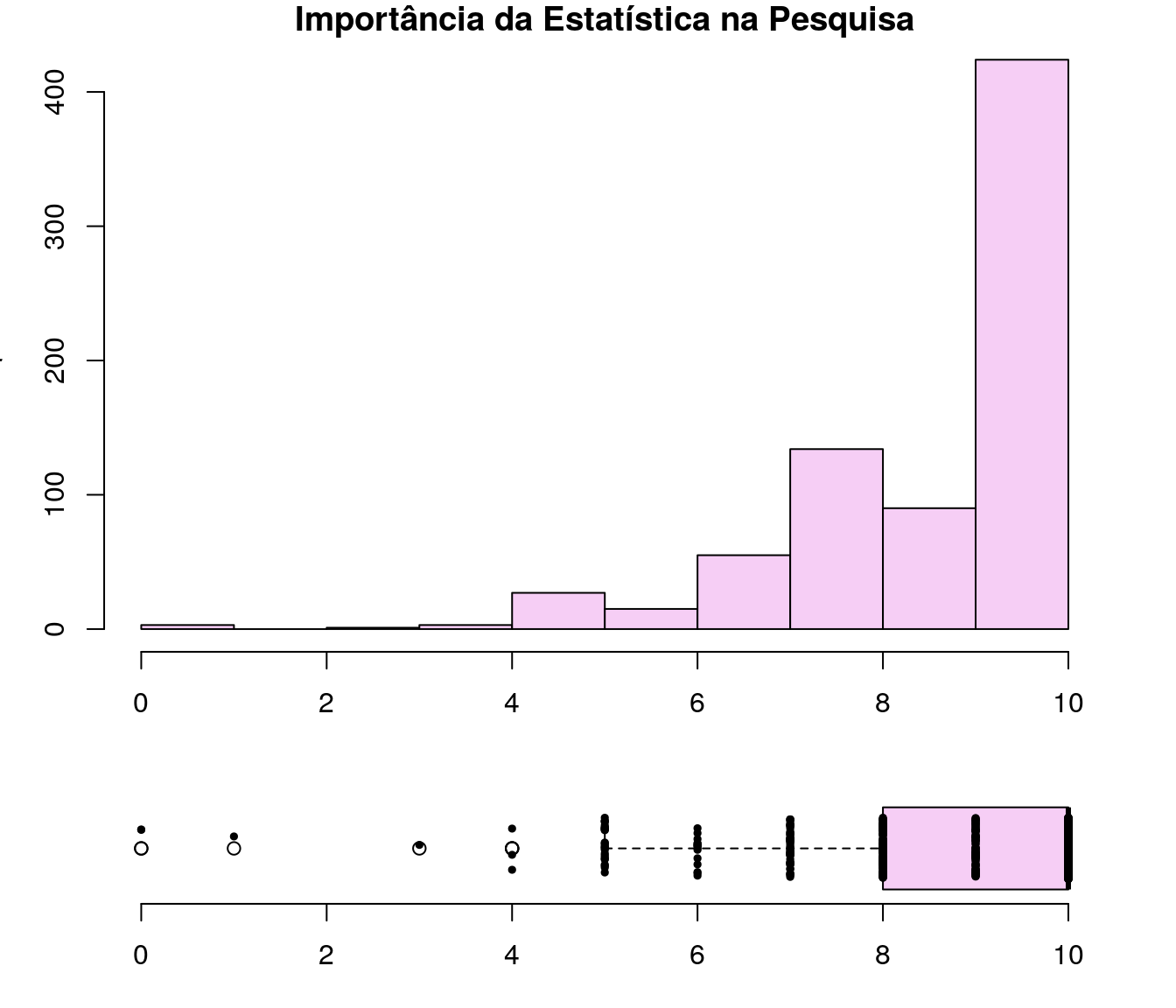
2019
antigo$td_notaImport <- as.integer(antigo$td_notaImport)
fa_import <- table(antigo$td_notaImport) # frequência absoluta
fr_import <- prop.table(fa_import) # frequência relativa
fac_import <- cumsum(fr_import) # frequência acumulada
import <- data.frame(niveis = names(fa_import),
freq = as.vector(fa_import),
freq_r = as.vector(fr_import),
freq_ac = as.vector(fac_import)) # unindo as informações
#pander:::pander(import) # gerando a tabela
layout(mat = matrix(c(1,2),2,1, byrow=TRUE), height = c(3,1))
par(mar=c(3.1, 3.1, 1.1, 2.1))
hist(antigo$td_notaImport,col = "#F6CEF5",
main = "Importância da Estatística na Pesquisa",
xlab = "Ano",
ylab = "Frequência")
boxplot(antigo$td_notaImport,
horizontal=TRUE,
outline=TRUE,
frame=F,
col = "#F6CEF5",
width = 10)
stripchart(antigo$td_notaImport,
vertical=F, add=T,
method="jitter",
pch=19, cex=0.5,
jitter=0.3)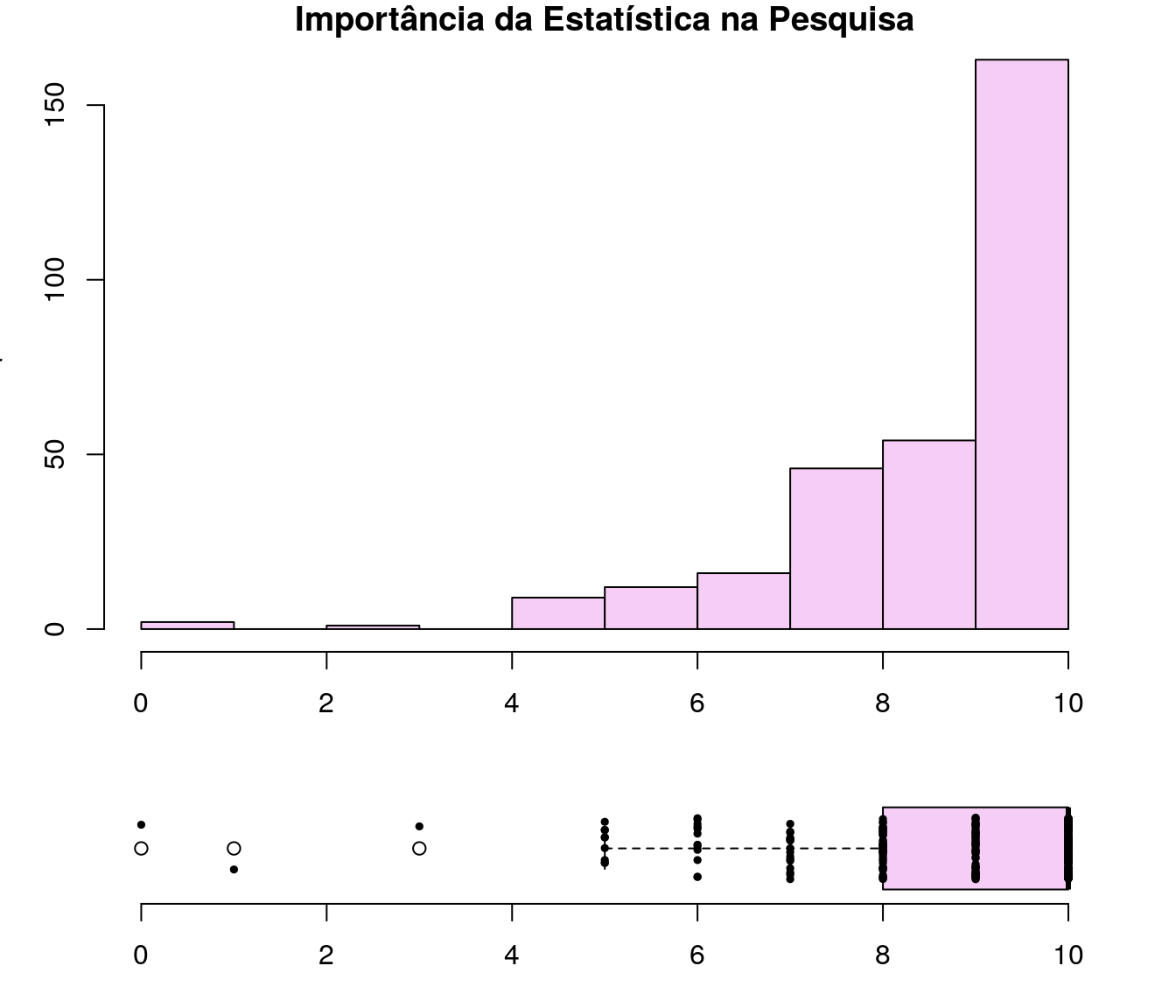
Se você está fazendo Pós-Graduação, qual a sua principal expectativa após a conclusão?
Tabela
quest$ln_expectAposPG <- tolower(iconv(quest$ln_expectAposPG,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- c("conseguir um emprego.",
"aumento salarial e oportunidades mais promissoras.",
"continuar com a pesquisa e avancar para o proximo curso. seguir os estudos.")
quest$ln_expectAposPG[ !quest$ln_expectAposPG %in% classOpcoes ] <- "outro"
quest$ln_expectAposPG <- factor(quest$ln_expectAposPG,
levels = c("conseguir um emprego.",
"aumento salarial e oportunidades mais promissoras.",
"continuar com a pesquisa e avancar para o proximo curso. seguir os estudos.",
"outro"))
fa_exp <- table(quest$ln_expectAposPG) # frequência absoluta
fr_exp <- prop.table(fa_exp) # frequência relativa
fac_exp <- cumsum(fr_exp) # frequência acumulada
exp <- data.frame(niveis = names(fa_exp),
freq = as.vector(fa_exp),
freq_r = as.vector(fr_exp),
freq_ac = as.vector(fac_exp)) # unindo as informações
pander:::pander(exp) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| conseguir um emprego. | 127 | 0.1689 | 0.1689 |
| aumento salarial e oportunidades mais promissoras. | 210 | 0.2793 | 0.4481 |
| continuar com a pesquisa e avancar para o proximo curso. seguir os estudos. | 381 | 0.5066 | 0.9548 |
| outro | 34 | 0.04521 | 1 |
Gráfico
exp$niveis <- c("Conseguir Emprego", "Aumento salarial",
"Continuar a pesquisa", "Outro")
exp_sort <- arrange(exp, exp$freq)
bp <- barplot(exp_sort$freq,
#names.arg = at_ord$niveis,
col = paleta,
main = 'Expectativa após conclusão \ndo Mestrado',
ylab = 'Frequência',
xlab = '',
ylim = c(0,max(exp_sort$freq+50))
#horiz = T,
#las=2,
)
legend("topleft",
legend = exp_sort$niveis,
fill = paleta,
cex = .8)
text(x = c(bp),
y = exp_sort$freq,
labels = exp_sort$freq,
pos = 3)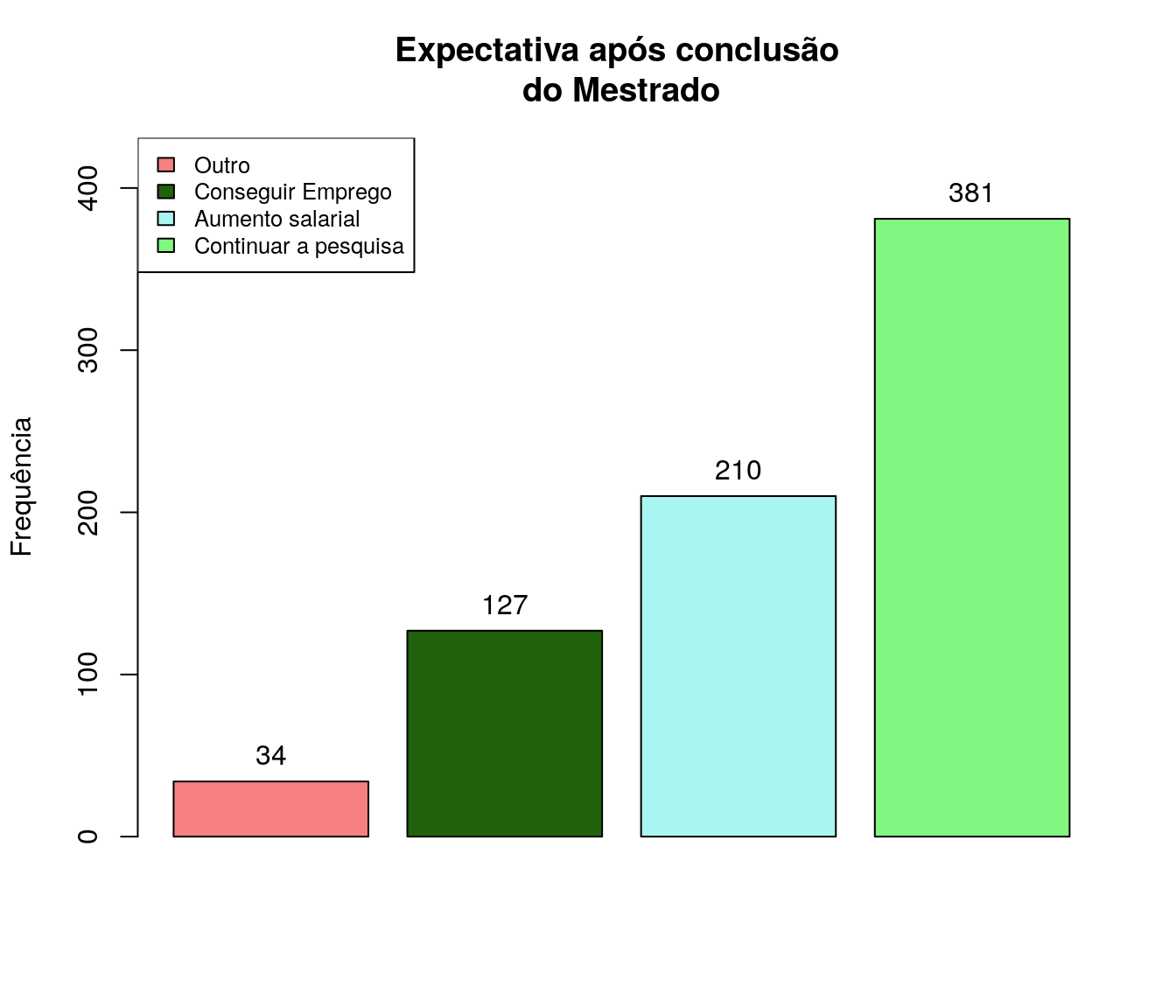
2019
antigo$ln_expectAposPG <- tolower(iconv(antigo$ln_expectAposPG,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- c("conseguir um emprego.",
"aumento salarial e oportunidades mais promissoras.",
"continuar com a pesquisa e avancar para o proximo curso. seguir os estudos.")
antigo$ln_expectAposPG[ !antigo$ln_expectAposPG %in% classOpcoes ] <- "outro"
antigo$ln_expectAposPG <- factor(antigo$ln_expectAposPG,
levels = c("conseguir um emprego.",
"aumento salarial e oportunidades mais promissoras.",
"continuar com a pesquisa e avancar para o proximo curso. seguir os estudos.",
"outro"))
fa_exp <- table(antigo$ln_expectAposPG) # frequência absoluta
fr_exp <- prop.table(fa_exp) # frequência relativa
fac_exp <- cumsum(fr_exp) # frequência acumulada
exp <- data.frame(niveis = names(fa_exp),
freq = as.vector(fa_exp),
freq_r = as.vector(fr_exp),
freq_ac = as.vector(fac_exp)) # unindo as informações
#pander:::pander(exp) # gerando a tabela
exp$niveis <- c("Conseguir Emprego", "Aumento salarial",
"Continuar a pesquisa", "Outro")
exp_sort <- arrange(exp, exp$freq)
bp <- barplot(exp_sort$freq,
#names.arg = at_ord$niveis,
col = paleta,
main = 'Expectativa após conclusão \ndo Mestrado',
ylab = 'Frequência',
xlab = '',
ylim = c(0,max(exp_sort$freq+50))
#horiz = T,
#las=2,
)
legend("topleft",
legend = exp_sort$niveis,
fill = paleta,
cex = .8)
text(x = c(bp),
y = exp_sort$freq,
labels = exp_sort$freq,
pos = 3)
Como ficou sabendo da Disciplina Transversal?
Tabela
quest$ln_conhecTransv <- tolower(iconv(quest$ln_conhecTransv,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- c("site da ufpr ou instituicao de origem",
"email institucional da sucom (superintendencia de comunicacao e marketing)",
"por alguma outra midia social da ufpr",
"pelos professores que ministram/ministraram disciplinas da transversal",
"pelo(a) orientador(a)",
"por ex-alunos da disciplina",
"por colegas")
quest$ln_conhecTransv[ !quest$ln_conhecTransv %in% classOpcoes ] <- "outro"
quest$ln_conhecTransv <- factor(quest$ln_conhecTransv,
levels = c("site da ufpr ou instituicao de origem",
"email institucional da sucom (superintendencia de comunicacao e marketing)",
"por alguma outra midia social da ufpr",
"pelos professores que ministram/ministraram disciplinas da transversal",
"pelo(a) orientador(a)",
"por ex-alunos da disciplina",
"por colegas",
"outro"))
fa_tr <- table(quest$ln_conhecTransv) # frequência absoluta
fr_tr <- prop.table(fa_tr) # frequência relativa
fac_tr <- cumsum(fr_tr) # frequência acumulada
tr <- data.frame(niveis = names(fa_tr),
freq = as.vector(fa_tr),
freq_r = as.vector(fr_tr),
freq_ac = as.vector(fac_tr)) # unindo as informações
pander:::pander(tr) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| site da ufpr ou instituicao de origem | 299 | 0.3976 | 0.3976 |
| email institucional da sucom (superintendencia de comunicacao e marketing) | 56 | 0.07447 | 0.4721 |
| por alguma outra midia social da ufpr | 16 | 0.02128 | 0.4934 |
| pelos professores que ministram/ministraram disciplinas da transversal | 28 | 0.03723 | 0.5306 |
| pelo(a) orientador(a) | 208 | 0.2766 | 0.8072 |
| por ex-alunos da disciplina | 9 | 0.01197 | 0.8191 |
| por colegas | 52 | 0.06915 | 0.8883 |
| outro | 84 | 0.1117 | 1 |
Gráfico
tr$niveis <- c("Site da UFPR",
"Email SuCom",
"Mídia social", "Prof.",
"Orientador", "Ex-alunos",
"Colegas", "Outro")
tr_sort <- arrange(tr, tr$freq)
bp <- barplot(tr_sort$freq,
#names.arg = at_ord$niveis,
col = paleta,
main = 'Como soube da disciplina',
ylab = 'Frequência',
xlab = '',
ylim = c(0,max(tr_sort$freq+50))
#horiz = T,
#las=2,
)
legend("topleft",
legend = tr_sort$niveis,
fill = paleta,
cex = .8)
text(x = c(bp),
y = tr_sort$freq,
labels = tr_sort$freq,
pos = 3)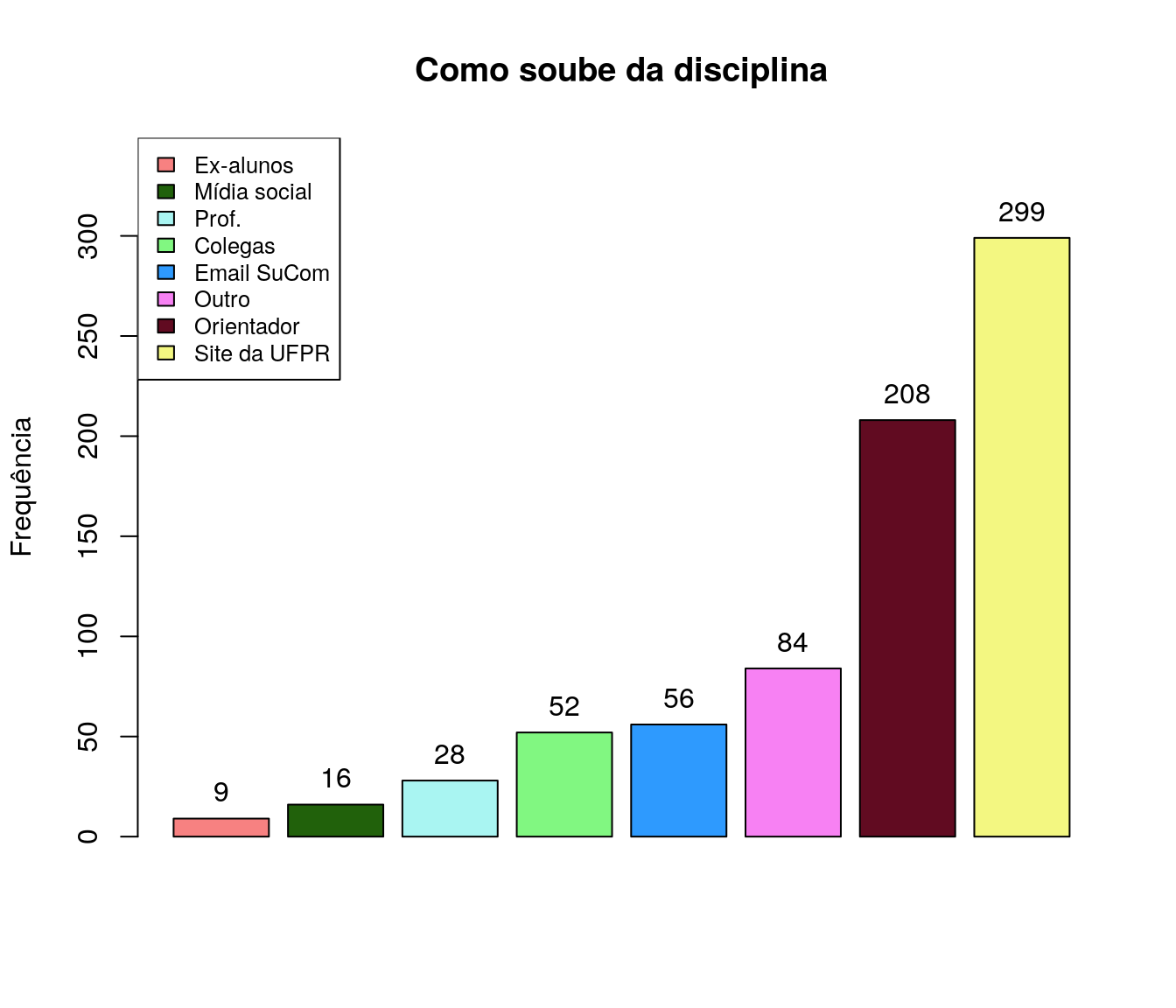
Após se matricular no SIGA, você assistiu alguma aula do ano anterior da Disciplina no YouTube?
Tabela
quest$lo_videoTransv <- tolower(iconv(quest$lo_videoTransv,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$lo_videoTransv <- factor(quest$lo_videoTransv, levels = c("sim", "nao"))
fa_video <- table(quest$lo_video) # frequência absoluta
fr_video <- prop.table(fa_video) # frequência relativa
fac_video <- cumsum(fr_video) # frequência acumulada
video <- data.frame(niveis = names(fa_video),
freq = as.vector(fa_video),
freq_r = as.vector(fr_video),
freq_ac = as.vector(fac_video)) # unindo as informações
pander:::pander(video) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| sim | 45 | 0.05984 | 0.05984 |
| nao | 707 | 0.9402 | 1 |
Gráfico
par(mfrow = c(1,2))
ar_color <- c("#81F7F3", "#D8D8D8")
pie(video$freq, col = ar_color,
main = "Assistiu alguma \naula no Youtube",
labels = percent(video$freq_r))
legend("topleft", legend = video$niveis, fill = ar_color, cex = 1)
barplot(video$freq, col = ar_color,
main = "Assistiu alguma \naula no Youtube",
names.arg = video$niveis,
ylim = c(0, max(video$freq + 20)))
text(x = as.vector(barplot(video$freq, plot = FALSE)),
y = as.vector(video$freq) + 10,
labels = video$freq, cex = 1)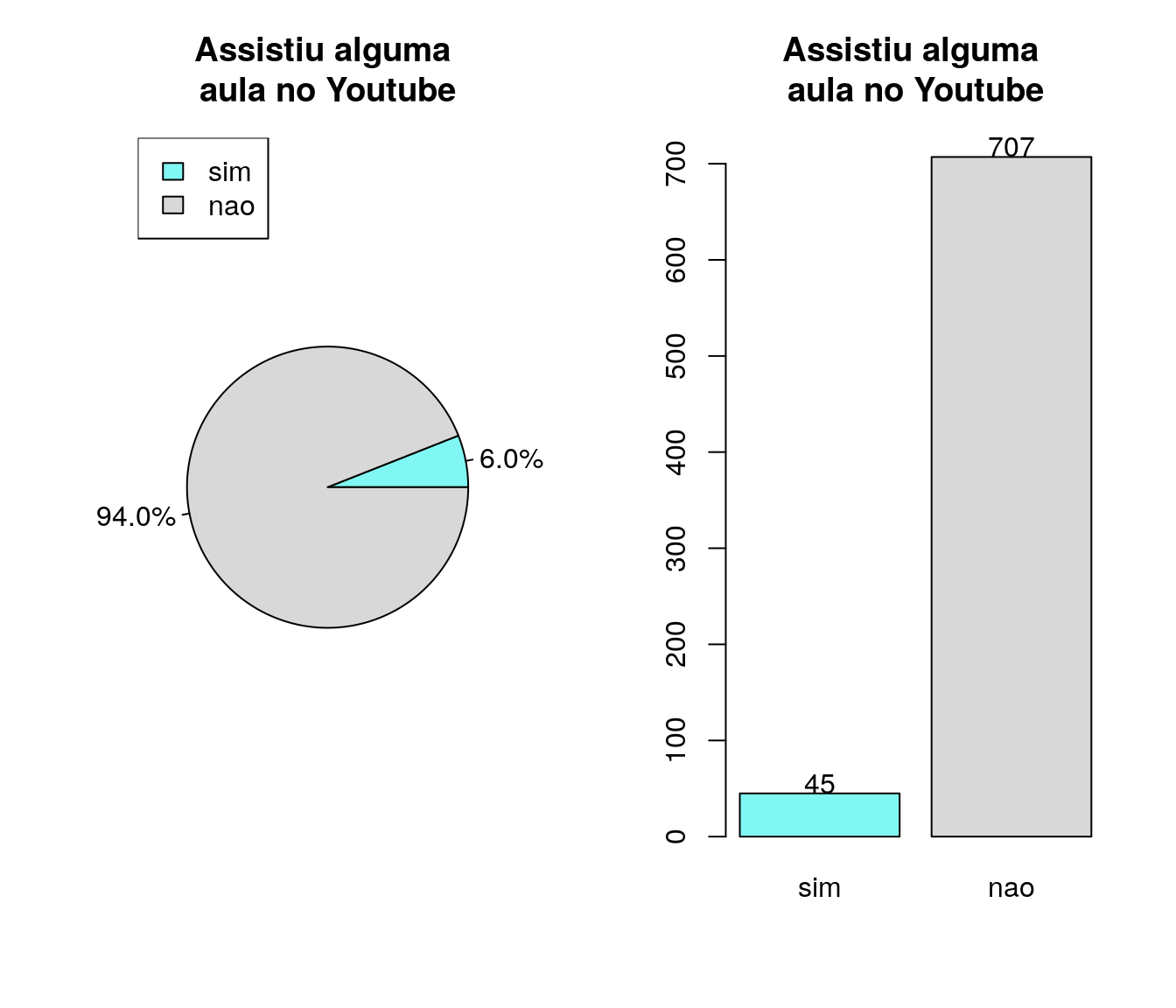
A qual turma da disciplina você pertence?
Tabela
quest$ln_turma <- factor(quest$ln_turma,
levels = c("Presencial", "Remota"))
fa_turma <- table(quest$ln_turma) # frequência absoluta
fr_turma <- prop.table(fa_turma) # frequência relativa
fac_turma <- cumsum(fr_turma) # frequência acumulada
turma <- data.frame(niveis = names(fa_turma),
freq = as.vector(fa_turma),
freq_r = as.vector(fr_turma),
freq_ac = as.vector(fac_turma)) # unindo as informações
pander:::pander(turma) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| Presencial | 83 | 0.1104 | 0.1104 |
| Remota | 669 | 0.8896 | 1 |
Gráfico
par(mfrow = c(1,2))
ar_color <- c("#000000", "#D8D8D8")
pie(turma$freq, col = ar_color,
main = "Turma",
labels = percent(turma$freq_r))
legend("topleft", legend = turma$niveis, fill = ar_color, cex = 1)
barplot(turma$freq, col = ar_color,
main = "Turma",
names.arg = turma$niveis,
ylim = c(0, max(turma$freq + 20)))
text(x = as.vector(barplot(turma$freq, plot = FALSE)),
y = as.vector(turma$freq) + 10,
labels = turma$freq, cex = 1)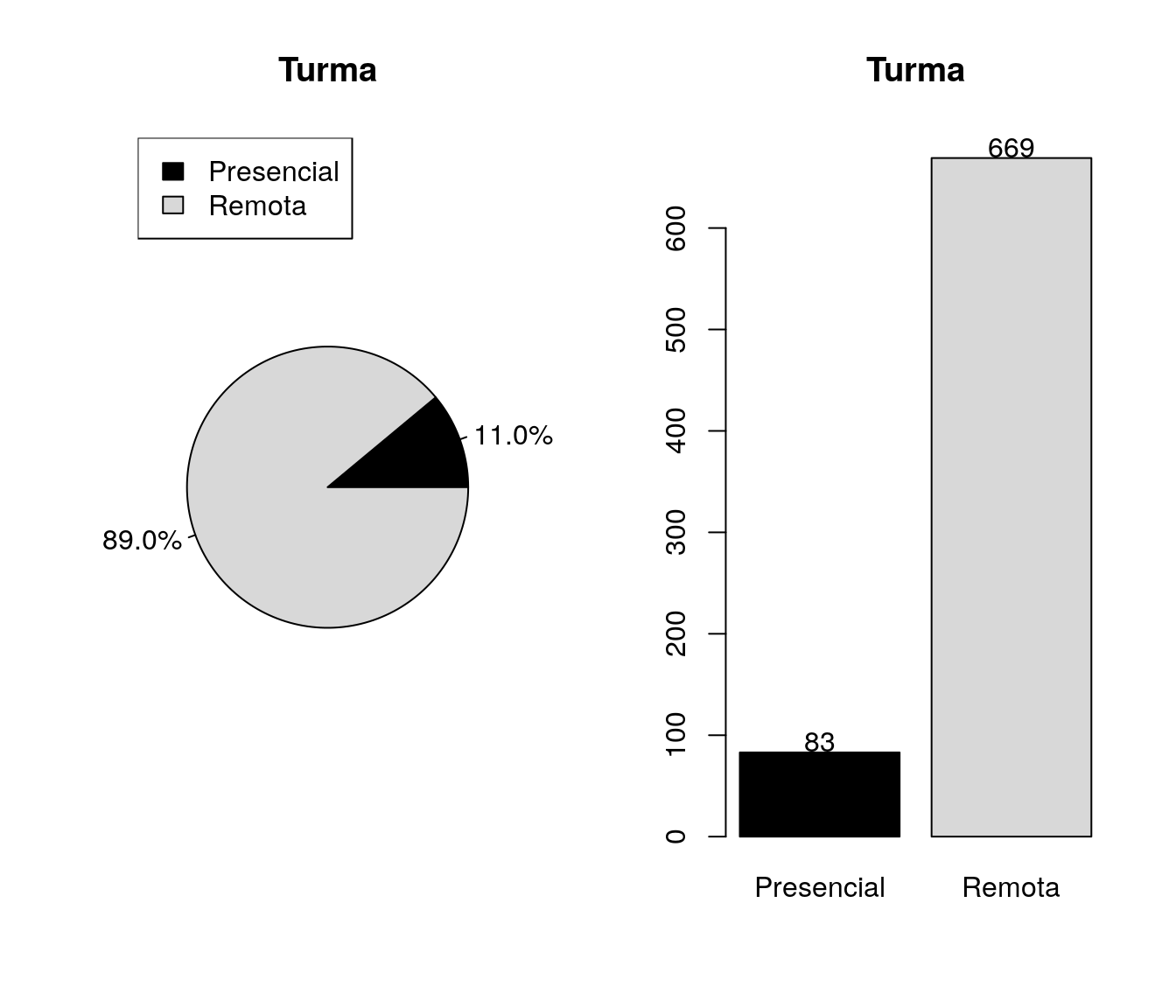
Tem/teve contato ou conhecimento sobre o Prof. Coordenador da Disciplina (Paulo Justiniano)?
Tabela
quest$lo_contatoProfDisc <- tolower(iconv(quest$lo_contatoProfDisc,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$lo_contatoProfDisc <- factor(quest$lo_contatoProfDisc, levels = c("sim", "nao"))
fa_prof <- table(quest$lo_contatoProfDisc) # frequência absoluta
fr_prof <- prop.table(fa_prof) # frequência relativa
fac_prof <- cumsum(fr_prof) # frequência acumulada
prof <- data.frame(niveis = names(fa_prof),
freq = as.vector(fa_prof),
freq_r = as.vector(fr_prof),
freq_ac = as.vector(fac_prof)) # unindo as informações
pander:::pander(prof) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| sim | 31 | 0.04122 | 0.04122 |
| nao | 721 | 0.9588 | 1 |
Gráfico
par(mfrow = c(1,2))
ar_color <- c("#81F7F3", "#58FA58")
pie(prof$freq, col = ar_color,
main = "Conhece o professor",
labels = percent(prof$freq_r))
legend("topleft", legend = prof$niveis, fill = ar_color, cex = 1)
barplot(prof$freq, col = ar_color,
main = "Conhece o professor",
names.arg = prof$niveis,
ylim = c(0, max(prof$freq + 20)))
text(x = as.vector(barplot(prof$freq, plot = FALSE)),
y = as.vector(prof$freq) + 10,
labels = prof$freq, cex = 1)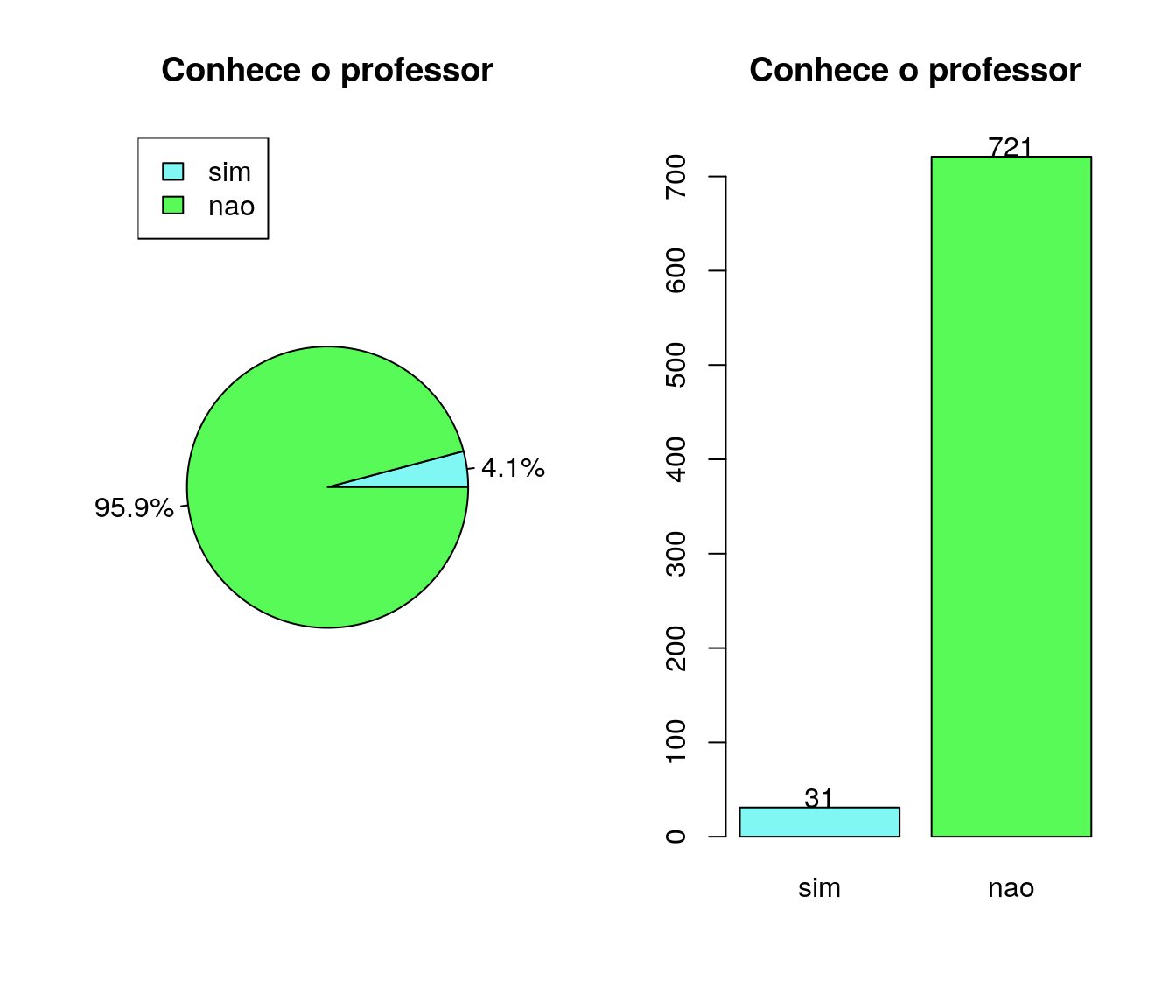
Tem/teve contato ou conhecimento sobre o(s) prof(s). colaboradores da disciplina?
Tabela
quest$lo_contatoProfColabDisc <- tolower(iconv(quest$lo_contatoProfColabDisc,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$lo_contatoProfColabDisc <- factor(quest$lo_contatoProfColabDisc, levels = c("sim", "nao"))
fa_prof2 <- table(quest$lo_contatoProfColabDisc) # frequência absoluta
fr_prof2 <- prop.table(fa_prof2) # frequência relativa
fac_prof2 <- cumsum(fr_prof2) # frequência acumulada
prof2 <- data.frame(niveis = names(fa_prof2),
freq = as.vector(fa_prof2),
freq_r = as.vector(fr_prof2),
freq_ac = as.vector(fac_prof2)) # unindo as informações
pander:::pander(prof2) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| sim | 47 | 0.0625 | 0.0625 |
| nao | 705 | 0.9375 | 1 |
Gráfico
par(mfrow = c(1,2))
ar_color <- c("#BE81F7", "#F2F5A9")
pie(prof2$freq, col = ar_color,
main = "Conhece os professores",
labels = percent(prof2$freq_r))
legend("topleft", legend = prof2$niveis, fill = ar_color, cex = 1)
barplot(prof2$freq, col = ar_color,
main = "Conhece os professores",
names.arg = prof2$niveis,
ylim = c(0, max(prof2$freq + 20)))
text(x = as.vector(barplot(prof2$freq, plot = FALSE)),
y = as.vector(prof2$freq) + 10,
labels = prof2$freq, cex = 1)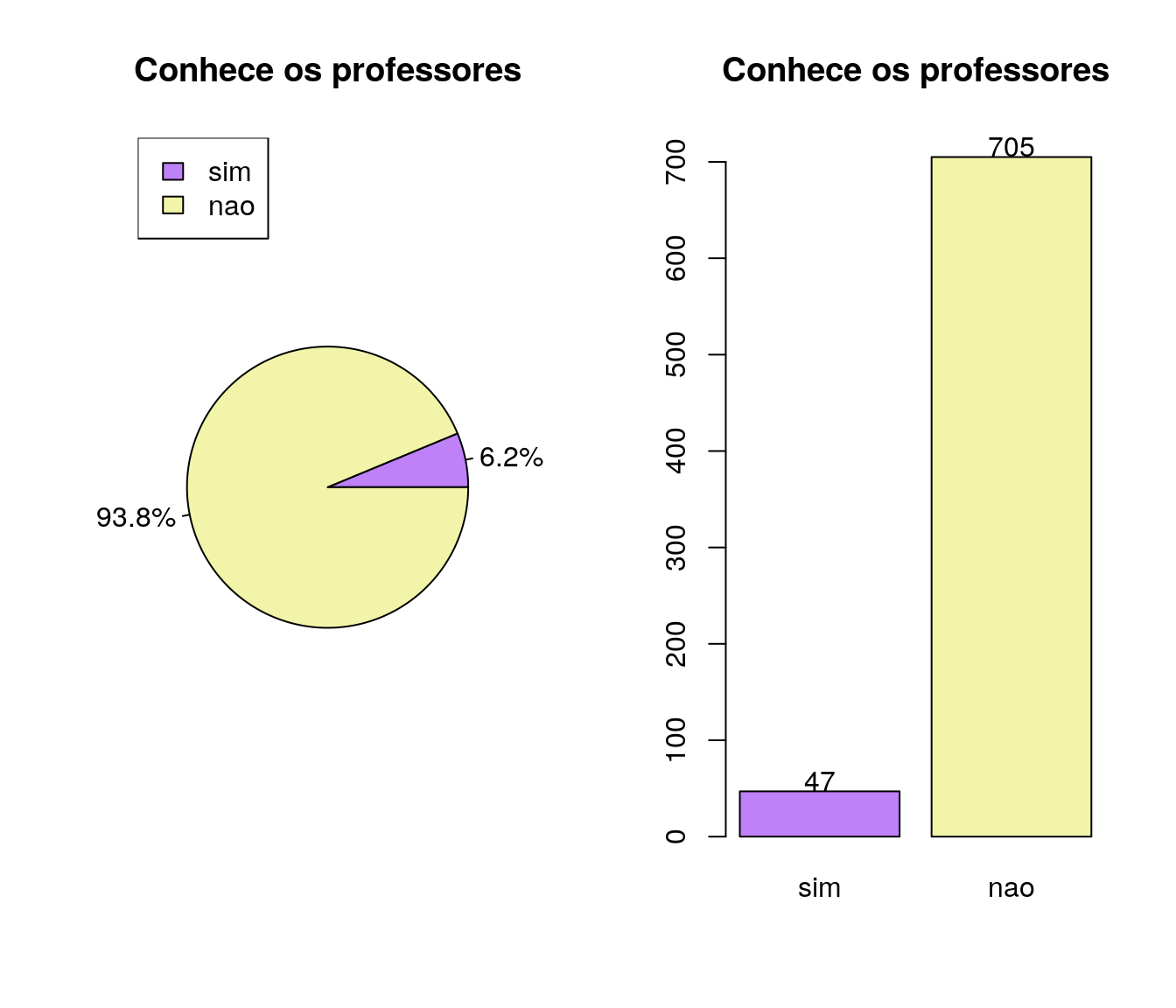
Você cursou o ensino médio em escola pública ou particular?
Tabela
quest$ln_medio1 <-
tolower(iconv(quest$ln_medio1,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$ln_medio1 <- factor(quest$ln_medio1, levels = c("totalmente em escola publica", "totalmente em escola particular", "parte em escola publica, parte em particular"))
fa_medio1 <- table(quest$ln_medio1) # frequência absoluta
fr_medio1 <- prop.table(fa_medio1) # frequência relativa
fac_medio1 <- cumsum(fr_medio1) # frequência acumulada
medio1 <- data.frame(niveis = names(fa_medio1),
freq = as.vector(fa_medio1),
freq_r = as.vector(fr_medio1),
freq_ac = as.vector(fac_medio1)) # unindo as informações
pander:::pander(medio1) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| totalmente em escola publica | 380 | 0.5053 | 0.5053 |
| totalmente em escola particular | 310 | 0.4122 | 0.9176 |
| parte em escola publica, parte em particular | 62 | 0.08245 | 1 |
Gráfico
medio1$niveis <- c('Púbica','Particular', 'Ambos')
medio1 <- arrange(medio1, desc(medio1$niveis))
bp <-
barplot(medio1$freq,
#horiz = TRUE,
names.arg = medio1$niveis,
col = '#173B0B',
main = "Ensino médio",
ylim = c(0, max(medio1$freq + 20)),
cex.names=1
#, las = 2
)
text(x = c(bp),
y = medio1$freq,
labels = medio1$freq,
pos = 3)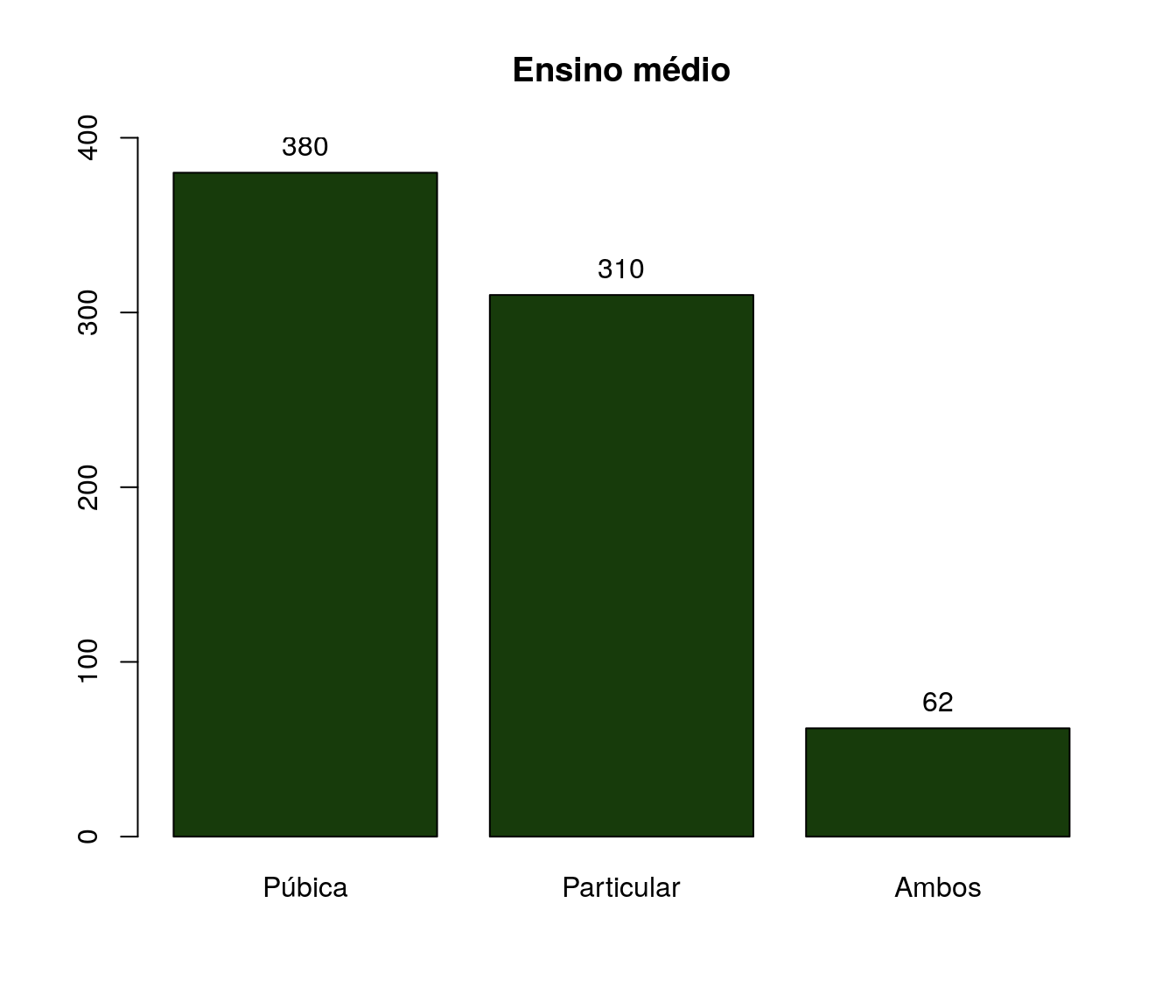
Você cursou ensino médio tradicional ou profissionalizante?
Tabela
quest$ln_medio2 <- tolower(iconv(quest$ln_medio2,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- tolower(c("Ensino medio tradicional",
"Ensino medio profissionalizante (tecnico)"))
quest$ln_medio2[ !quest$ln_medio2 %in% classOpcoes ] <- "outro"
quest$ln_medio2 <- factor(quest$ln_medio2,
levels = c("ensino medio tradicional",
"ensino medio profissionalizante (tecnico)",
"outro"))
fa_medio2 <- table(quest$ln_medio2) # frequência absoluta
fr_medio2 <- prop.table(fa_medio2) # frequência relativa
fac_medio2 <- cumsum(fr_medio2) # frequência acumulada
medio2 <- data.frame(niveis = names(fa_medio2),
freq = as.vector(fa_medio2),
freq_r = as.vector(fr_medio2),
freq_ac = as.vector(fac_medio2)) # unindo as informações
pander:::pander(medio2) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| ensino medio tradicional | 640 | 0.8511 | 0.8511 |
| ensino medio profissionalizante (tecnico) | 93 | 0.1237 | 0.9747 |
| outro | 19 | 0.02527 | 1 |
Gráfico
medio2$niveis <- c('Tradicional', 'Profissionalizante', 'Outro')
medio2 <- arrange(medio2, desc(medio2$niveis))
bp <-
barplot(medio2$freq,
#horiz = TRUE,
names.arg = medio2$niveis,
col = '#29088A',
main = "Modalidade de ensino médio",
ylim = c(0, max(medio2$freq + 40)),
cex.names=1
#, las = 2
)
text(x = c(bp),
y = medio2$freq,
labels = medio2$freq,
pos = 3)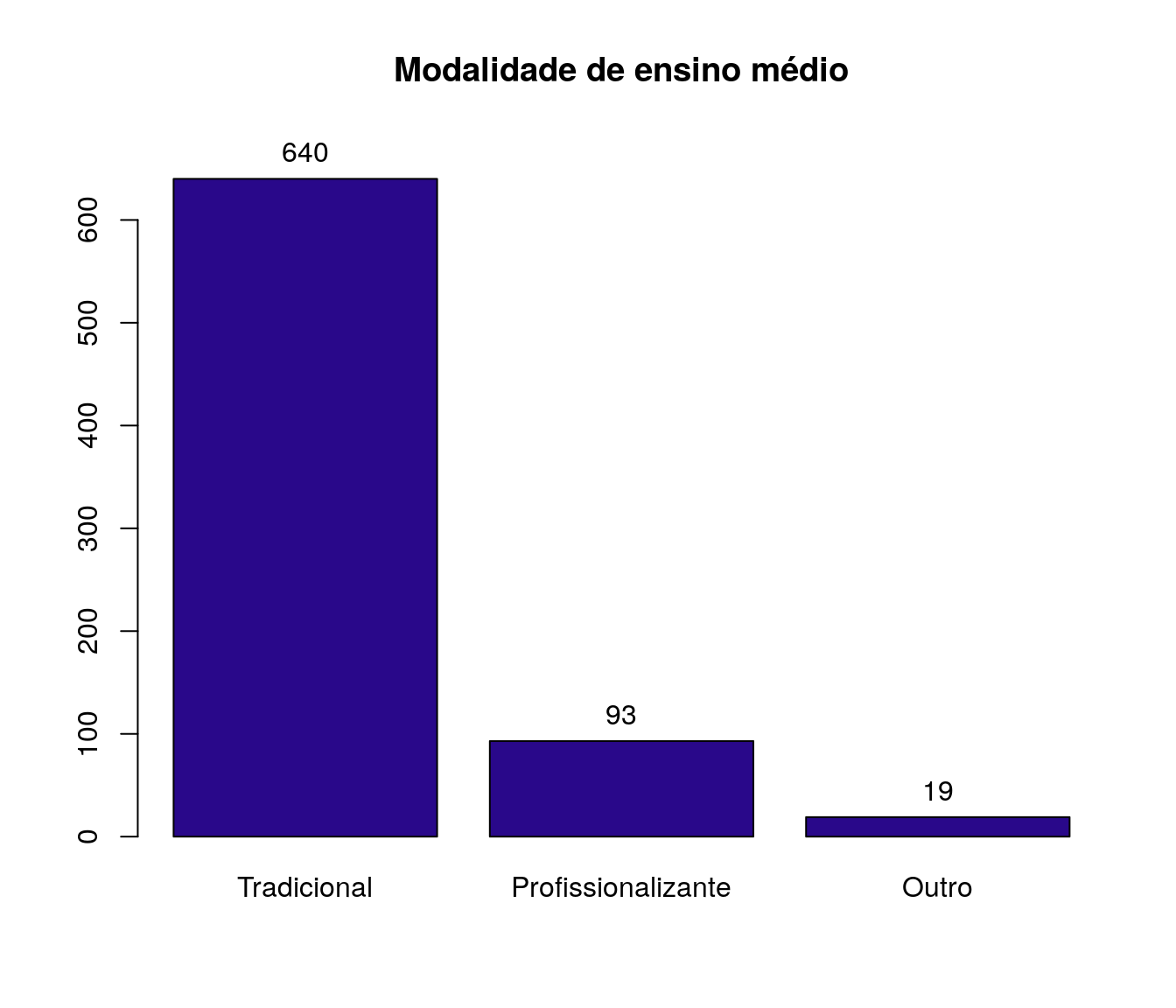
Perfil do aluno
Sexo
Tabela
quest$ln_sexo <- factor(quest$ln_sexo,
levels = c("Masculino", "Feminino"))
fa_sexo <- table(quest$ln_sexo) # frequência absoluta
fr_sexo <- prop.table(fa_sexo) # frequência relativa
fac_sexo <- cumsum(fr_sexo) # frequência acumulada
sexo <- data.frame(niveis = names(fa_sexo),
freq = as.vector(fa_sexo),
freq_r = as.vector(fr_sexo),
freq_ac = as.vector(fac_sexo)) # unindo as informações
pander:::pander(sexo) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| Masculino | 294 | 0.391 | 0.391 |
| Feminino | 458 | 0.609 | 1 |
Gráfico
par(mfrow = c(1,2))
ar_color <- c("#A9F5D0", "#088A85")
pie(sexo$freq, col = ar_color,
main = "Sexo",
labels = percent(sexo$freq_r))
legend("topleft", legend = sexo$niveis, fill = ar_color, cex = 1)
barplot(sexo$freq, col = ar_color,
main = "Sexo",
names.arg = sexo$niveis,
ylim = c(0, max(sexo$freq + 20)))
text(x = as.vector(barplot(sexo$freq, plot = FALSE)),
y = as.vector(sexo$freq) + 10,
labels = sexo$freq, cex = 1)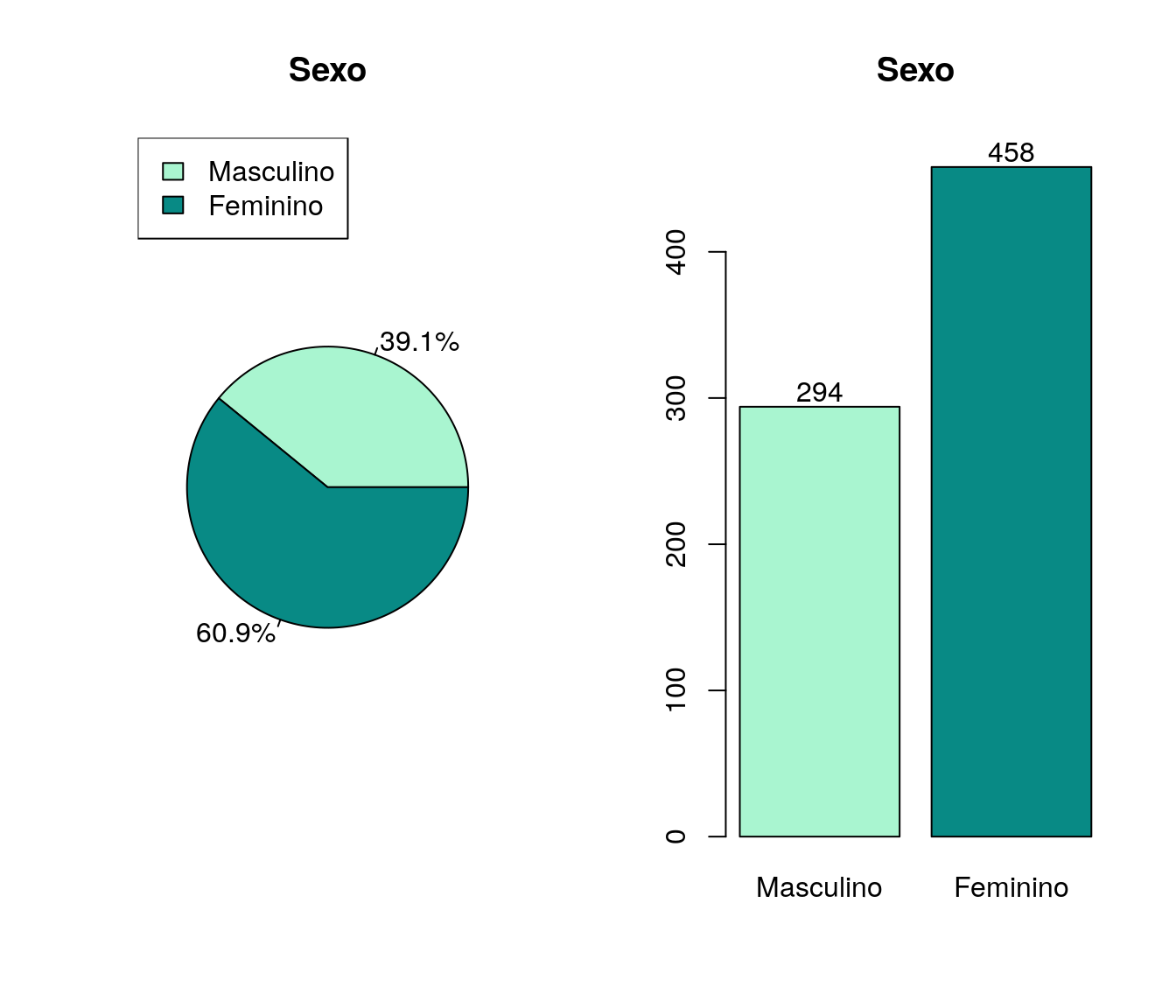
2019
antigo$ln_sexo <- factor(antigo$ln_sexo,
levels = c("Masculino", "Feminino"))
fa_sexo <- table(antigo$ln_sexo) # frequência absoluta
fr_sexo <- prop.table(fa_sexo) # frequência relativa
fac_sexo <- cumsum(fr_sexo) # frequência acumulada
sexo <- data.frame(niveis = names(fa_sexo),
freq = as.vector(fa_sexo),
freq_r = as.vector(fr_sexo),
freq_ac = as.vector(fac_sexo)) # unindo as informações
#pander:::pander(sexo) # gerando a tabela
par(mfrow = c(1,2))
ar_color <- c("#A9F5D0", "#088A85")
pie(sexo$freq, col = ar_color,
main = "Sexo",
labels = percent(sexo$freq_r))
legend("topleft", legend = sexo$niveis, fill = ar_color, cex = 1)
barplot(sexo$freq, col = ar_color,
main = "Sexo",
names.arg = sexo$niveis,
ylim = c(0, max(sexo$freq + 20)))
text(x = as.vector(barplot(sexo$freq, plot = FALSE)),
y = as.vector(sexo$freq) + 10,
labels = sexo$freq, cex = 1)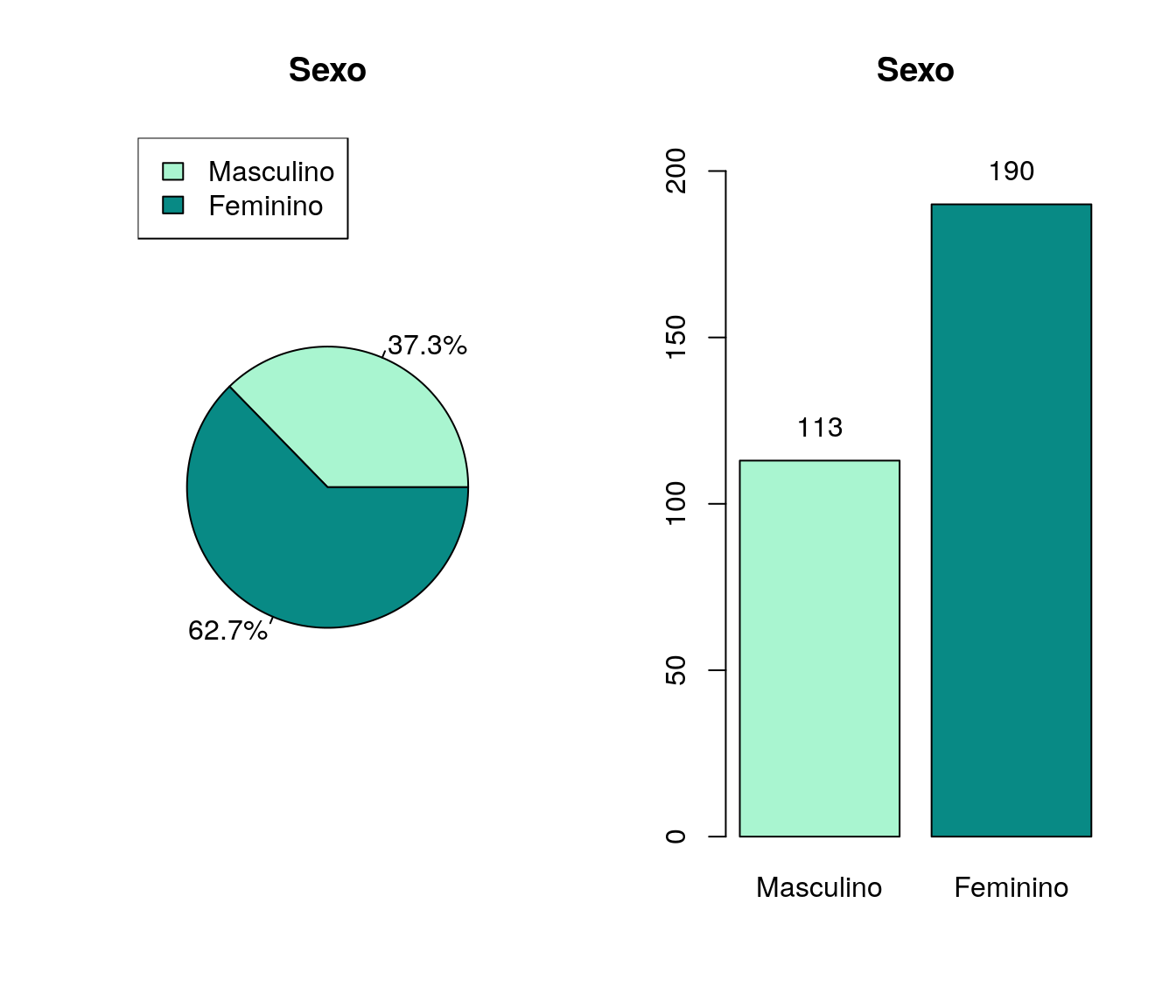
Qual a sua altura?
Tabela 1
quest$tc_altura <- as.integer(quest$tc_altura)
h <- hist(quest$tc_altura, plot = FALSE)
breaks <- h$breaks
classes <- cut(quest$tc_altura, breaks = breaks,
include.lowest = TRUE, right = TRUE)
tb.altura <- as.data.frame(table(classes))
tb.altura$Perc <- 100 * prop.table(tb.altura$Freq)
names(tb.altura)[1] <- "Altura"
pander:::pander(tb.altura)| Altura | Freq | Perc |
|---|---|---|
| [135,140] | 2 | 0.266 |
| (140,145] | 0 | 0 |
| (145,150] | 9 | 1.197 |
| (150,155] | 37 | 4.92 |
| (155,160] | 98 | 13.03 |
| (160,165] | 148 | 19.68 |
| (165,170] | 160 | 21.28 |
| (170,175] | 112 | 14.89 |
| (175,180] | 101 | 13.43 |
| (180,185] | 52 | 6.915 |
| (185,190] | 24 | 3.191 |
| (190,195] | 8 | 1.064 |
| (195,200] | 0 | 0 |
| (200,205] | 1 | 0.133 |
Tabela 2
medidas <- data.frame(minimo = quantile(quest$tc_altura)[1],
quart1 = quantile(quest$tc_altura)[2],
media = mean(quest$tc_altura),
mediana = quantile(quest$tc_altura)[3],
moda = names(sort(table(quest$tc_altura),
decreasing = TRUE)[1]),
quart3 = quantile(quest$tc_altura)[4],
max = quantile(quest$tc_altura)[5])
row.names(medidas) <- NULL
pander(medidas)| minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|
| 136 | 163 | 169.2 | 169 | 170 | 175 | 205 |
disp <- data.frame(amplitude = diff(range(quest$tc_altura)),
variancia = var(quest$tc_altura),
desv_pad = sd(quest$tc_altura),
coef_var = 100*sd(quest$tc_altura)/mean(quest$tc_altura))
pander(disp)| amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|
| 69 | 87.22 | 9.339 | 5.519 |
Gráfico 1
hFreq <- hist(quest$tc_altura,
main = "Histograma da Altura", xlab = "Altura",
ylab = "Frequência", col = "aquamarine3")
y <- density(quest$tc_altura)
lines(y$y ~ y$x, lwd = 3)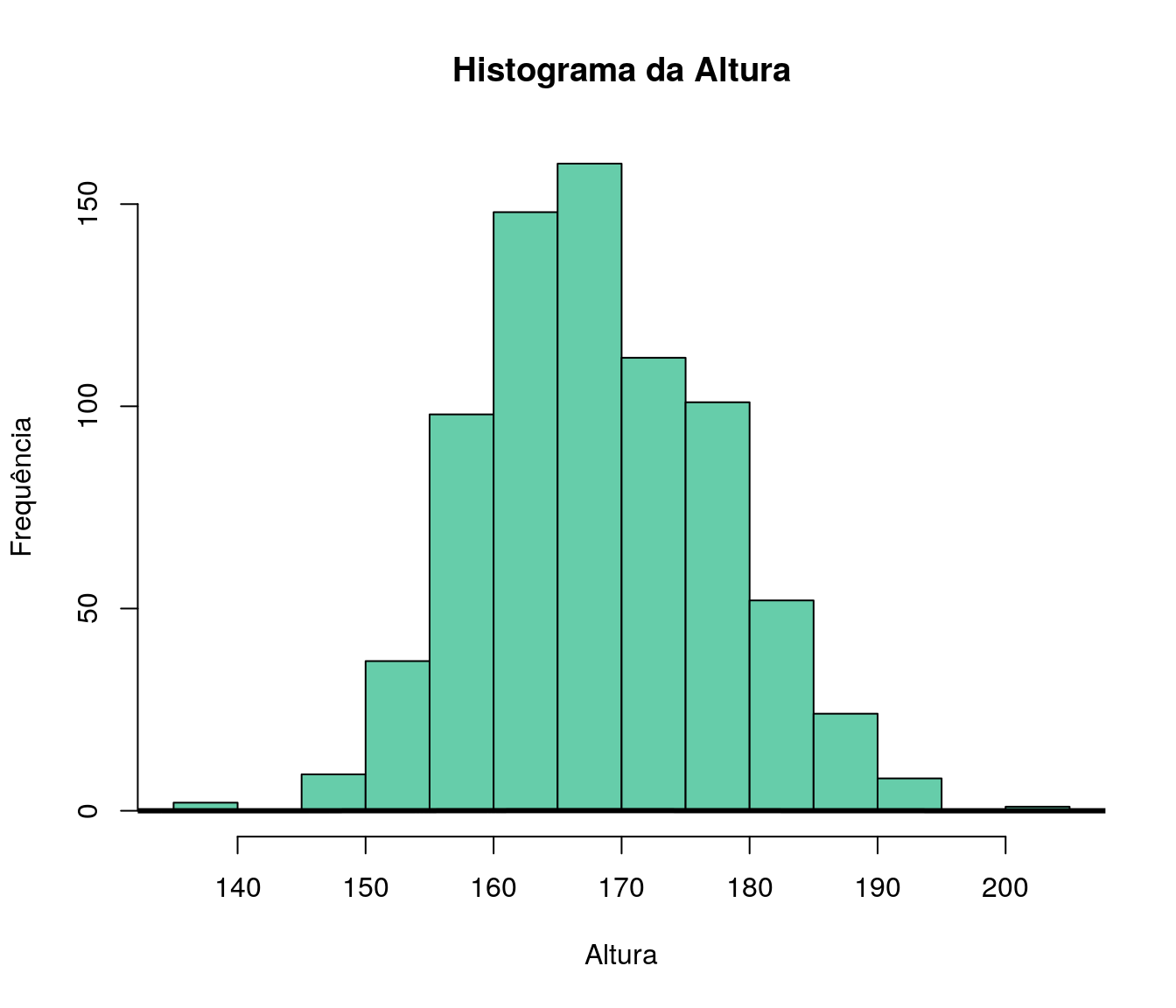
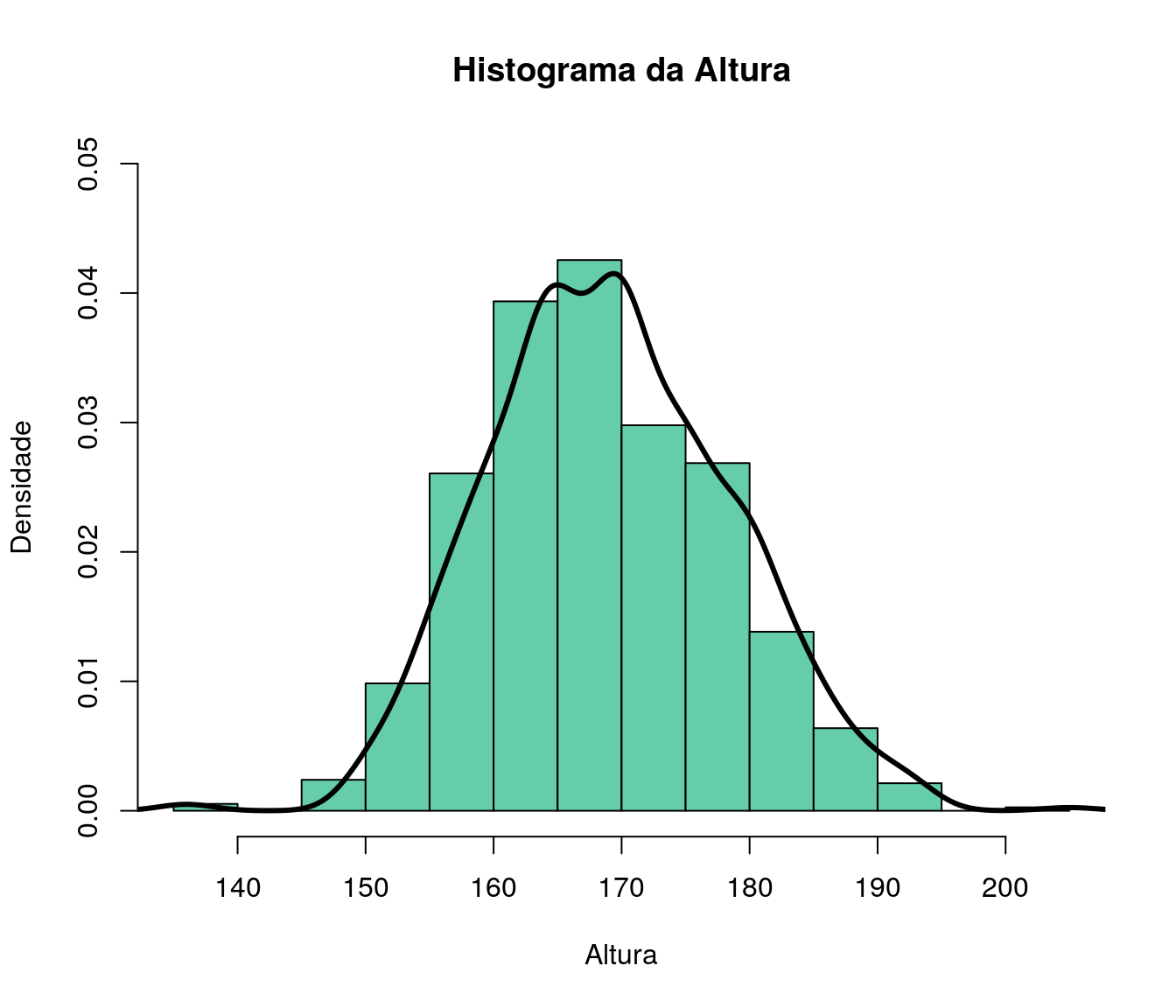
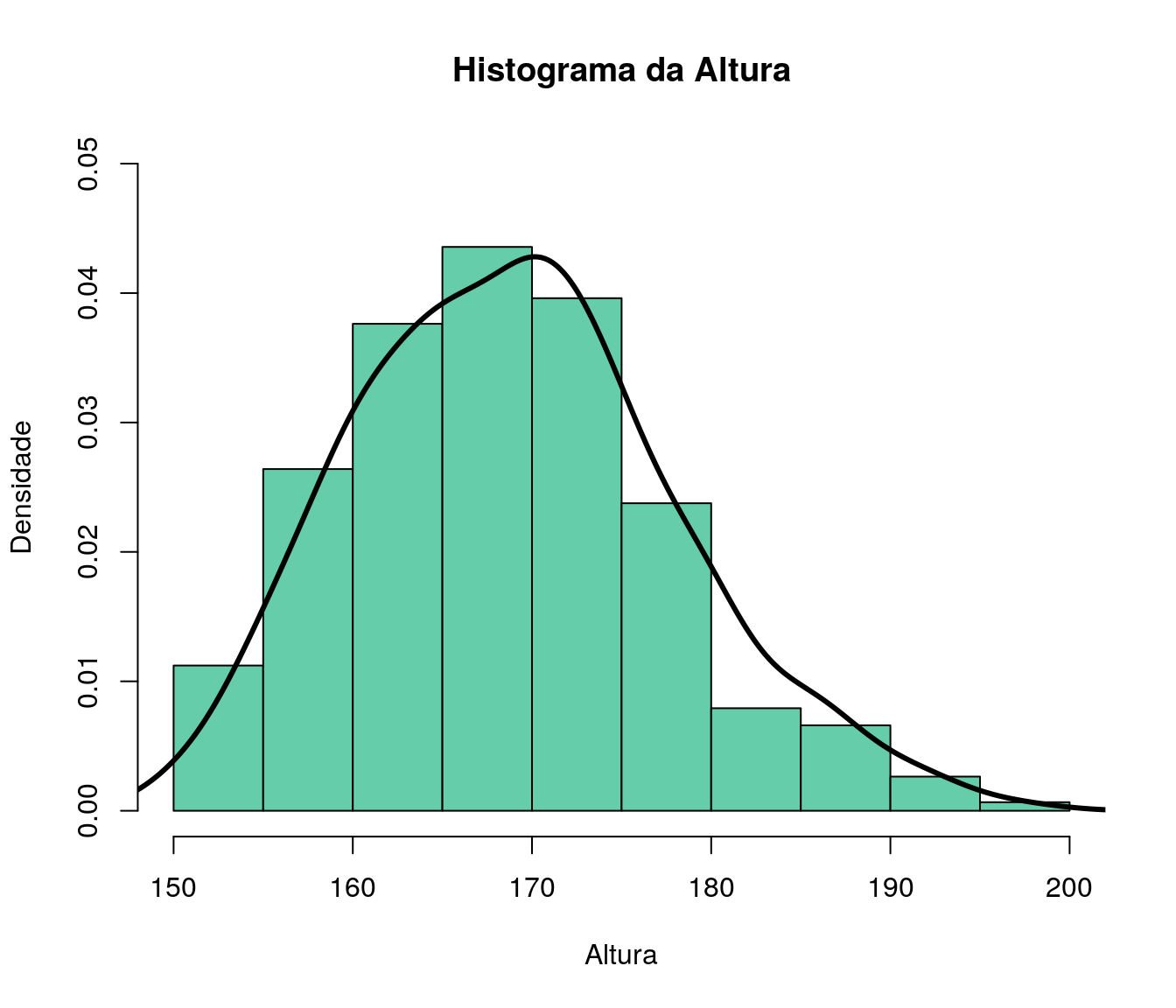
Qual o seu peso?
Tabela 1
Sem tratamento
quest$tc_peso <- as.integer(quest$tc_peso)
h <- hist(quest$tc_peso, plot = FALSE)
breaks <- h$breaks
classes <- cut(quest$tc_peso, breaks = breaks,
include.lowest = TRUE, right = TRUE)
tb.peso <- as.data.frame(table(classes))
tb.peso$Perc <- 100 * prop.table(tb.peso$Freq)
names(tb.peso)[1] <- "Peso"
pander:::pander(tb.peso)| Peso | Freq | Perc |
|---|---|---|
| [0,1e+03] | 751 | 99.87 |
| (1e+03,2e+03] | 0 | 0 |
| (2e+03,3e+03] | 0 | 0 |
| (3e+03,4e+03] | 0 | 0 |
| (4e+03,5e+03] | 0 | 0 |
| (5e+03,6e+03] | 0 | 0 |
| (6e+03,7e+03] | 0 | 0 |
| (7e+03,8e+03] | 0 | 0 |
| (8e+03,9e+03] | 0 | 0 |
| (9e+03,1e+04] | 0 | 0 |
| (1e+04,1.1e+04] | 0 | 0 |
| (1.1e+04,1.2e+04] | 1 | 0.133 |
Tabela 2
Com tratamento
quest$tc_peso <- as.integer(quest$tc_peso)
peso <- subset(quest$tc_peso, quest$tc_peso>0 & quest$tc_peso<200)
h <- hist(peso, plot = FALSE)
breaks <- h$breaks
classes <- cut(peso, breaks = breaks,
include.lowest = TRUE, right = TRUE)
tb.peso <- as.data.frame(table(classes))
tb.peso$Perc <- 100 * prop.table(tb.peso$Freq)
names(tb.peso)[1] <- "Altura"
pander:::pander(tb.peso)| Altura | Freq | Perc |
|---|---|---|
| [30,40] | 2 | 0.2667 |
| (40,50] | 46 | 6.133 |
| (50,60] | 193 | 25.73 |
| (60,70] | 182 | 24.27 |
| (70,80] | 149 | 19.87 |
| (80,90] | 89 | 11.87 |
| (90,100] | 59 | 7.867 |
| (100,110] | 21 | 2.8 |
| (110,120] | 7 | 0.9333 |
| (120,130] | 0 | 0 |
| (130,140] | 2 | 0.2667 |
Tabela 3
medidas <- data.frame(minimo = quantile(peso)[1],
quart1 = quantile(peso)[2],
media = mean(peso),
mediana = quantile(peso)[3],
moda = names(sort(table(peso),
decreasing = TRUE)[1]),
quart3 = quantile(peso)[4],
max = quantile(peso)[5])
row.names(medidas) <- NULL
pander(medidas)| minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|
| 38 | 59 | 70.91 | 67.5 | 60 | 80 | 140 |
disp <- data.frame(amplitude = diff(range(peso)),
variancia = var(peso),
desv_pad = sd(peso),
coef_var = 100*sd(peso)/mean(peso))
pander(disp)| amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|
| 102 | 251.8 | 15.87 | 22.38 |
Gráfico 1
h <- hist(quest$tc_peso[which(quest$tc_peso > 0 & quest$tc_peso < 200)],
main = "Histograma do Peso", xlab = "Peso",
ylab = "Densidade", col = "cornflowerblue",
probability = FALSE)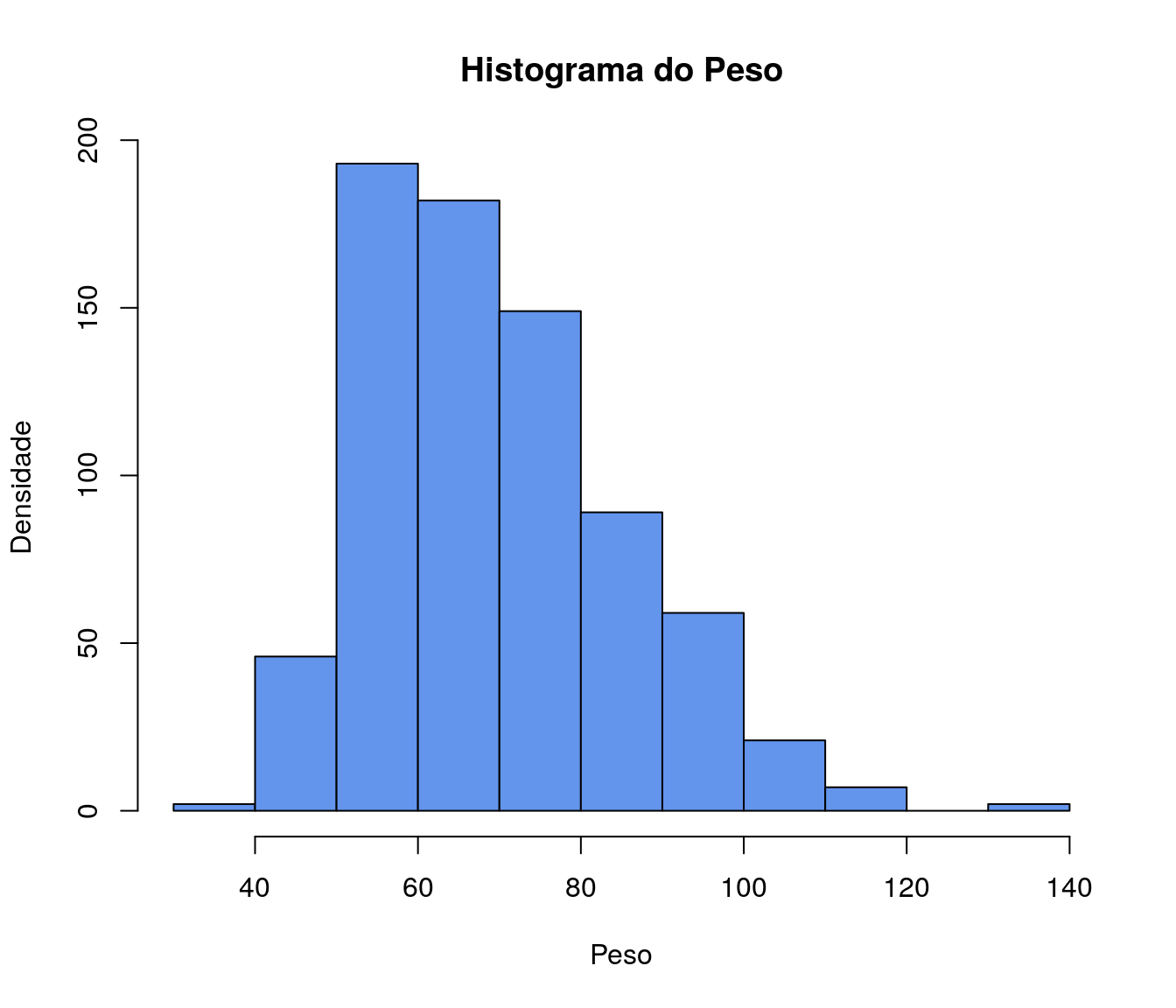
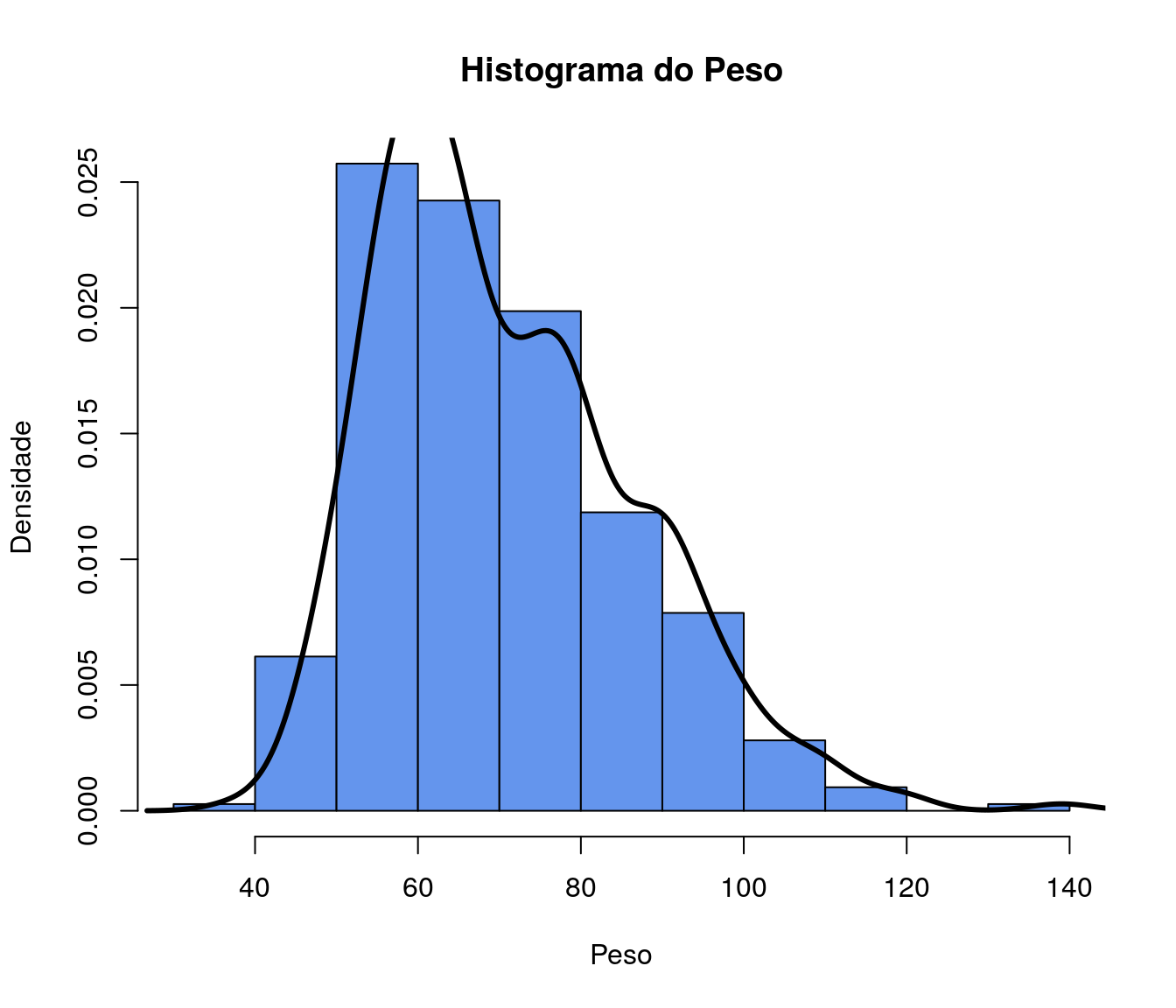
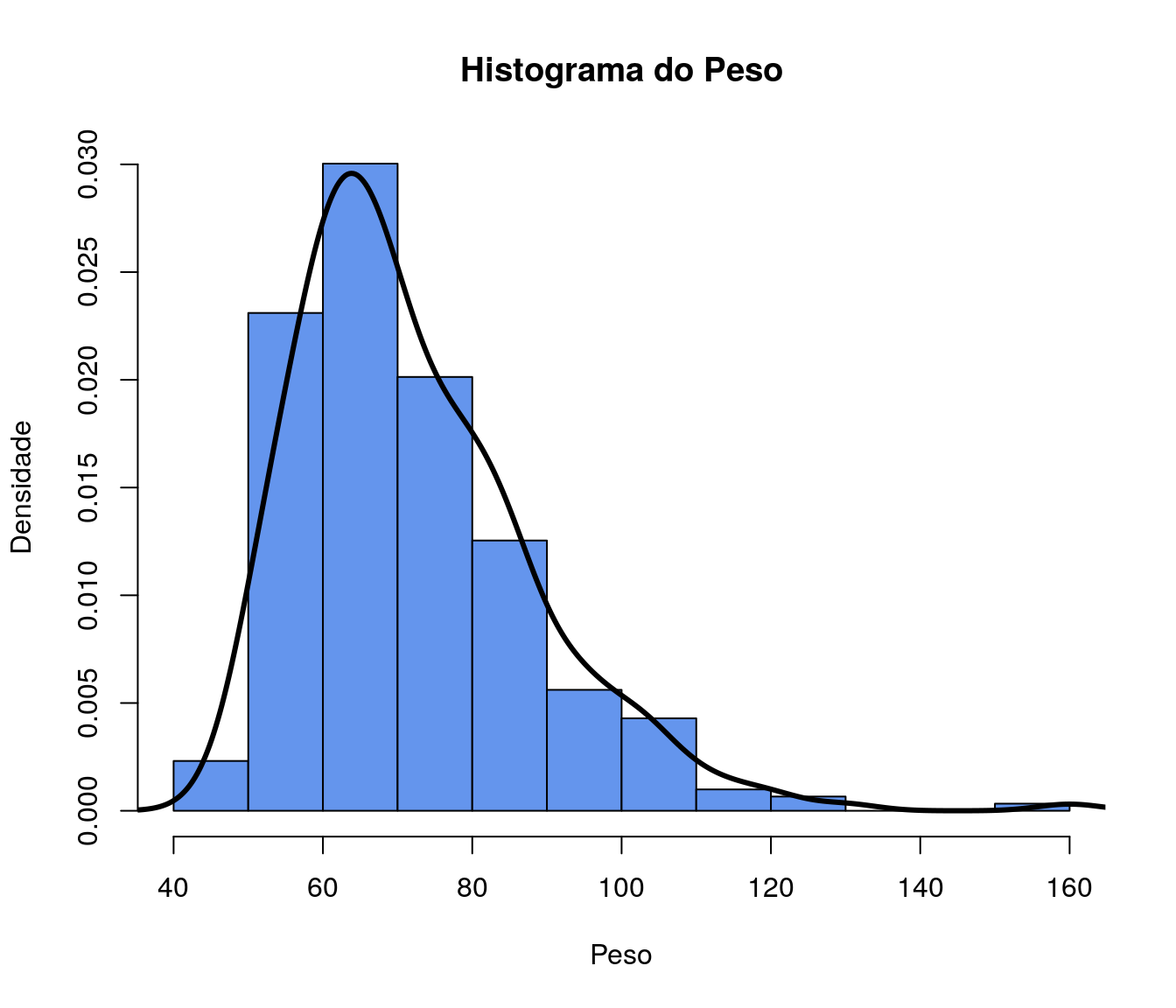
Cálculo do IMC
Tabela 1
quest <- transform(quest, tc_IMC = quest$tc_peso/((quest$tc_altura/100)^2))
imc <- subset(quest$tc_IMC, quest$tc_IMC < 70)
#range(quest$tc_IMC, na.rm = TRUE)
breaks <- c(0, 16, 17, 18.5, 25, 30, 35, 40, range(imc, na.rm = TRUE)[2])
classes <- cut(imc, breaks = breaks,
include.lowest = FALSE, right = FALSE)
tb.imc <- as.data.frame(table(classes))
tb.imc$Perc <- 100 * prop.table(tb.imc$Freq)
names(tb.imc)[1] <- "IMC"
pander:::pander(tb.imc)| IMC | Freq | Perc |
|---|---|---|
| [0,16) | 7 | 0.9346 |
| [16,17) | 4 | 0.534 |
| [17,18.5) | 6 | 0.8011 |
| [18.5,25) | 436 | 58.21 |
| [25,30) | 212 | 28.3 |
| [30,35) | 72 | 9.613 |
| [35,40) | 11 | 1.469 |
| [40,48.3) | 1 | 0.1335 |
Tabela 2
medidas <- data.frame(minimo = quantile(imc)[1],
quart1 = quantile(imc)[2],
media = mean(imc),
mediana = quantile(imc)[3],
moda = names(sort(table(imc),
decreasing = TRUE)[1]),
quart3 = quantile(imc)[4],
max = quantile(imc)[5])
row.names(medidas) <- NULL
pander(medidas)| minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|
| 15.19 | 21.48 | 24.6 | 23.96 | 22.038567493113 | 27.16 | 48.32 |
disp <- data.frame(amplitude = diff(range(imc)),
variancia = var(imc),
desv_pad = sd(imc),
coef_var = 100*sd(imc)/mean(imc))
pander(disp)| amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|
| 33.12 | 17.79 | 4.218 | 17.15 |
Gráfico
h <- hist(imc, breaks = breaks, main = "Histograma do IMC", xlab = "IMC",
ylab = "Densidade", col = "yellow", freq = FALSE, ylim = c(0, 0.10))
lines(density(imc[which(imc > 0)]), lwd = 3)
rug(imc[which(imc > 0)])
xx <- seq(0,60, len=200)
yy <- dnorm(xx, mean=mean(imc[which(imc > 0)], na.rm=T), sd=sd(imc[which(imc > 0)]))
lines(xx, yy, col=2, lwd = 3)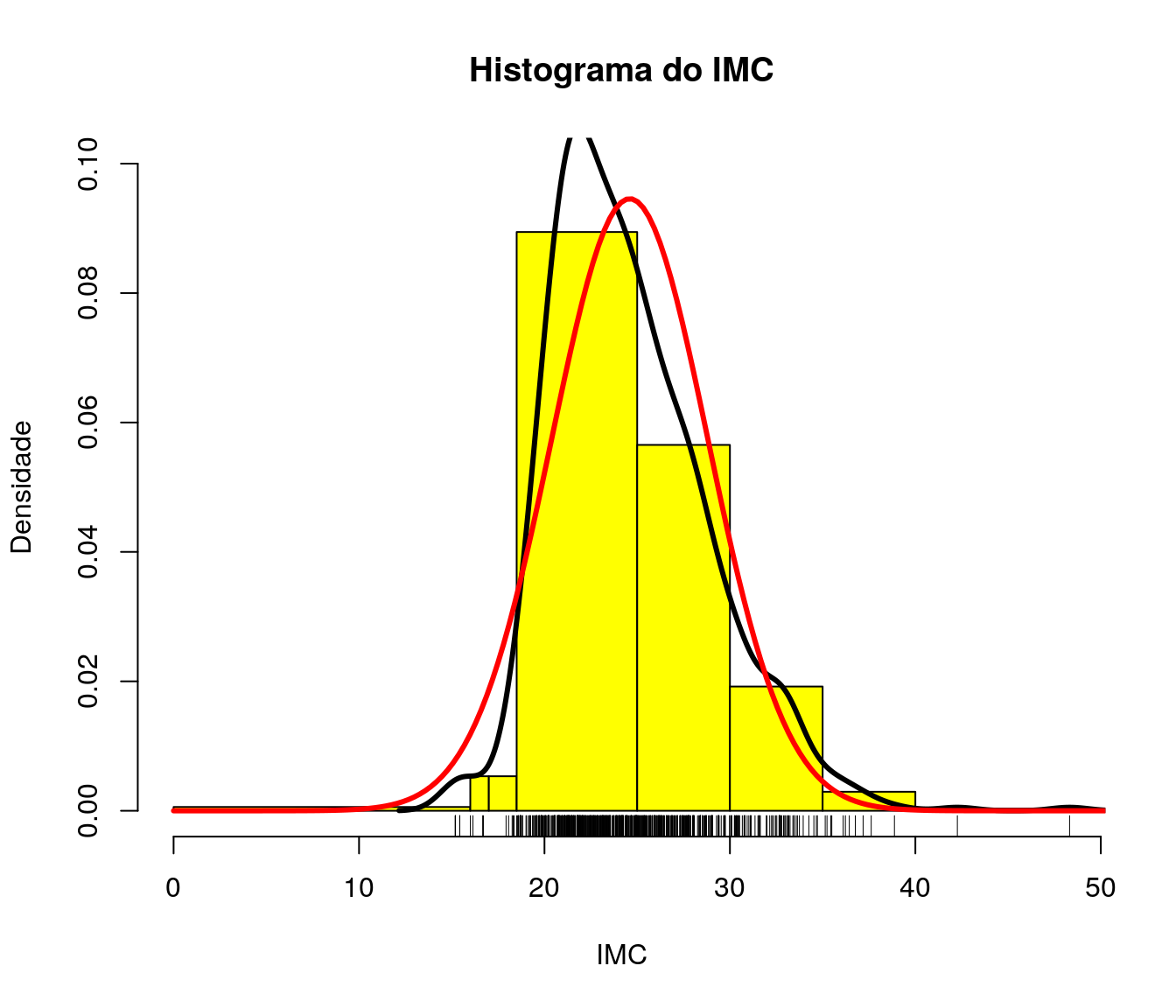
2019
antigo <- transform(antigo, tc_IMC = antigo$tc_peso/((antigo$tc_altura/100)^2))
#range(antigo$tc_IMC, na.rm = TRUE)
breaks <- c(0, 16, 17, 18.5, 25, 30, 35, 40, range(antigo$tc_IMC, na.rm = TRUE)[2])
classes <- cut(antigo$tc_IMC, breaks = breaks,
include.lowest = FALSE, right = FALSE)
tb.imc <- as.data.frame(table(classes))
tb.imc$Perc <- 100 * prop.table(tb.imc$Freq)
names(tb.imc)[1] <- "IMC"
#pander:::pander(tb.imc)
h <- hist(antigo$tc_IMC, breaks = breaks, main = "Histograma do IMC", xlab = "IMC",
ylab = "Densidade", col = "yellow", freq = FALSE, ylim = c(0, 0.10))
lines(density(antigo$tc_IMC[which(antigo$tc_IMC > 0)]), lwd = 3)
rug(antigo$tc_IMC[which(antigo$tc_IMC > 0)])
xx <- seq(0,60, len=200)
yy <- dnorm(xx, mean=mean(antigo$tc_IMC[which(antigo$tc_IMC > 0)], na.rm=T), sd=sd(antigo$tc_IMC[which(antigo$tc_IMC > 0)]))
lines(xx, yy, col=2, lwd = 3)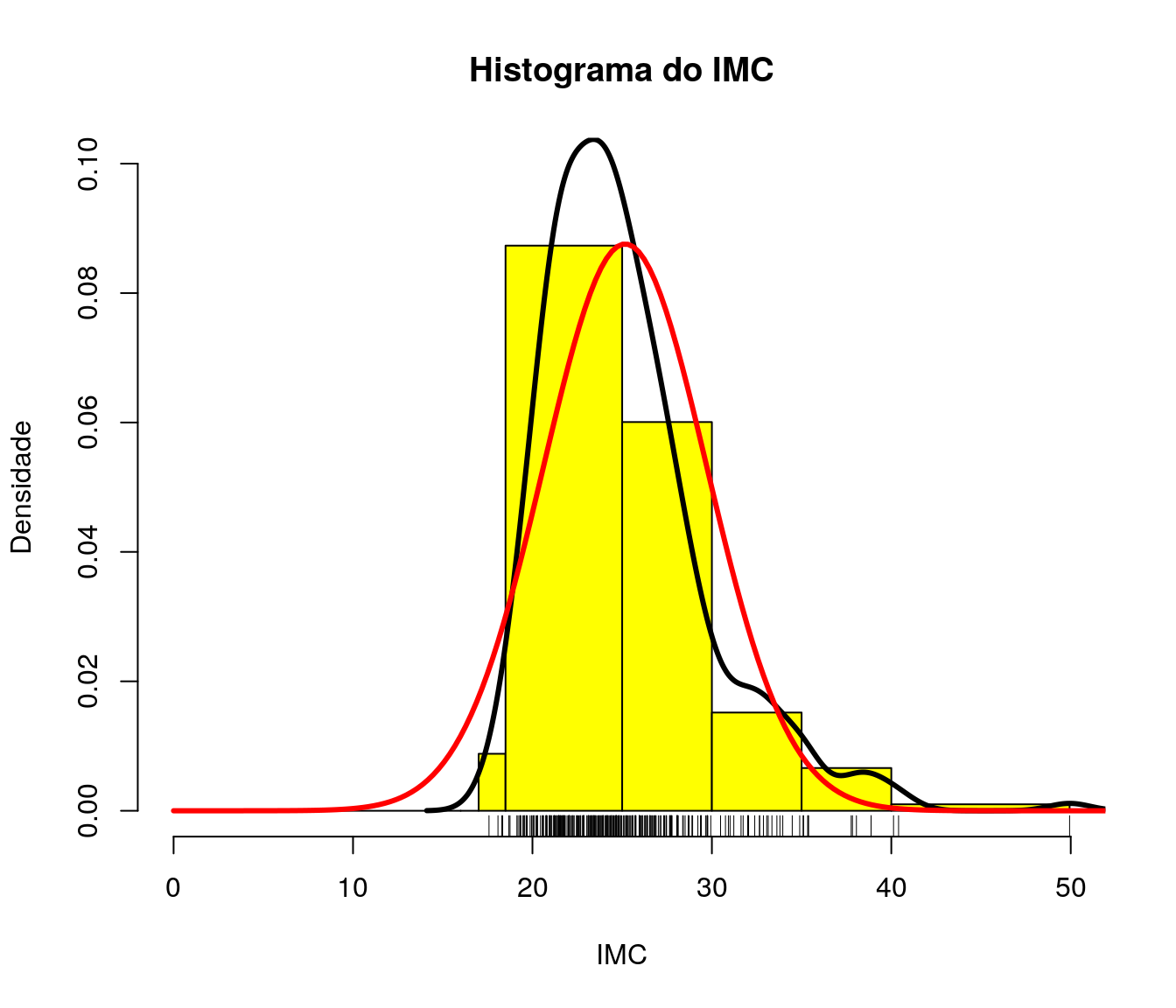
Qual a data do seu nascimento?
Tabela 1
quest$dataNasc <- as.Date(quest$dataNasc, "%d/%m/%Y")
idade <- floor(difftime(Sys.Date(), quest$dataNasc, units = "weeks")/52)
idade <- as.integer(idade)
quest <- transform(quest, tc_idade = idade)
ar_idade <- quest$tc_idade[which(quest$tc_idade > 15 & quest$tc_idade < 100)]
h <- hist(ar_idade, plot = FALSE)
breaks <- h$breaks
classes <- cut(ar_idade, breaks = breaks,
include.lowest = TRUE, right = TRUE)
tb.idade <- as.data.frame(table(classes))
tb.idade$Perc <- 100 * prop.table(tb.idade$Freq)
names(tb.idade)[1] <- "Idade"
pander:::pander(tb.idade)| Idade | Freq | Perc |
|---|---|---|
| [20,25] | 188 | 25.47 |
| (25,30] | 222 | 30.08 |
| (30,35] | 134 | 18.16 |
| (35,40] | 102 | 13.82 |
| (40,45] | 47 | 6.369 |
| (45,50] | 24 | 3.252 |
| (50,55] | 15 | 2.033 |
| (55,60] | 6 | 0.813 |
Tabela 2
medidas <- data.frame(minimo = quantile(ar_idade)[1],
quart1 = quantile(ar_idade)[2],
media = mean(ar_idade),
mediana = quantile(ar_idade)[3],
moda = names(sort(table(ar_idade),
decreasing = TRUE)[1]),
quart3 = quantile(ar_idade)[4],
max = quantile(ar_idade)[5])
row.names(medidas) <- NULL
pander(medidas)| minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|
| 21 | 25 | 31.44 | 29 | 25 | 36 | 58 |
disp <- data.frame(amplitude = diff(range(ar_idade)),
variancia = var(ar_idade),
desv_pad = sd(ar_idade),
coef_var = 100*sd(ar_idade)/mean(ar_idade))
pander(disp)| amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|
| 37 | 58.21 | 7.63 | 24.27 |
Gráfico 1
Variável sem tratamento
plot(table(quest$tc_idade), t = "h", xlab = "Idade", ylab = "Frequência", lwd = 3,
cex.axis = 0.8,
main = "Idade")
Gráfico 2
Variável com tratamento
plot(table(ar_idade), t = "h", xlab = "Idade", ylab = "Frequência", lwd = 3, cex.axis = 0.8,
main = "Idade")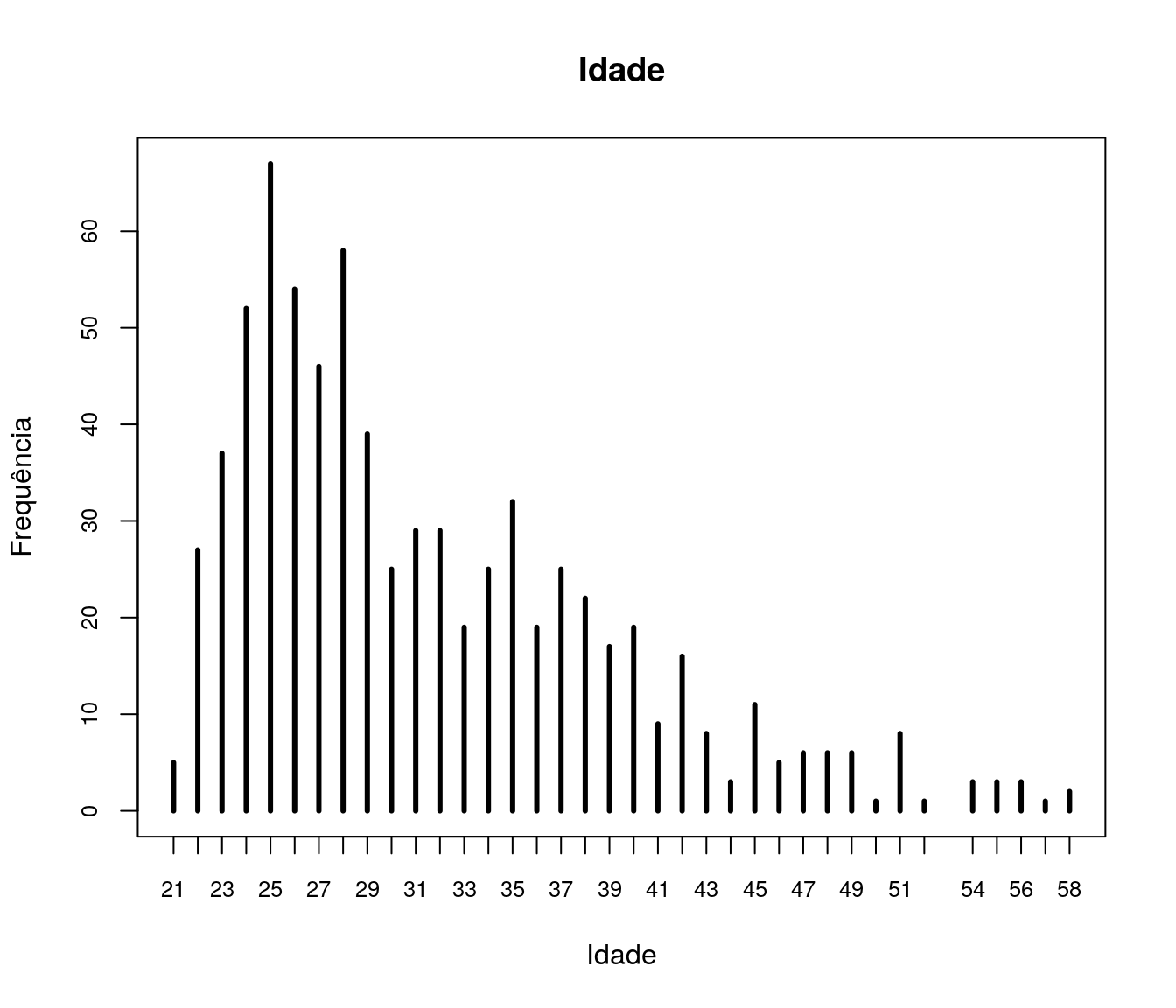
Gráfico 3
hist(ar_idade, breaks = breaks, include.lowest = TRUE, col = "#D8F6CE",
main = "Idade", xlab = "Idade", ylab = "Frequência")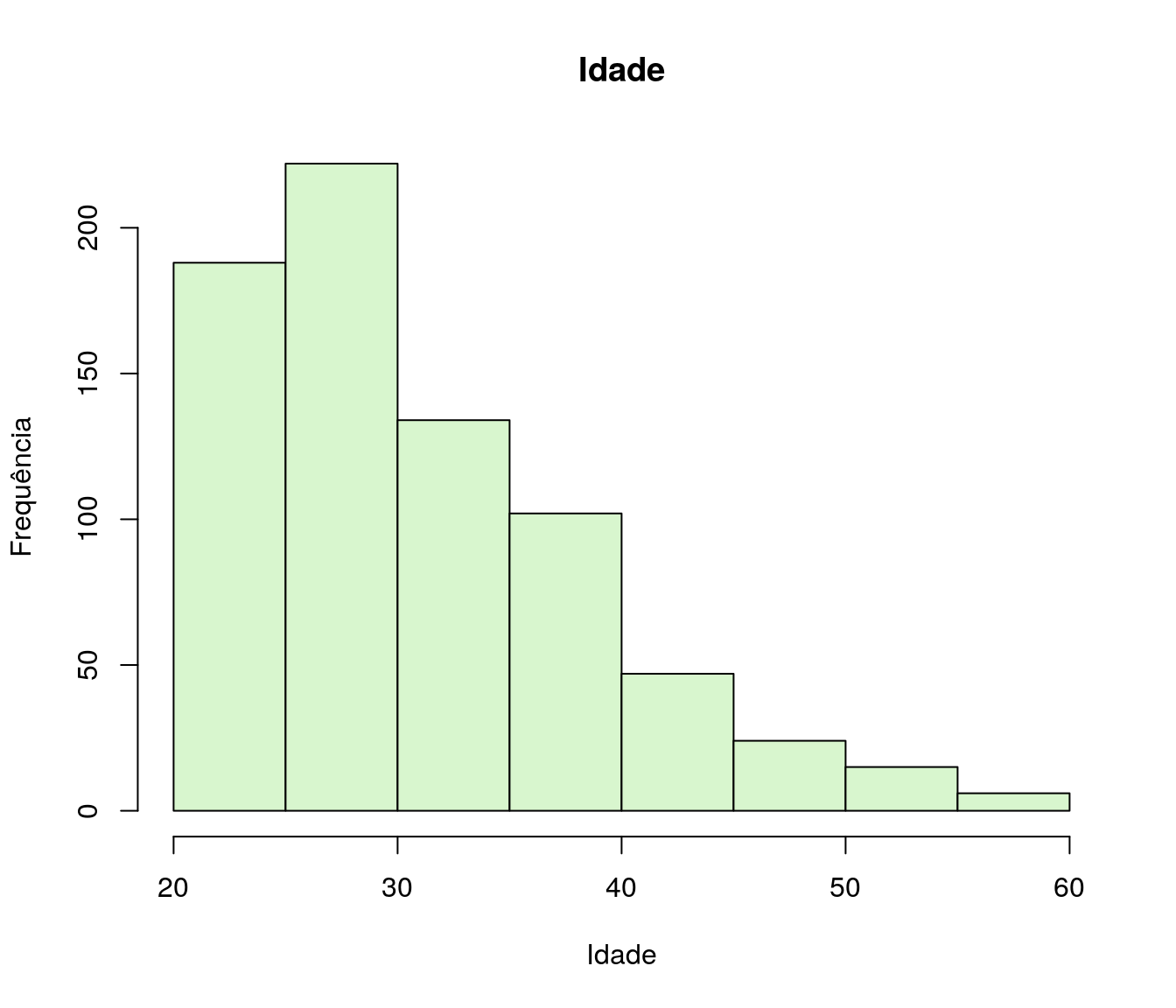
2019
antigo$dataNasc <- as.Date(antigo$dataNasc, "%d/%m/%Y")
idade <- floor(difftime(Sys.Date(), antigo$dataNasc, units = "weeks")/52)
idade <- as.integer(idade)
antigo <- transform(antigo, tc_idade = idade)
ar_idade <- antigo$tc_idade[which(antigo$tc_idade > 15)]
h <- hist(ar_idade, plot = FALSE)
breaks <- h$breaks
classes <- cut(ar_idade, breaks = breaks,
include.lowest = TRUE, right = TRUE)
tb.idade <- as.data.frame(table(classes))
tb.idade$Perc <- 100 * prop.table(tb.idade$Freq)
names(tb.idade)[1] <- "Idade"
#pander:::pander(tb.idade)
hist(ar_idade, breaks = breaks, include.lowest = TRUE, col = "#D8F6CE",
main = "Idade", xlab = "Idade", ylab = "Frequência")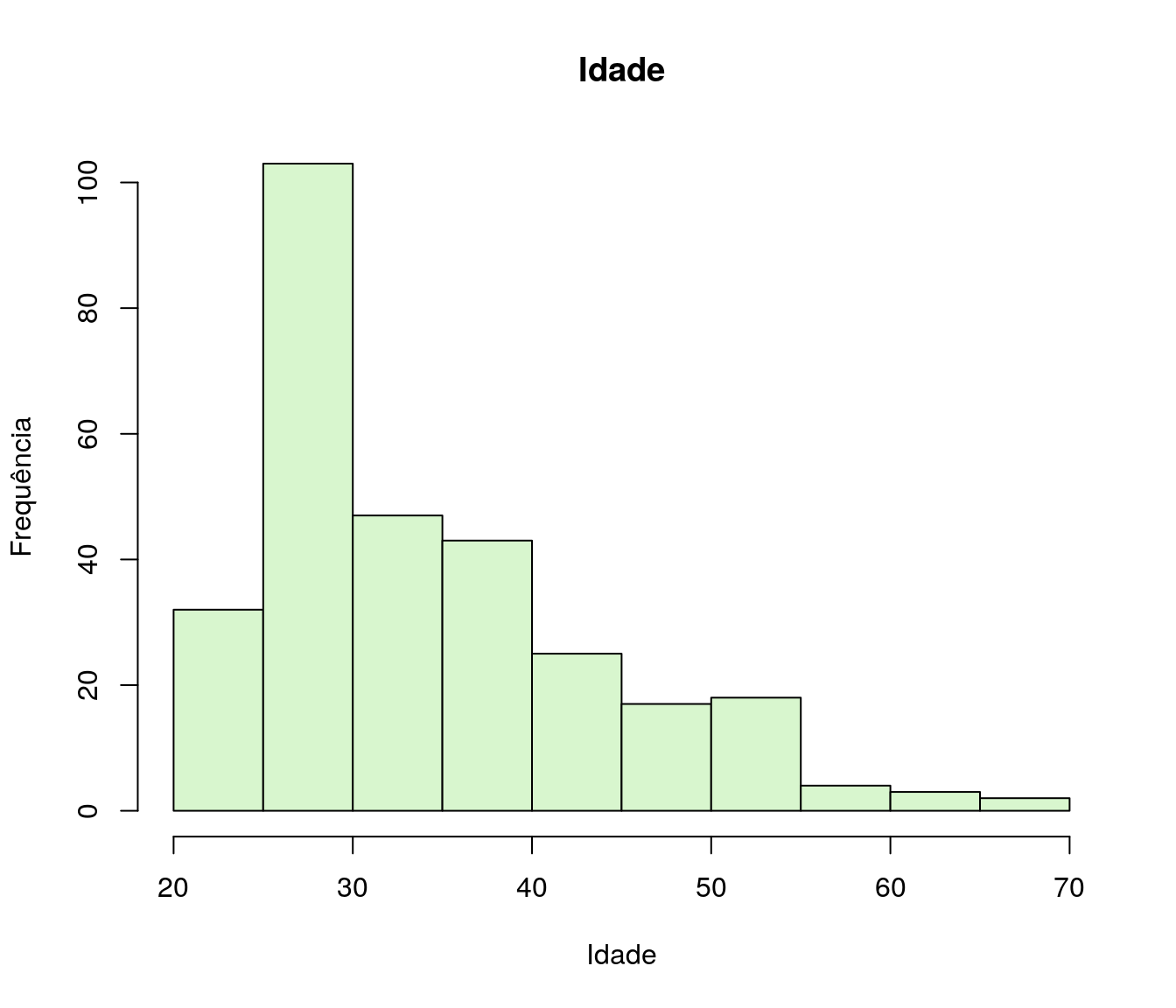
Tabela 3
Meses de aniversário
mes <- month(as.POSIXlt(quest$dataNasc, format="%d-%m-%Y"))
fa_mes <- table(mes) # frequência absoluta
fr_mes <- prop.table(fa_mes) # frequência relativa
fac_mes <- cumsum(fr_mes) # frequência acumulada
mes <- data.frame(niveis = names(fa_mes),
freq = as.vector(fa_mes),
freq_r = as.vector(fr_mes),
freq_ac = as.vector(fac_mes)) # unindo as informações
pander:::pander(mes) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| 1 | 55 | 0.07314 | 0.07314 |
| 2 | 56 | 0.07447 | 0.1476 |
| 3 | 57 | 0.0758 | 0.2234 |
| 4 | 62 | 0.08245 | 0.3059 |
| 5 | 57 | 0.0758 | 0.3816 |
| 6 | 60 | 0.07979 | 0.4614 |
| 7 | 66 | 0.08777 | 0.5492 |
| 8 | 63 | 0.08378 | 0.633 |
| 9 | 66 | 0.08777 | 0.7207 |
| 10 | 67 | 0.0891 | 0.8098 |
| 11 | 75 | 0.09973 | 0.9096 |
| 12 | 68 | 0.09043 | 1 |
Gráfico 4
plot(mes$freq, t = "h", xlab = "Mês",
ylab = "Frequência", lwd = 6,
ylim = c(0,max(mes$freq+10)),
cex.axis = 0.8,main = "Mês de Aniversário")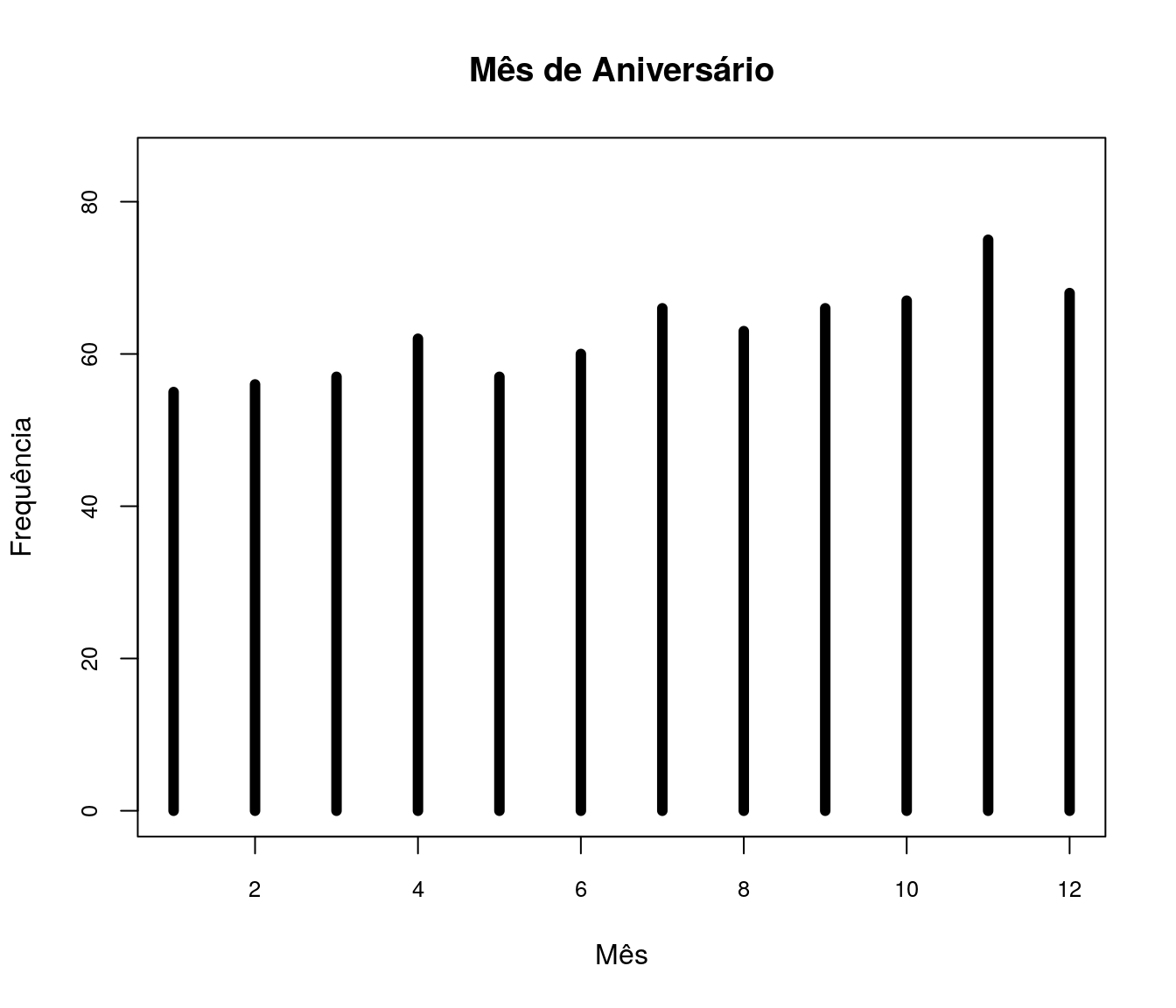
2019
mes <- month(as.POSIXlt(antigo$dataNasc, format="%d-%m-%Y"))
fa_mes <- table(mes) # frequência absoluta
fr_mes <- prop.table(fa_mes) # frequência relativa
fac_mes <- cumsum(fr_mes) # frequência acumulada
mes <- data.frame(niveis = names(fa_mes),
freq = as.vector(fa_mes),
freq_r = as.vector(fr_mes),
freq_ac = as.vector(fac_mes)) # unindo as informações
#pander:::pander(mes) # gerando a tabela
plot(mes$freq, t = "h", xlab = "Mês",
ylab = "Frequência", lwd = 6,
ylim = c(0, max(mes$freq)+10),
cex.axis = 0.8,main = "Mês de Aniversário")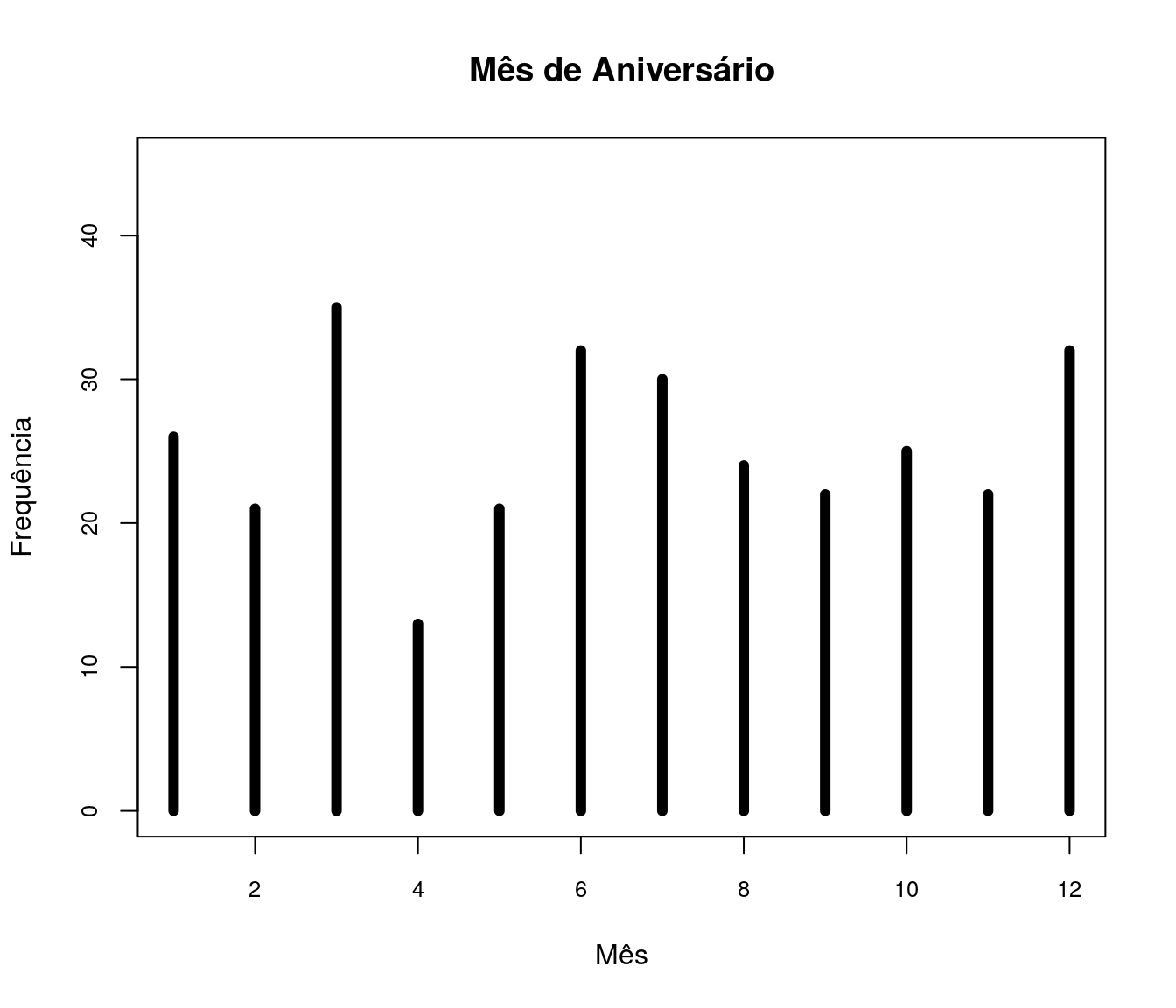
Qual das seguintes categorias descreve melhor sua situação de emprego?
Tabela
quest$ln_tipoTrab <- tolower(iconv(quest$ln_tipoTrab,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- c("trabalho com carteira assinada/vinculo formal",
"trabalho ocasional", "trabalho por contrato",
"bolsista em tempo integral")
quest$ln_tipoTrab[ !quest$ln_tipoTrab %in% classOpcoes ] <- "outro"
quest$ln_tipoTrab <- factor(quest$ln_tipoTrab,
levels = c("trabalho com carteira assinada/vinculo formal",
"trabalho ocasional", "trabalho por contrato",
"bolsista em tempo integral", "outro"))
fa_trab <- table(quest$ln_tipoTrab) # frequência absoluta
fr_trab <- prop.table(fa_trab) # frequência relativa
fac_trab <- cumsum(fr_trab) # frequência acumulada
trab <- data.frame(niveis = names(fa_trab),
freq = as.vector(fa_trab),
freq_r = as.vector(fr_trab),
freq_ac = as.vector(fac_trab)) # unindo as informações
pander:::pander(trab) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| trabalho com carteira assinada/vinculo formal | 224 | 0.2979 | 0.2979 |
| trabalho ocasional | 55 | 0.07314 | 0.371 |
| trabalho por contrato | 44 | 0.05851 | 0.4295 |
| bolsista em tempo integral | 293 | 0.3896 | 0.8191 |
| outro | 136 | 0.1809 | 1 |
Gráfico
trab$niveis <- c("Vínc.Formal", "Trab.Ocasional",
"Trab.Contrato", "Bolsista",
"Outro")
trab_ord <- arrange(trab, trab$freq)
barplot(trab_ord$freq,
#names.arg = trab_ord$niveis,
col = paleta,
main = 'Trabalho',
ylab = 'Frequência',
xlab = '',
ylim = c(0, max(trab_ord$freq)+30)
#horiz = T,
#las=2,
)
legend("topleft",
legend = trab_ord$niveis,
fill = paleta,
cex = .8)
text(x = as.vector(barplot(trab_ord$freq, plot = FALSE)),
y = as.vector(trab_ord$freq) + 10,
labels = trab_ord$freq, cex = 1)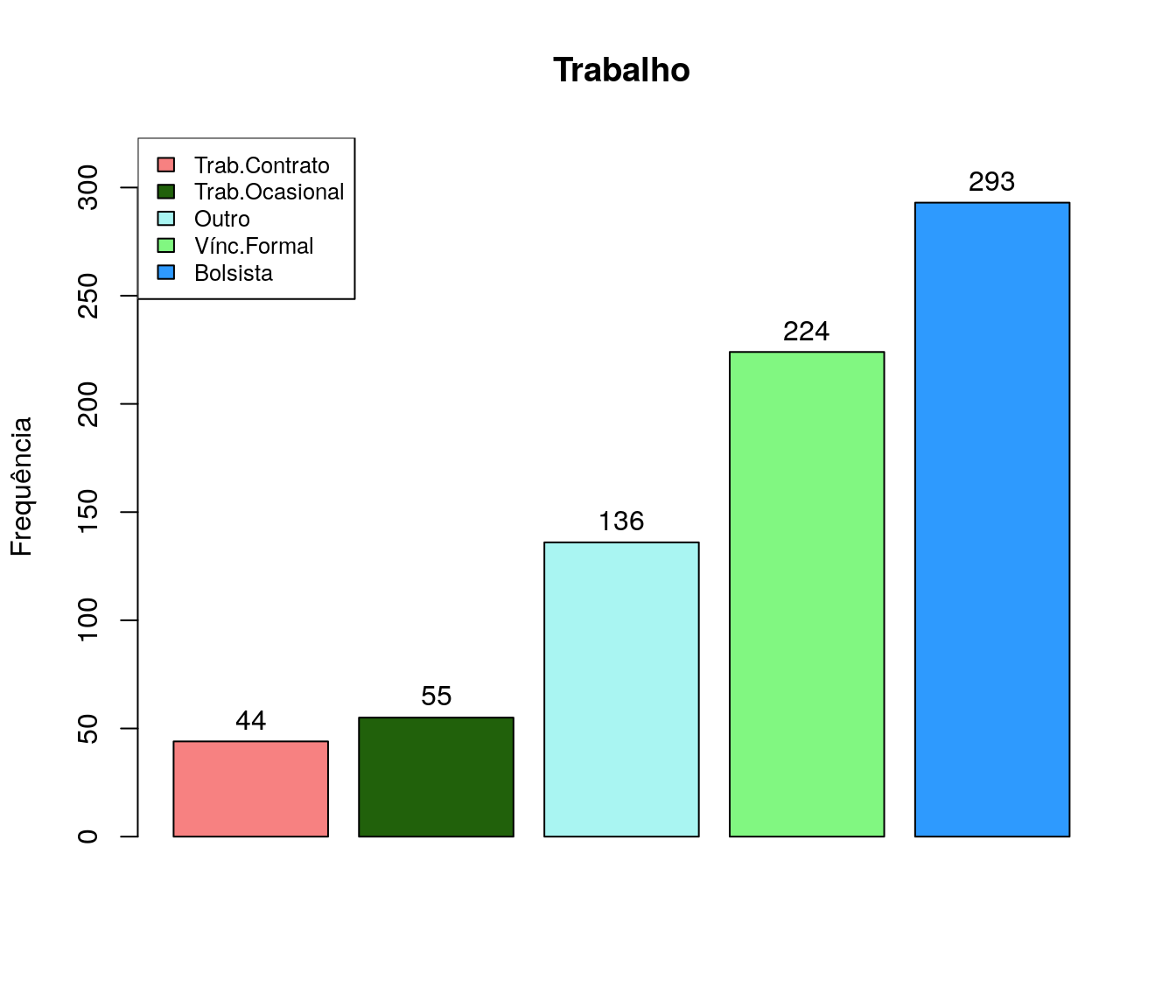
2019
antigo$ln_tipoTrab <- tolower(iconv(antigo$ln_tipoTrab,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- c("trabalho com carteira assinada/vinculo formal",
"trabalho ocasional", "trabalho por contrato",
"bolsista em tempo integral")
antigo$ln_tipoTrab[ !antigo$ln_tipoTrab %in% classOpcoes ] <- "outro"
antigo$ln_tipoTrab <- factor(antigo$ln_tipoTrab,
levels = c("trabalho com carteira assinada/vinculo formal",
"trabalho ocasional", "trabalho por contrato",
"bolsista em tempo integral", "outro"))
fa_trab <- table(antigo$ln_tipoTrab) # frequência absoluta
fr_trab <- prop.table(fa_trab) # frequência relativa
fac_trab <- cumsum(fr_trab) # frequência acumulada
trab <- data.frame(niveis = names(fa_trab),
freq = as.vector(fa_trab),
freq_r = as.vector(fr_trab),
freq_ac = as.vector(fac_trab)) # unindo as informações
#pander:::pander(trab) # gerando a tabela
trab$niveis <- c("Vínc.Formal", "Trab.Ocasional",
"Trab.Contrato", "Bolsista",
"Outro")
trab_ord <- arrange(trab, trab$freq)
barplot(trab_ord$freq,
#names.arg = trab_ord$niveis,
col = paleta,
main = 'Trabalho',
ylab = 'Frequência',
xlab = '',
ylim = c(0, max(trab_ord$freq)+30)
#horiz = T,
#las=2,
)
legend("topleft",
legend = trab_ord$niveis,
fill = paleta,
cex = .8)
text(x = as.vector(barplot(trab_ord$freq, plot = FALSE)),
y = as.vector(trab_ord$freq) + 10,
labels = trab_ord$freq, cex = 1)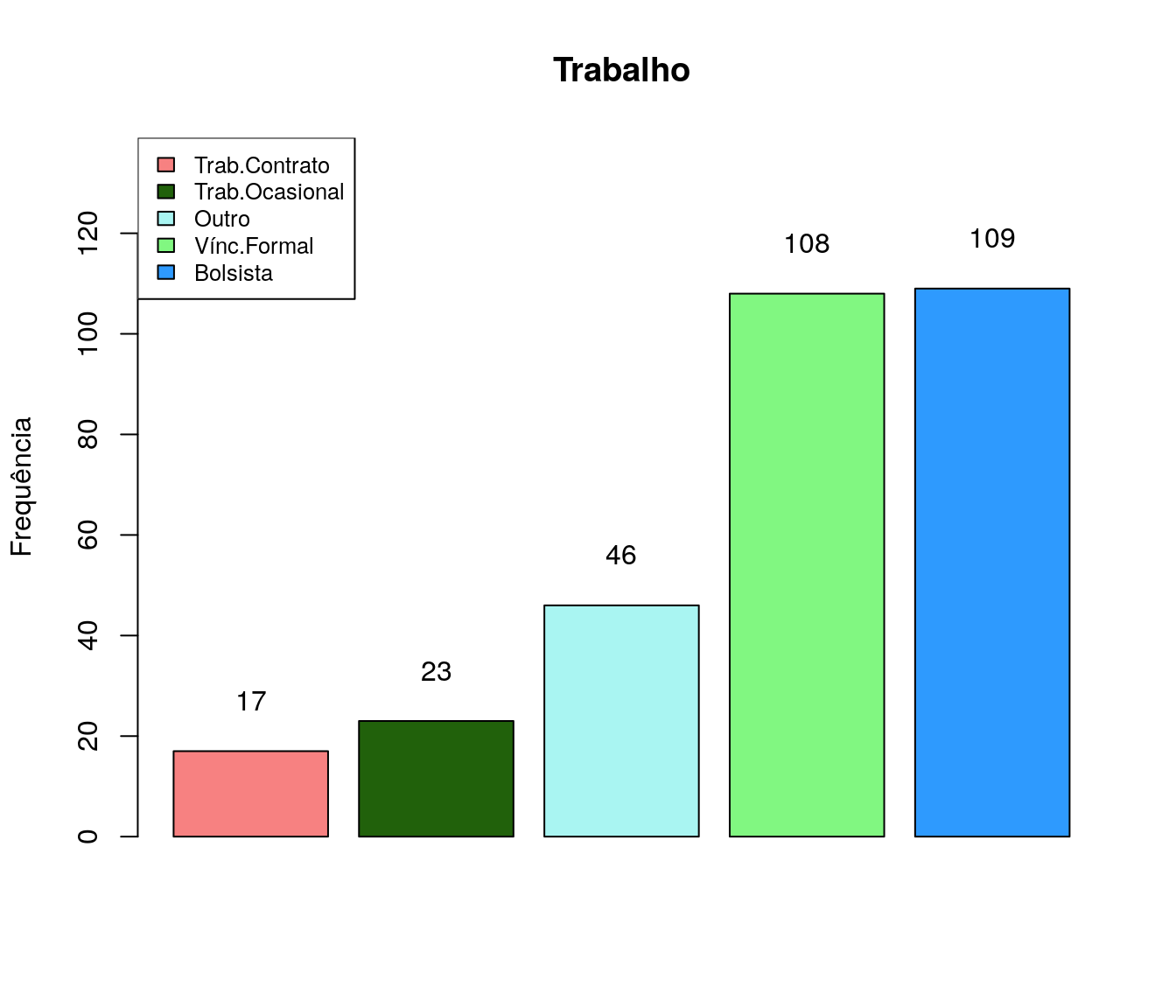
Você mora
Tabela
quest$ln_compMoradia <- tolower(iconv(quest$ln_compMoradia,
to ='ASCII//TRANSLIT', from = "UTF-8"))
quest$ln_compMoradia <- factor(quest$ln_compMoradia,
levels = c("com os pais", "com outros familiares", "com amigos",
"com o namorado(a)/noivo(a)/conjuge",
"pensao, quarto alugado ou algo similar", "sozinho"))
fa_mor <- table(quest$ln_compMoradia) # frequência absoluta
fr_mor <- prop.table(fa_mor) # frequência relativa
fac_mor <- cumsum(fr_mor) # frequência acumulada
mor <- data.frame(niveis = names(fa_mor),
freq = as.vector(fa_mor),
freq_r = as.vector(fr_mor),
freq_ac = as.vector(fac_mor)) # unindo as informações
pander:::pander(mor) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| com os pais | 183 | 0.2434 | 0.2434 |
| com outros familiares | 60 | 0.07979 | 0.3231 |
| com amigos | 46 | 0.06117 | 0.3843 |
| com o namorado(a)/noivo(a)/conjuge | 286 | 0.3803 | 0.7646 |
| pensao, quarto alugado ou algo similar | 56 | 0.07447 | 0.8391 |
| sozinho | 121 | 0.1609 | 1 |
Gráfico
mor$niveis <- c("Pais", "Familia",
"Amigos", "Cônjuge",
"Pensão", "Sozinho")
mor_ord <- arrange(mor, mor$freq)
barplot(mor_ord$freq, col = '#0B243B',
names.arg = mor_ord$niveis, horiz = T,
xlim = c(0, max(mor_ord$freq + 30)),
main = "Moradia",
las = 2)
text(y = as.vector(barplot(mor_ord$freq, plot = FALSE)),
x = as.vector(mor_ord$freq) + 10,
labels = mor_ord$freq, cex = 1)
abline(v=50, lty=3, col = '#FFFFFF')
abline(v=100, lty=3, col = '#FFFFFF')
abline(v=150, lty=3, col = '#FFFFFF')
abline(v=200, lty=3, col = '#FFFFFF')
abline(v=250, lty=3, col = '#FFFFFF')
abline(v=350, lty=3, col = '#FFFFFF')
abline(v=400, lty=3, col = '#FFFFFF')
abline(v=450, lty=3, col = '#FFFFFF')
abline(v=500, lty=3, col = '#FFFFFF')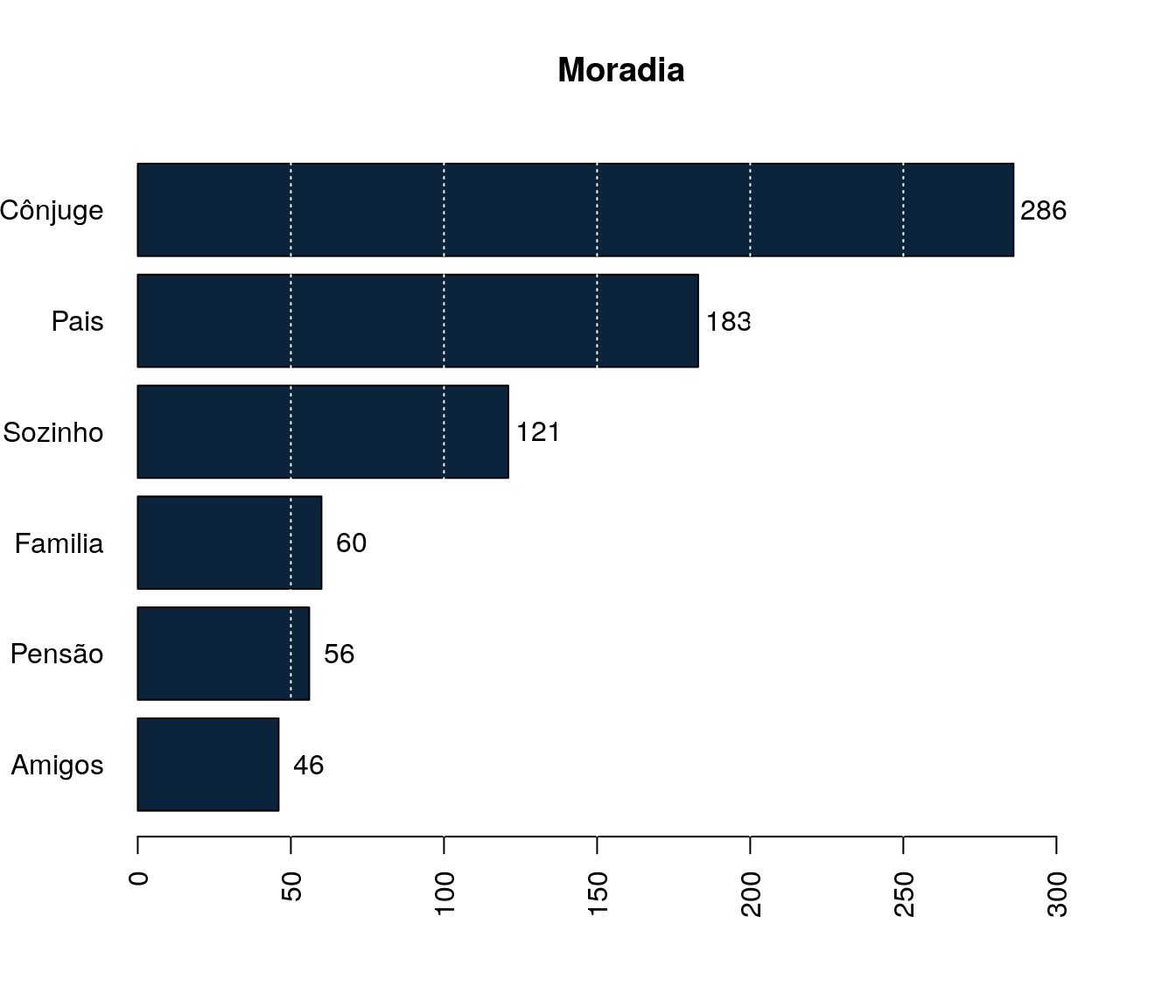
2019
antigo$ln_compMoradia <- tolower(iconv(antigo$ln_compMoradia,
to ='ASCII//TRANSLIT', from = "UTF-8"))
antigo$ln_compMoradia <- factor(antigo$ln_compMoradia,
levels = c("com os pais", "com outros familiares", "com amigos",
"com o namorado(a)/noivo(a)/conjuge",
"pensao, quarto alugado ou algo similar", "sozinho"))
fa_mor <- table(antigo$ln_compMoradia) # frequência absoluta
fr_mor <- prop.table(fa_mor) # frequência relativa
fac_mor <- cumsum(fr_mor) # frequência acumulada
mor <- data.frame(niveis = names(fa_mor),
freq = as.vector(fa_mor),
freq_r = as.vector(fr_mor),
freq_ac = as.vector(fac_mor)) # unindo as informações
#pander:::pander(mor) # gerando a tabela
mor$niveis <- c("Pais", "Familia",
"Amigos", "Cônjuge",
"Pensão", "Sozinho")
mor_ord <- arrange(mor, mor$freq)
barplot(mor_ord$freq, col = '#0B243B',
names.arg = mor_ord$niveis, horiz = T,
xlim = c(0, max(mor_ord$freq + 30)),
main = "Moradia",
las = 2)
text(y = as.vector(barplot(mor_ord$freq, plot = FALSE)),
x = as.vector(mor_ord$freq) + 10,
labels = mor_ord$freq, cex = 1)
abline(v=50, lty=3, col = '#FFFFFF')
abline(v=100, lty=3, col = '#FFFFFF')
abline(v=150, lty=3, col = '#FFFFFF')
abline(v=200, lty=3, col = '#FFFFFF')
abline(v=250, lty=3, col = '#FFFFFF')
abline(v=300, lty=3, col = '#FFFFFF')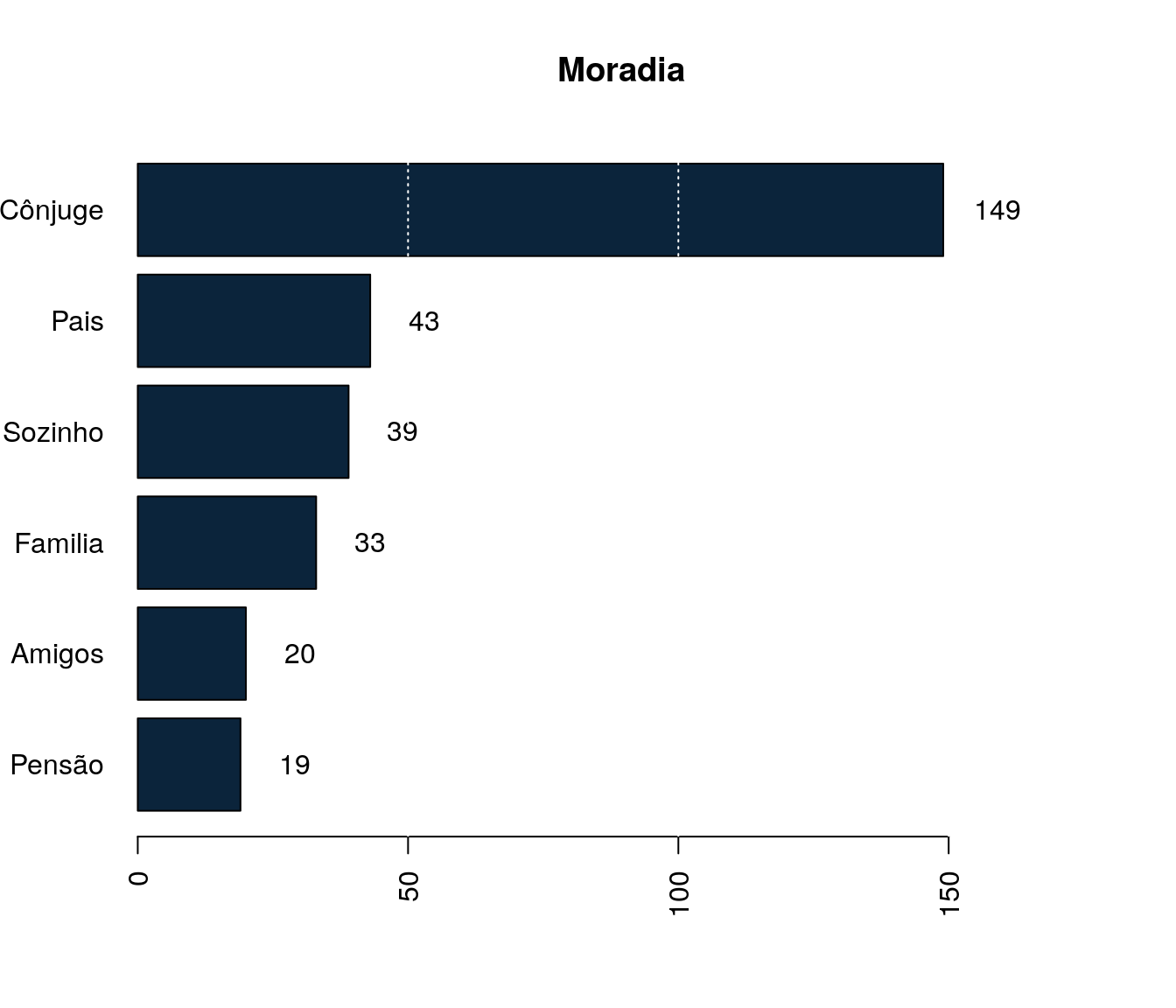
Quantos irmãos você tem?
Tabela 1
quest$td_numIrmao <- as.integer(quest$td_numIrmao)
tb.numIrmao <- as.data.frame(with(quest, table(td_numIrmao)))
tb.numIrmao$Perc <- 100 * prop.table(tb.numIrmao$Freq)
names(tb.numIrmao)[1] <- "Quant. de Irmãos"
pander:::pander(tb.numIrmao)| Quant. de Irmãos | Freq | Perc |
|---|---|---|
| 0 | 77 | 10.24 |
| 1 | 288 | 38.3 |
| 2 | 213 | 28.32 |
| 3 | 85 | 11.3 |
| 4 | 42 | 5.585 |
| 5 | 24 | 3.191 |
| 6 | 6 | 0.7979 |
| 7 | 8 | 1.064 |
| 8 | 5 | 0.6649 |
| 9 | 3 | 0.3989 |
| 10 | 1 | 0.133 |
Tabela 2
medidas <- data.frame(minimo = quantile(quest$td_numIrmao)[1],
quart1 = quantile(quest$td_numIrmao)[2],
media = mean(quest$td_numIrmao),
mediana = quantile(quest$td_numIrmao)[3],
moda = names(sort(table(quest$td_numIrmao),
decreasing = TRUE)[1]),
quart3 = quantile(quest$td_numIrmao)[4],
max = quantile(quest$td_numIrmao)[5])
row.names(medidas) <- NULL
pander(medidas)| minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|
| 0 | 1 | 1.896 | 2 | 1 | 2 | 10 |
disp <- data.frame(amplitude = diff(range(quest$td_numIrmao)),
variancia = var(quest$td_numIrmao),
desv_pad = sd(quest$td_numIrmao),
coef_var = 100*sd(quest$td_numIrmao)/mean(quest$td_numIrmao))
pander(disp)| amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|
| 10 | 2.322 | 1.524 | 80.36 |
Gráfico 1
plot(table(quest$td_numIrmao), t = "h", xlab = "Quantidade",
ylab = "Frequência",
lwd = 6, cex.axis = 0.8, main = "Número de Irmãos")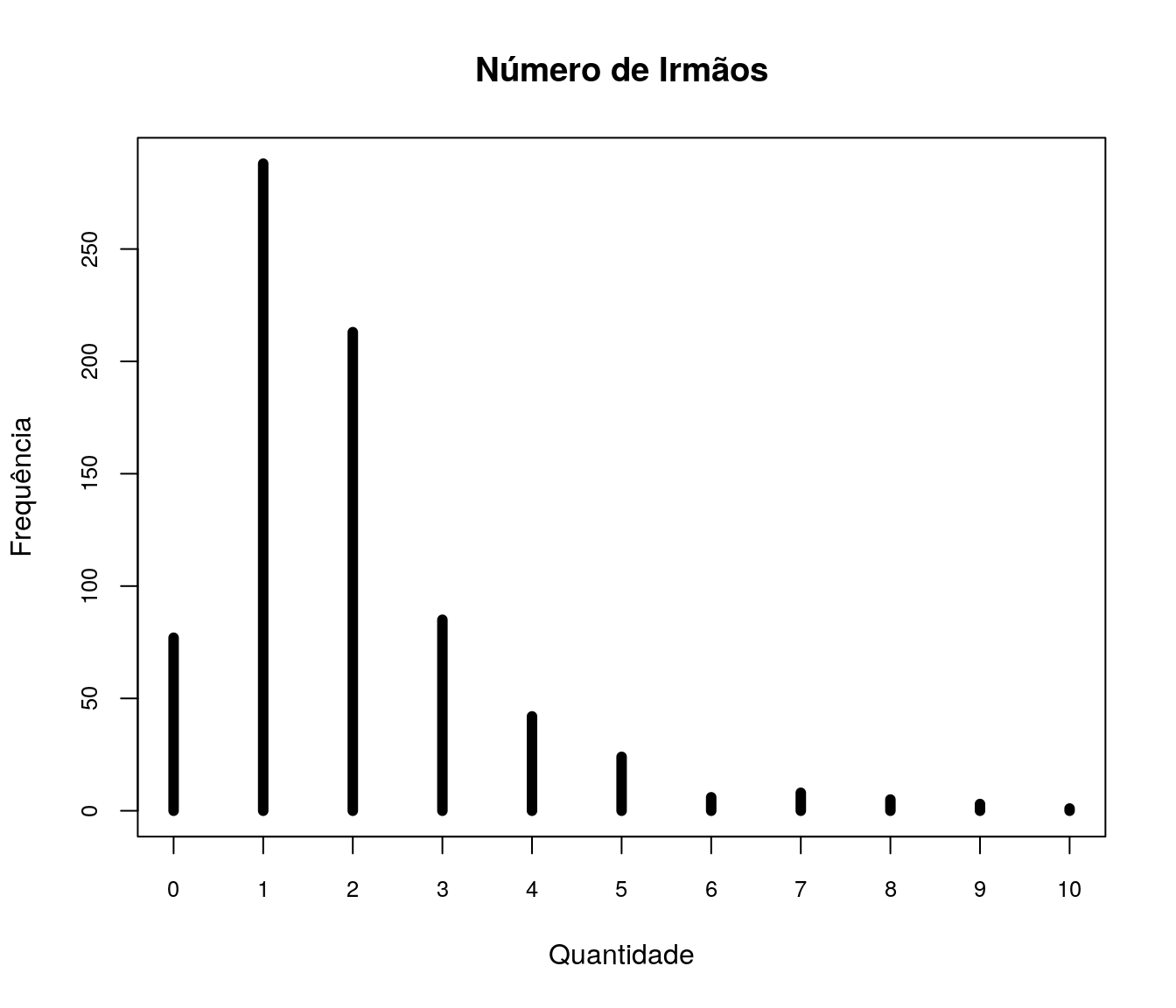
Gráfico 2
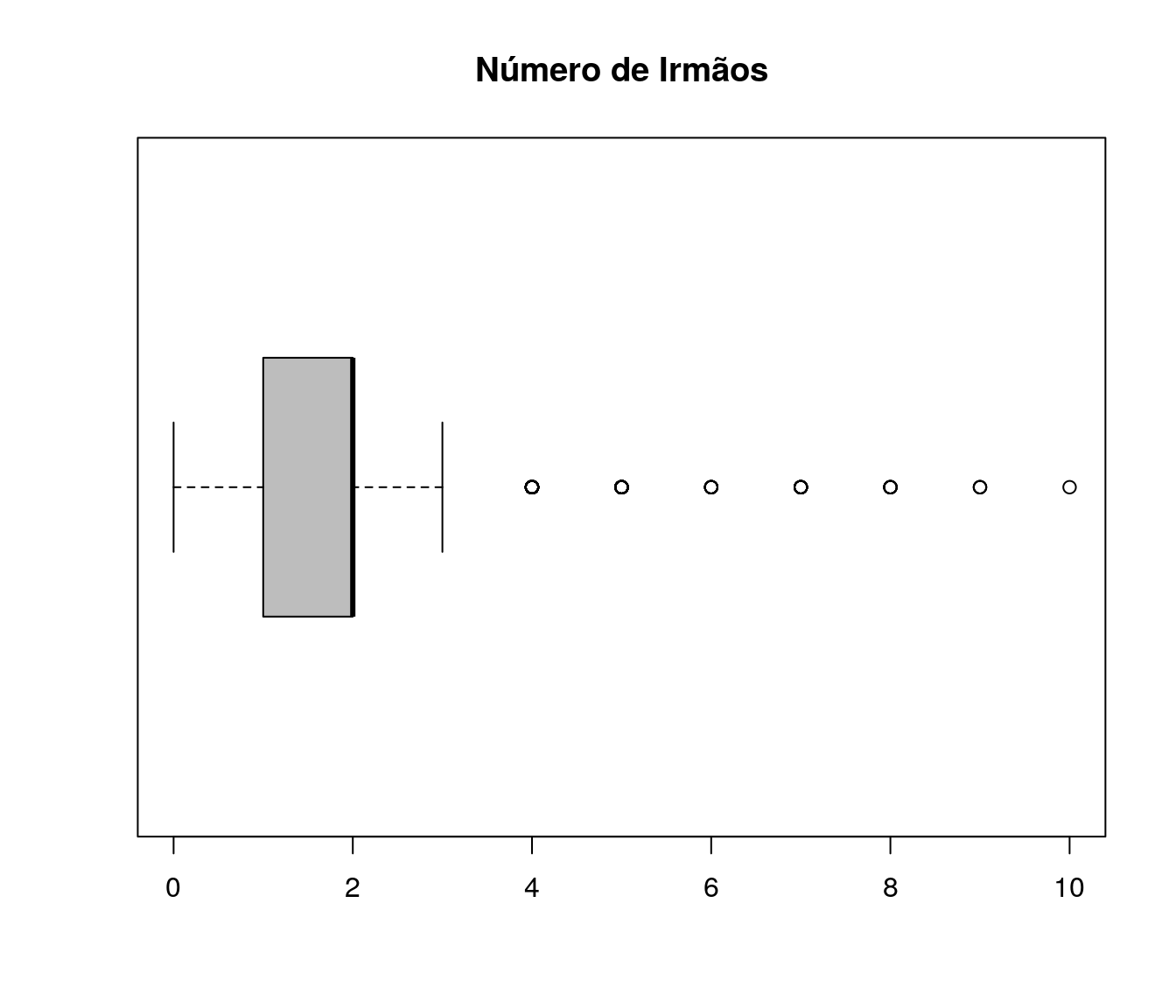
Gráfico 3
with(quest, hist(td_numIrmao, horizontal=T,
col = "#BDBDBD",
main = "Número de Irmãos",
xlab = 'Irmãos',
ylab = 'Frequência'))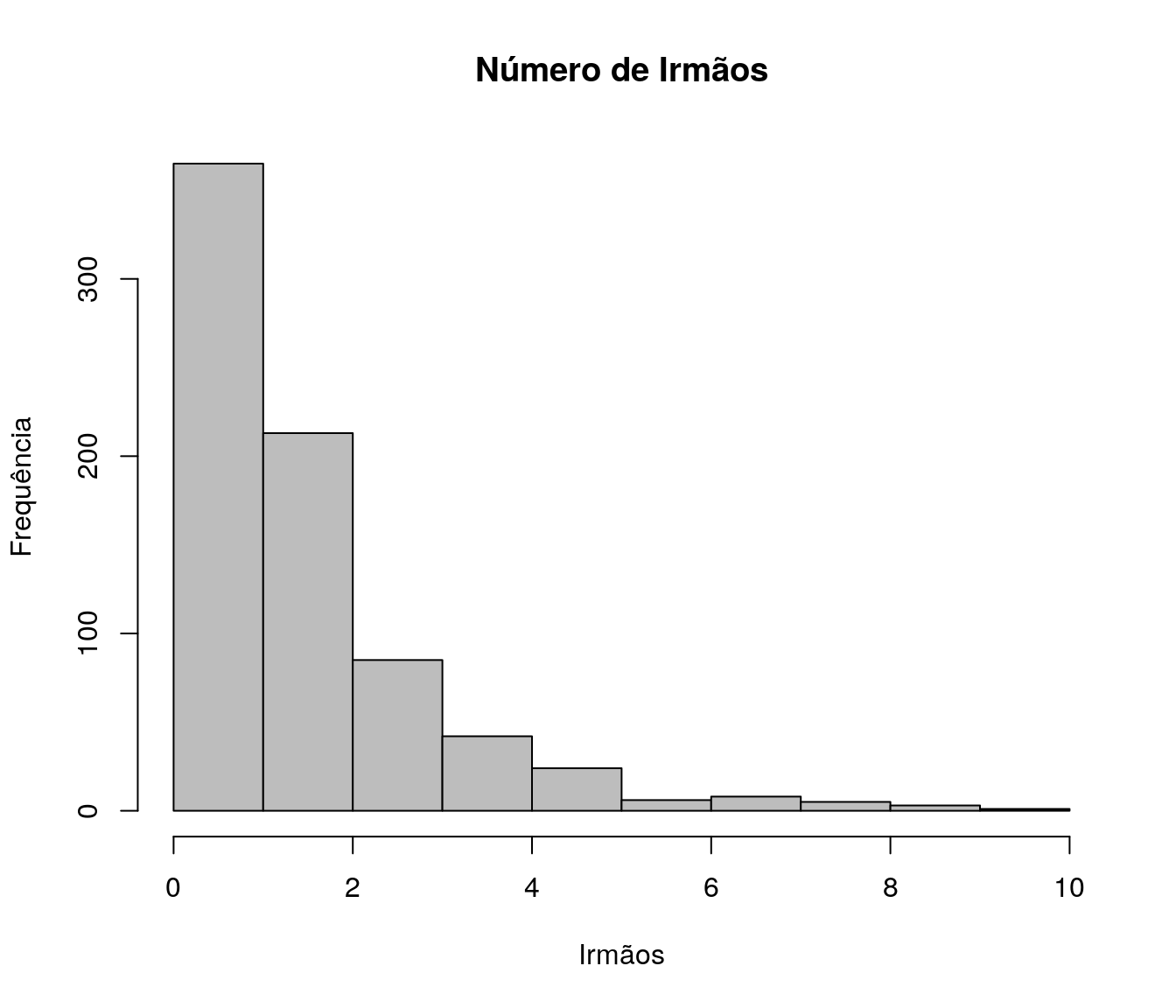
2019
par(mfrow = c(1,2))
with(antigo, hist(td_numIrmao, horizontal=T,
col = "#BDBDBD",
main = "Número de Irmãos - completo",
xlab = 'Irmãos',
ylab = 'Frequência'))
a2 <- subset(antigo, antigo$td_numIrmao < 10)
with(a2, hist(td_numIrmao, horizontal=T,
col = "#BDBDBD",
main = "Número de Irmãos - <10",
xlab = 'Irmãos',
ylab = 'Frequência'))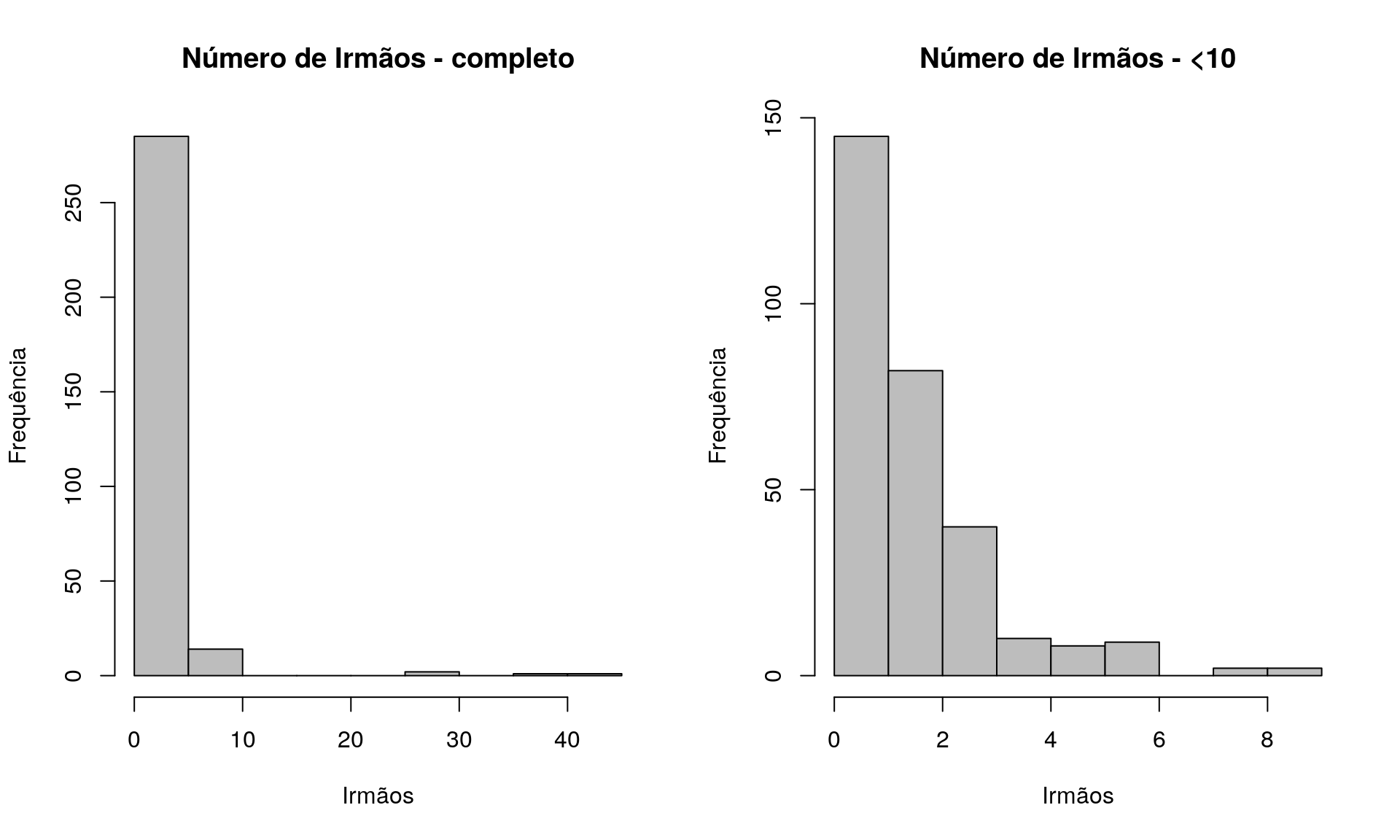
Qual a sua origem?
Tabela
quest$ln_origem <- tolower(iconv(quest$ln_origem,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$ln_origem <- factor(quest$ln_origem,
levels = c("curitiba", "regiao metropolitana",
"interior do parana",
"outro estado", "outro pais"))
fa_origem <- table(quest$ln_origem) # frequência absoluta
fr_origem <- prop.table(fa_origem) # frequência relativa
fac_origem <- cumsum(fr_origem) # frequência acumulada
origem <- data.frame(niveis = names(fa_origem),
freq = as.vector(fa_origem),
freq_r = as.vector(fr_origem),
freq_ac = as.vector(fac_origem)) # unindo as informações
pander:::pander(origem) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| curitiba | 173 | 0.2301 | 0.2301 |
| regiao metropolitana | 36 | 0.04787 | 0.2779 |
| interior do parana | 279 | 0.371 | 0.6489 |
| outro estado | 234 | 0.3112 | 0.9601 |
| outro pais | 30 | 0.03989 | 1 |
Gráfico
origem$niveis <- c("Curitiba",
"Região metropolitana",
"Interior PR", "OutroEstado",
"OutroPaís")
origem_ord <- arrange(origem, origem$freq)
barplot(origem_ord$freq,
#names.arg = origem_ord$niveis,
col = paleta,
main = 'Origem',
ylab = 'Frequência',
xlab = '',
ylim = c(0, max(origem_ord$freq)+30)
#horiz = T,
#las=2,
)
legend("topleft",
legend = origem_ord$niveis,
fill = paleta,
cex = .8)
text(x = as.vector(barplot(origem_ord$freq, plot = FALSE)),
y = as.vector(origem_ord$freq) + 10,
labels = origem_ord$freq, cex = 1)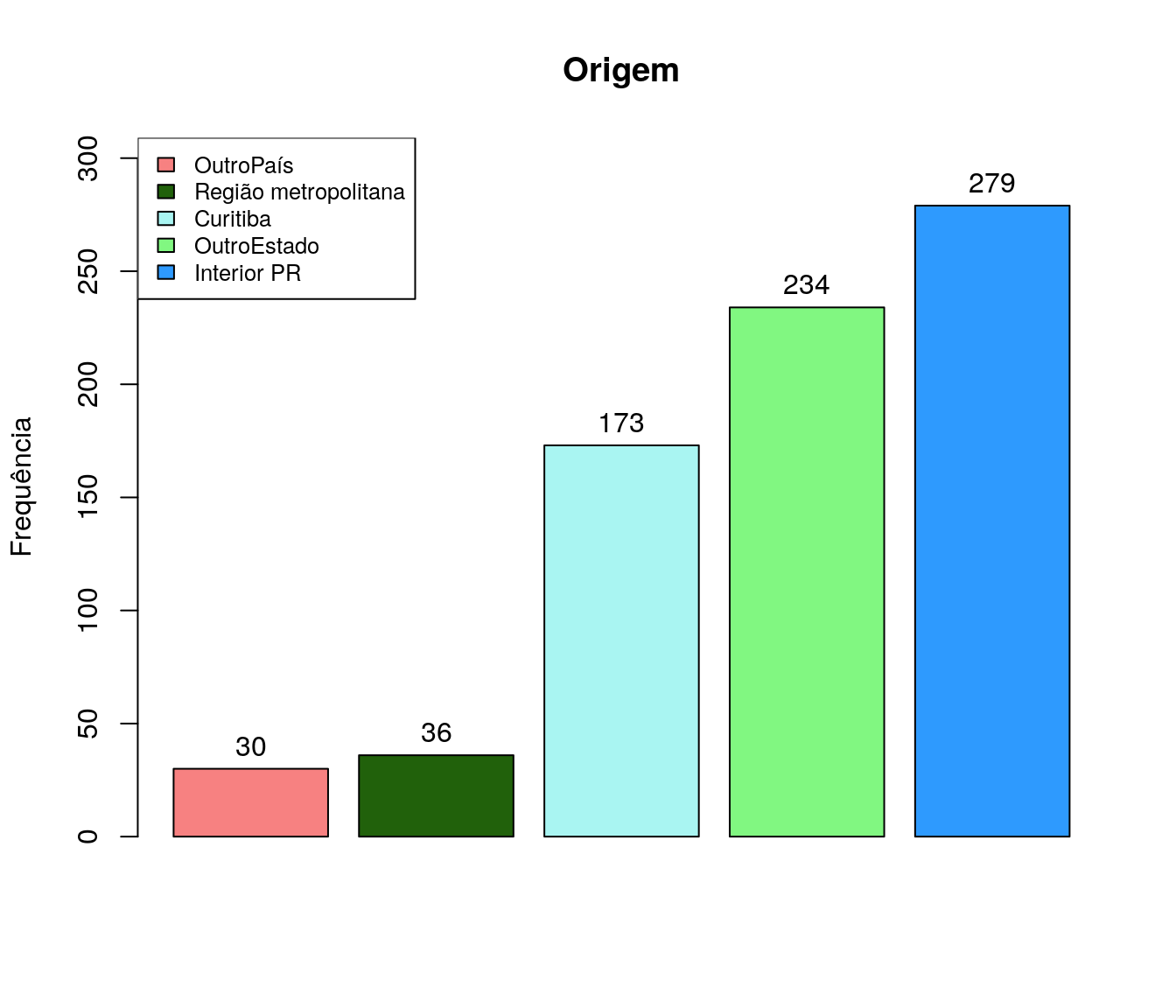
Possui habilitação para dirigir? Qual categoria?
Tabela
quest$ln_tipoHab <-
tolower(iconv(quest$ln_tipoHab,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$ln_tipoHab <- factor(quest$ln_tipoHab,
levels = c("nao", "a (moto)",
"b (carro)",
"a e b (moto e carro)",
"superior a b"))
fa_habit <- table(quest$ln_tipoHab) # frequência absoluta
fr_habit <- prop.table(fa_habit) # frequência relativa
fac_habit <- cumsum(fr_habit) # frequência acumulada
habit <- data.frame(niveis = names(fa_habit),
freq = as.vector(fa_habit),
freq_r = as.vector(fr_habit),
freq_ac = as.vector(fac_habit)) # unindo as informações
pander:::pander(habit) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| nao | 93 | 0.1237 | 0.1237 |
| a (moto) | 7 | 0.009309 | 0.133 |
| b (carro) | 445 | 0.5918 | 0.7247 |
| a e b (moto e carro) | 191 | 0.254 | 0.9787 |
| superior a b | 16 | 0.02128 | 1 |
Gráfico
habit$niveis <- c("Não", "A", "B", "A e B", "Outro")
habit_ord <- arrange(habit, desc(habit$niveis))
barplot(habit_ord$freq, col = '#F3F781',
names.arg = habit_ord$niveis, horiz = T,
xlim = c(0, max(habit_ord$freq + 30)),
main = "Habilitação",
las = 2)
text(y = as.vector(barplot(habit_ord$freq, plot = FALSE)),
x = as.vector(habit_ord$freq) + 10,
labels = habit_ord$freq, cex = 1)
abline(v=50, lty=3, col = 2)
abline(v=100, lty=3, col = 2)
abline(v=150, lty=3, col = 2)
abline(v=200, lty=3, col = 2)
abline(v=250, lty=3, col = 2)
abline(v=300, lty=3, col = 2)
abline(v=350, lty=3, col = 2)
abline(v=400, lty=3, col = 2)
abline(v=450, lty=3, col = 2)
abline(v=500, lty=3, col = 2)
abline(v=550, lty=3, col = 2)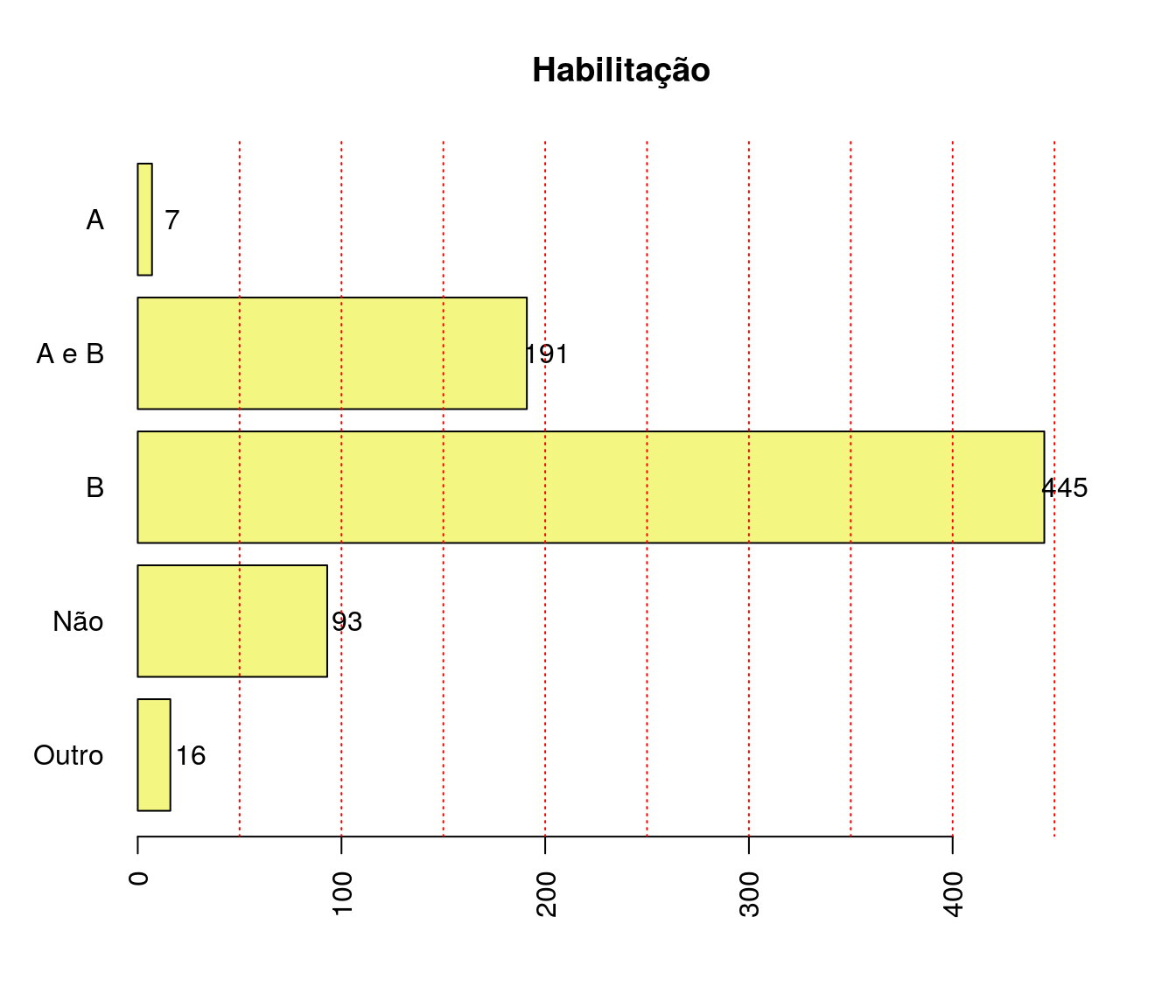
2019
antigo$ln_tipoHab <-
tolower(iconv(antigo$ln_tipoHab,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
antigo$ln_tipoHab <- factor(antigo$ln_tipoHab,
levels = c("nao", "a (moto)",
"b (carro)",
"a e b (moto e carro)",
"superior a b"))
fa_habit <- table(antigo$ln_tipoHab) # frequência absoluta
fr_habit <- prop.table(fa_habit) # frequência relativa
fac_habit <- cumsum(fr_habit) # frequência acumulada
habit <- data.frame(niveis = names(fa_habit),
freq = as.vector(fa_habit),
freq_r = as.vector(fr_habit),
freq_ac = as.vector(fac_habit)) # unindo as informações
#pander:::pander(habit) # gerando a tabela
habit$niveis <- c("Não", "A", "B", "A e B", "Outro")
habit_ord <- arrange(habit, desc(habit$niveis))
barplot(habit_ord$freq, col = '#F3F781',
names.arg = habit_ord$niveis, horiz = T,
xlim = c(0, max(habit_ord$freq + 30)),
main = "Habilitação",
las = 2)
text(y = as.vector(barplot(habit_ord$freq, plot = FALSE)),
x = as.vector(habit_ord$freq) + 10,
labels = habit_ord$freq, cex = 1)
abline(v=50, lty=3, col = 2)
abline(v=100, lty=3, col = 2)
abline(v=150, lty=3, col = 2)
abline(v=200, lty=3, col = 2)
abline(v=250, lty=3, col = 2)
abline(v=300, lty=3, col = 2)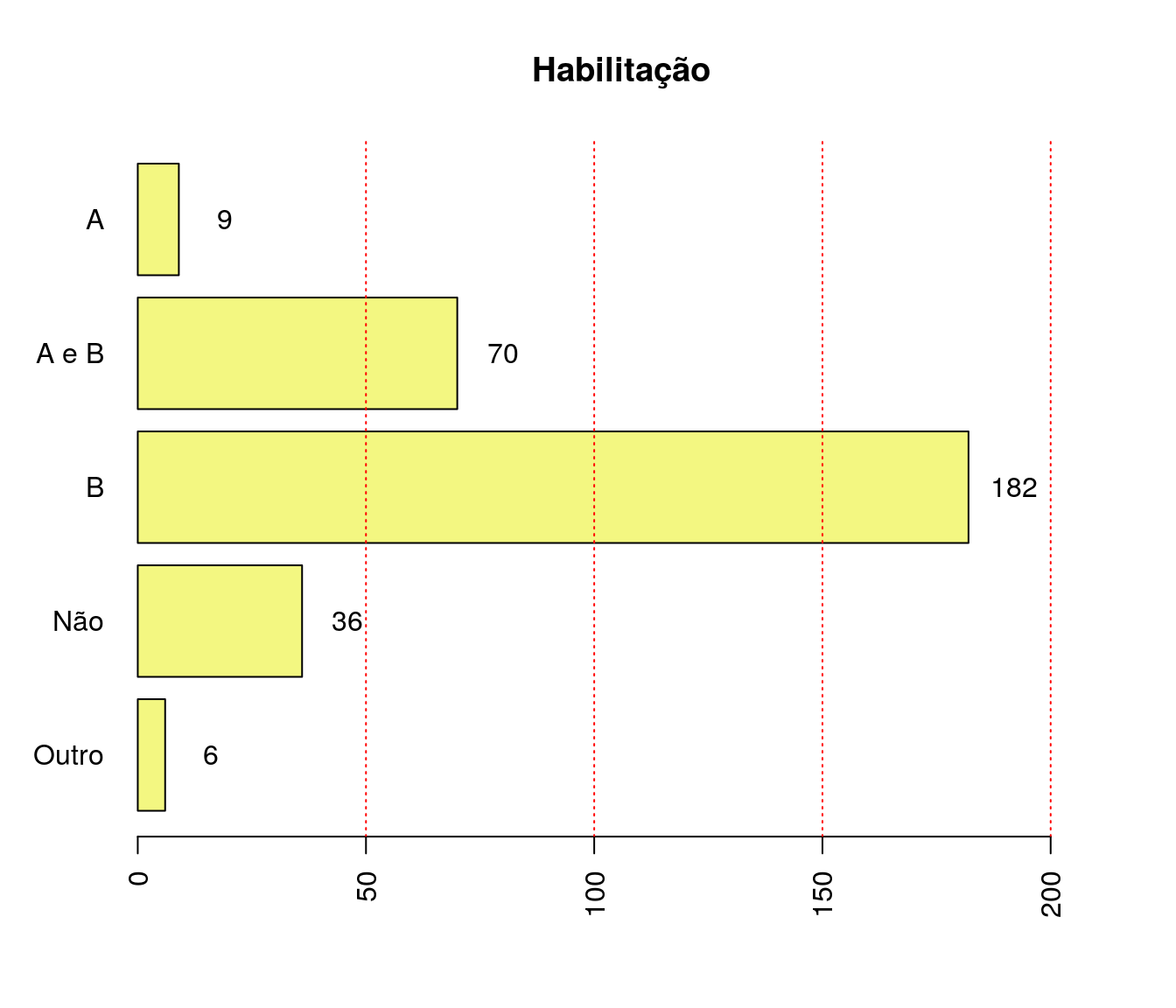
Qual seu meio de transporte predominante para ir para Universidade?
Tabela
quest$ln_tipoTransp <- tolower(iconv(quest$ln_tipoTransp,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- c("carro/moto proprio", "transporte publico", "a pe", "bicicleta",
"carona com amigos", "taxi/aplicativo", "servico fretado de van/onibus")
quest$ln_tipoTransp[ !quest$ln_tipoTransp %in% classOpcoes ] <- "outro"
quest$ln_tipoTransp <- factor(quest$ln_tipoTransp,
levels = c("carro/moto proprio", "transporte publico", "a pe",
"bicicleta", "carona com amigos", "taxi/aplicativo",
"servico fretado de van/onibus", "outro"))
fa_transp <- table(quest$ln_tipoTransp) # frequência absoluta
fr_transp <- prop.table(fa_transp) # frequência relativa
fac_transp <- cumsum(fr_transp) # frequência acumulada
transp <- data.frame(niveis = names(fa_transp),
freq = as.vector(fa_transp),
freq_r = as.vector(fr_transp),
freq_ac = as.vector(fac_transp)) # unindo as informações
pander:::pander(transp) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| carro/moto proprio | 439 | 0.5838 | 0.5838 |
| transporte publico | 130 | 0.1729 | 0.7566 |
| a pe | 94 | 0.125 | 0.8816 |
| bicicleta | 26 | 0.03457 | 0.9162 |
| carona com amigos | 10 | 0.0133 | 0.9295 |
| taxi/aplicativo | 30 | 0.03989 | 0.9694 |
| servico fretado de van/onibus | 9 | 0.01197 | 0.9814 |
| outro | 14 | 0.01862 | 1 |
Gráfico
transp$niveis <- c("Veículo Próprio", "Transp. Público", "A pé", "Bicicleta", "Carona", "Táxi",
"Van/ônibus", "Outro")
transp_ord <- arrange(transp, transp$freq)
barplot(transp_ord$freq,
#names.arg = transp_ord$niveis,
col = paleta,
main = 'Locomoção',
ylab = 'Frequência',
xlab = '',
ylim = c(0, max(transp_ord$freq)+30)
#horiz = T,
#las=2,
)
legend("topleft",
legend = transp_ord$niveis,
fill = paleta,
cex = .8)
text(x = as.vector(barplot(transp_ord$freq, plot = FALSE)),
y = as.vector(transp_ord$freq) + 10,
labels = transp_ord$freq, cex = 1)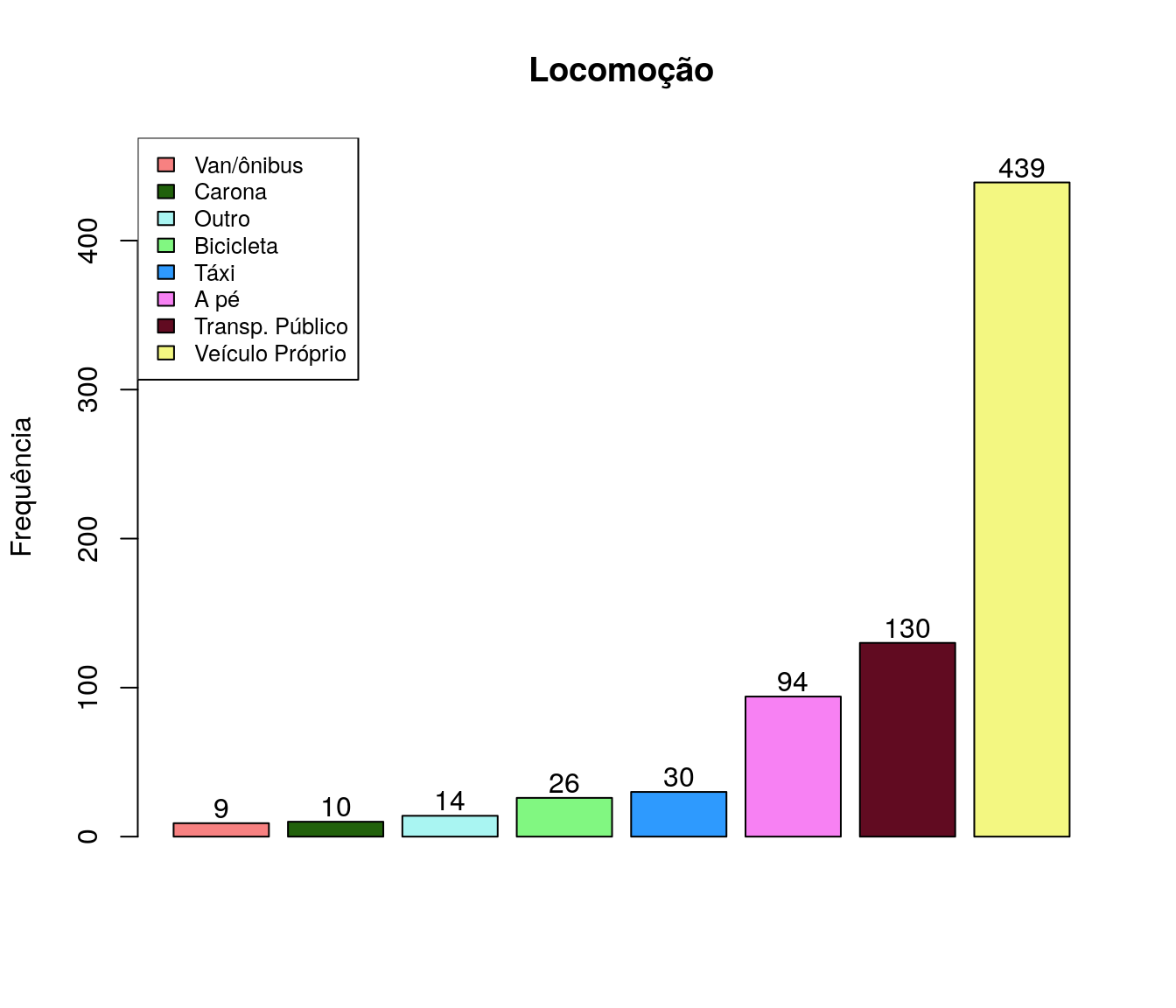
2019
antigo$ln_tipoTransp <- tolower(iconv(antigo$ln_tipoTransp,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
classOpcoes <- c("carro/moto proprio", "transporte publico", "a pe", "bicicleta",
"carona com amigos", "taxi/aplicativo", "servico fretado de van/onibus")
antigo$ln_tipoTransp[ !antigo$ln_tipoTransp %in% classOpcoes ] <- "outro"
antigo$ln_tipoTransp <- factor(antigo$ln_tipoTransp,
levels = c("carro/moto proprio", "transporte publico", "a pe",
"bicicleta", "carona com amigos", "taxi/aplicativo",
"servico fretado de van/onibus", "outro"))
fa_transp <- table(antigo$ln_tipoTransp) # frequência absoluta
fr_transp <- prop.table(fa_transp) # frequência relativa
fac_transp <- cumsum(fr_transp) # frequência acumulada
transp <- data.frame(niveis = names(fa_transp),
freq = as.vector(fa_transp),
freq_r = as.vector(fr_transp),
freq_ac = as.vector(fac_transp)) # unindo as informações
#pander:::pander(transp) # gerando a tabela
transp$niveis <- c("Veículo Próprio", "Transp. Público", "A pé", "Bicicleta", "Carona", "Táxi",
"Van/ônibus", "Outro")
transp_ord <- arrange(transp, transp$freq)
barplot(transp_ord$freq,
#names.arg = transp_ord$niveis,
col = paleta,
main = 'Locomoção',
ylab = 'Frequência',
xlab = '',
ylim = c(0, max(transp_ord$freq)+30)
#horiz = T,
#las=2,
)
legend("topleft",
legend = transp_ord$niveis,
fill = paleta,
cex = .8)
text(x = as.vector(barplot(transp_ord$freq, plot = FALSE)),
y = as.vector(transp_ord$freq) + 10,
labels = transp_ord$freq, cex = 1)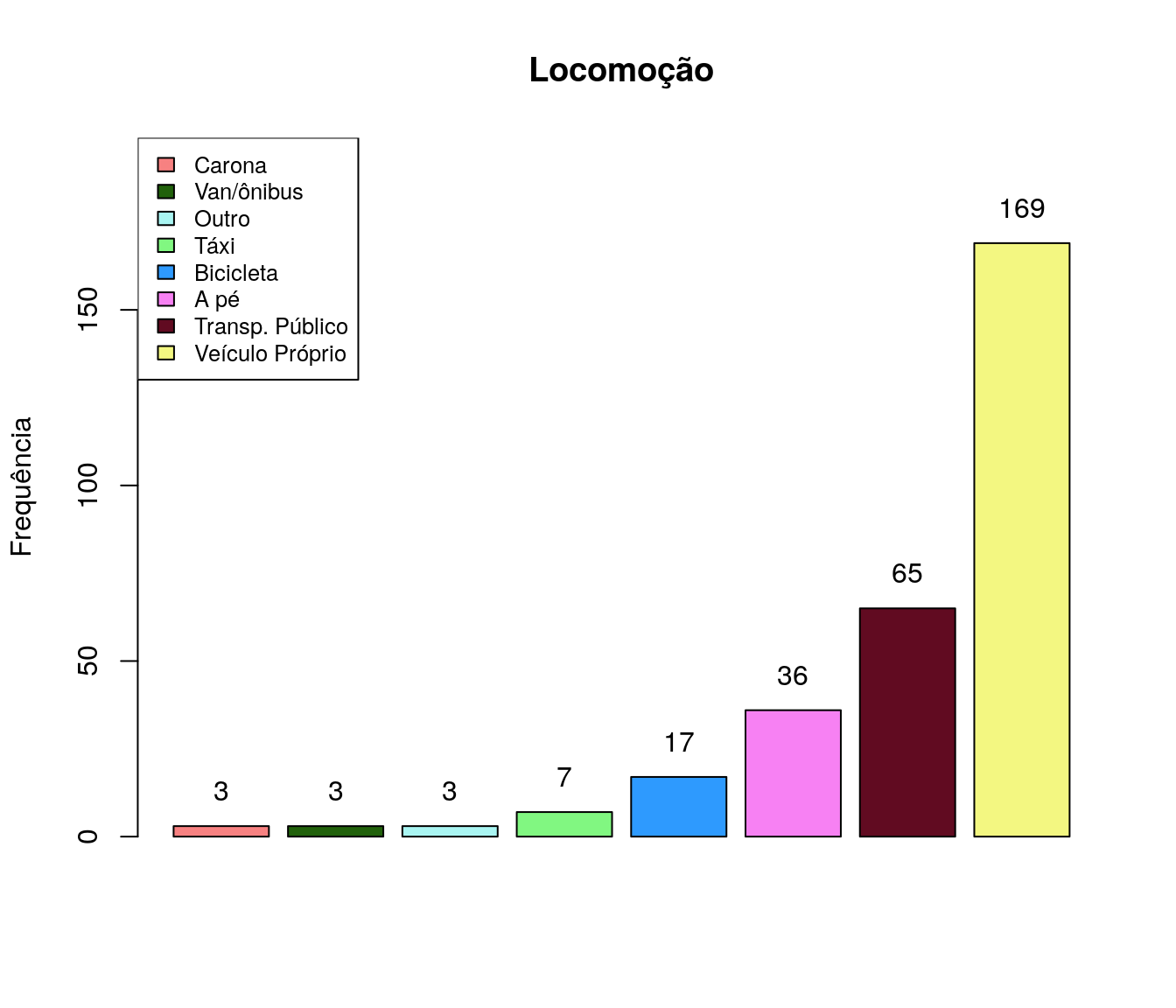
Em média, quanto tempo você demora para chegar a Universidade?
Tabela 1
Variável sem tratamento
quest$tc_tempoPUniv <- as.integer(quest$tc_tempoPUniv)
h <- hist(quest$tc_tempoPUniv, plot = FALSE) #histograma
breaks <- h$breaks #armazenando os breaks do histograma
classes <- cut(quest$tc_tempoPUniv, breaks = breaks,
include.lowest = TRUE, right = TRUE) #gerando classes
tb.tempo <- as.data.frame(table(classes)) #gerando tabela com faixas
tb.tempo$Perc <- prop.table(tb.tempo$Freq)
names(tb.tempo)[1] <- "Ano"
pander:::pander(tb.tempo)| Ano | Freq | Perc |
|---|---|---|
| [0,500] | 746 | 0.992 |
| (500,1e+03] | 5 | 0.006649 |
| (1e+03,1.5e+03] | 0 | 0 |
| (1.5e+03,2e+03] | 0 | 0 |
| (2e+03,2.5e+03] | 0 | 0 |
| (2.5e+03,3e+03] | 0 | 0 |
| (3e+03,3.5e+03] | 0 | 0 |
| (3.5e+03,4e+03] | 1 | 0.00133 |
Tabela 2
Variável com tratamento
tempoPUniv2 <- subset(quest$tc_tempoPUniv, quest$tc_tempoPUniv < 800)
h <- hist(tempoPUniv2, plot = FALSE) #histograma
breaks <- h$breaks #armazenando os breaks do histograma
classes <- cut(tempoPUniv2, breaks = breaks,
include.lowest = TRUE, right = TRUE) #gerando classes
tb.tempo <- as.data.frame(table(classes)) #gerando tabela com faixas
tb.tempo$Perc <- prop.table(tb.tempo$Freq)
names(tb.tempo)[1] <- "Ano"
pander:::pander(tb.tempo)| Ano | Freq | Perc |
|---|---|---|
| [0,50] | 649 | 0.8688 |
| (50,100] | 62 | 0.083 |
| (100,150] | 21 | 0.02811 |
| (150,200] | 6 | 0.008032 |
| (200,250] | 4 | 0.005355 |
| (250,300] | 3 | 0.004016 |
| (300,350] | 0 | 0 |
| (350,400] | 0 | 0 |
| (400,450] | 1 | 0.001339 |
| (450,500] | 0 | 0 |
| (500,550] | 1 | 0.001339 |
Tabela 3
medidas <- data.frame(minimo = quantile(tempoPUniv2)[1],
quart1 = quantile(tempoPUniv2)[2],
media = mean(tempoPUniv2),
mediana = quantile(tempoPUniv2)[3],
moda = names(sort(table(tempoPUniv2),
decreasing = TRUE)[1]),
quart3 = quantile(tempoPUniv2)[4],
max = quantile(tempoPUniv2)[5])
row.names(medidas) <- NULL
pander(medidas)| minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|
| 0 | 15 | 33.17 | 20 | 20 | 30 | 510 |
disp <- data.frame(amplitude = diff(range(tempoPUniv2)),
variancia = var(tempoPUniv2),
desv_pad = sd(tempoPUniv2),
coef_var = 100*sd(tempoPUniv2)/mean(tempoPUniv2))
pander(disp)| amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|
| 510 | 1878 | 43.33 | 130.6 |
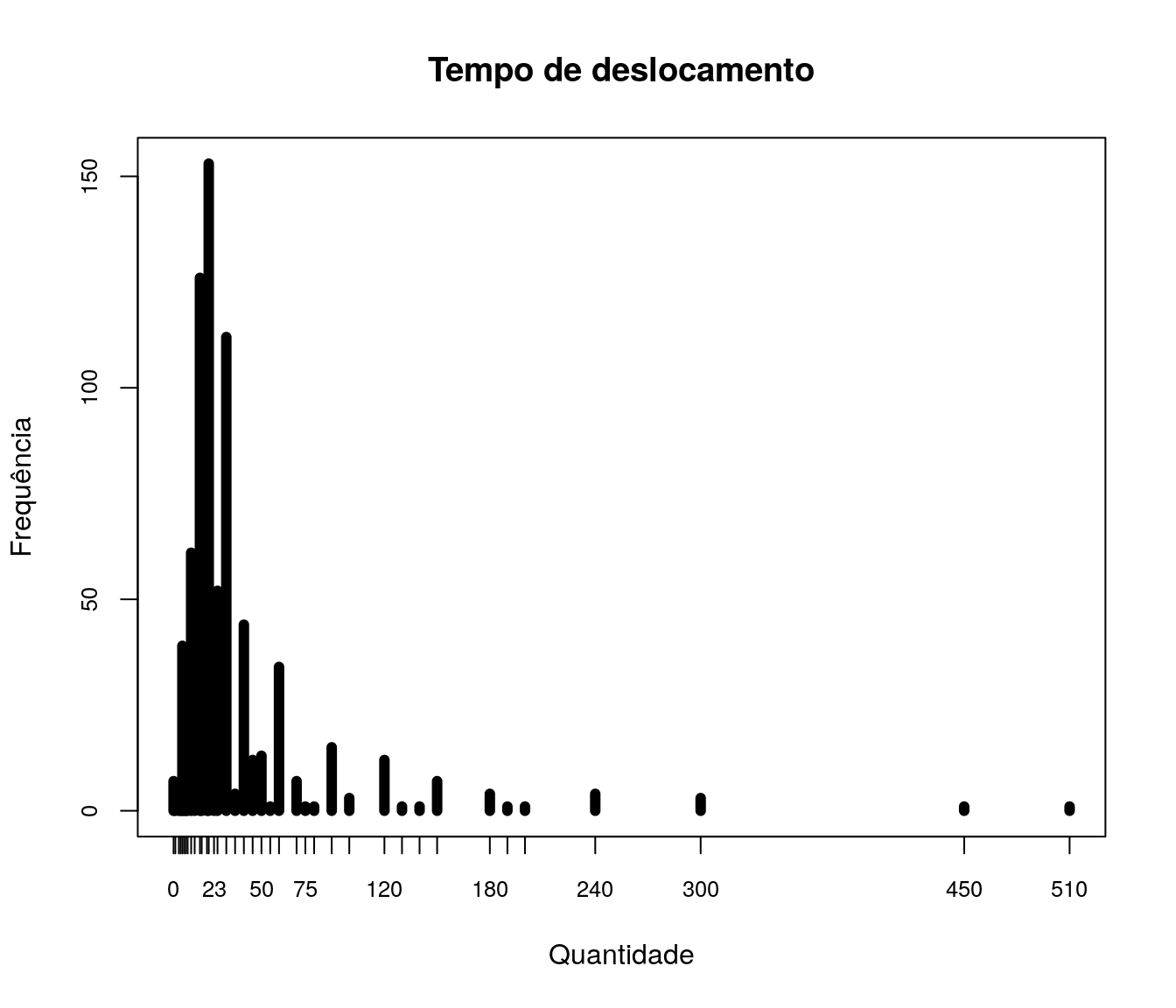
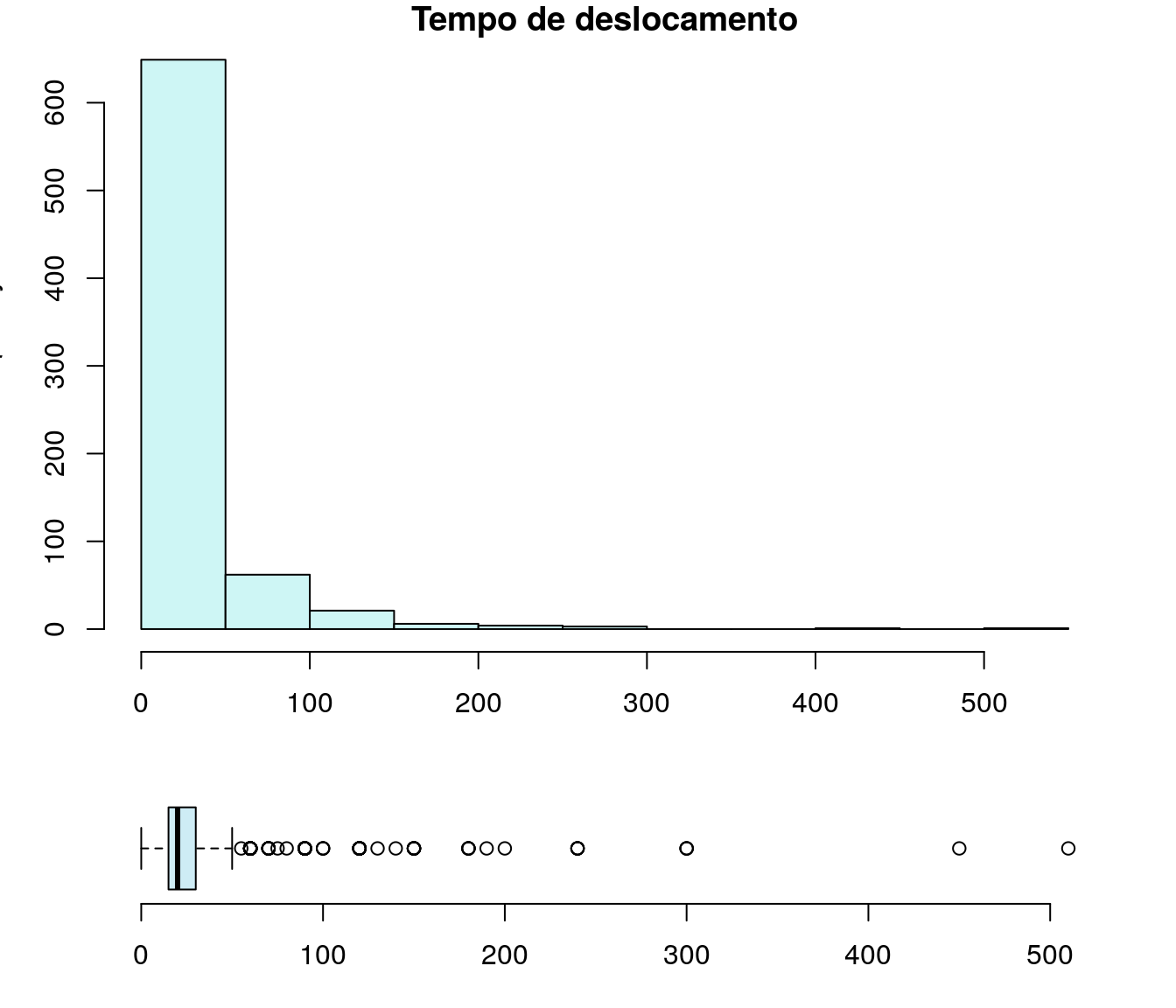
Em média, quantas vezes você usa táxi/aplicativo de transporte durante o mês?
Tabela 1
quest$td_qtddServTransp <- as.integer(quest$td_qtddServTransp)
h <- hist(quest$td_qtddServTransp, plot = FALSE) #histograma
breaks <- h$breaks #armazenando os breaks do histograma
classes <- cut(quest$td_qtddServTransp, breaks = breaks,
include.lowest = TRUE, right = TRUE) #gerando classes
tb.apl <- as.data.frame(table(classes)) #gerando tabela com faixas
tb.apl$Perc <- prop.table(tb.apl$Freq)
names(tb.apl)[1] <- "Ano"
pander:::pander(tb.apl)| Ano | Freq | Perc |
|---|---|---|
| [0,5] | 629 | 0.8364 |
| (5,10] | 91 | 0.121 |
| (10,15] | 16 | 0.02128 |
| (15,20] | 8 | 0.01064 |
| (20,25] | 0 | 0 |
| (25,30] | 1 | 0.00133 |
| (30,35] | 0 | 0 |
| (35,40] | 4 | 0.005319 |
| (40,45] | 0 | 0 |
| (45,50] | 1 | 0.00133 |
| (50,55] | 0 | 0 |
| (55,60] | 2 | 0.00266 |
Tabela 2
medidas <- data.frame(minimo = quantile(quest$td_qtddServTransp)[1],
quart1 = quantile(quest$td_qtddServTransp)[2],
media = mean(quest$td_qtddServTransp),
mediana = quantile(quest$td_qtddServTransp)[3],
moda = names(sort(table(quest$td_qtddServTransp),
decreasing = TRUE)[1]),
quart3 = quantile(quest$td_qtddServTransp)[4],
max = quantile(quest$td_qtddServTransp)[5])
row.names(medidas) <- NULL
pander(medidas)| minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|
| 0 | 0 | 3.145 | 1 | 0 | 4 | 60 |
disp <- data.frame(amplitude = diff(range(quest$td_qtddServTransp)),
variancia = var(quest$td_qtddServTransp),
desv_pad = sd(quest$td_qtddServTransp),
coef_var = 100*sd(quest$td_qtddServTransp)/mean(quest$td_qtddServTransp))
pander(disp)| amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|
| 60 | 34.49 | 5.873 | 186.7 |
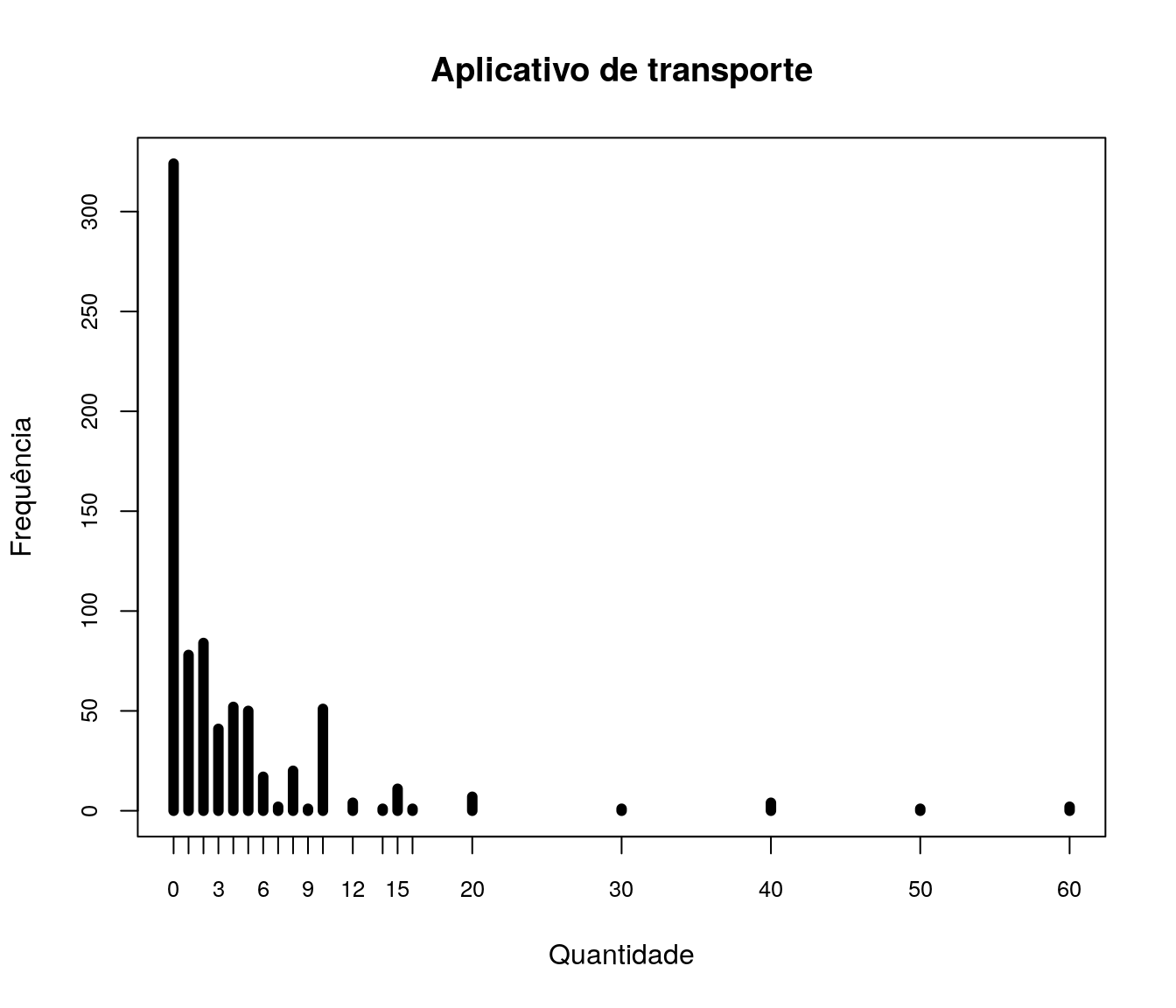
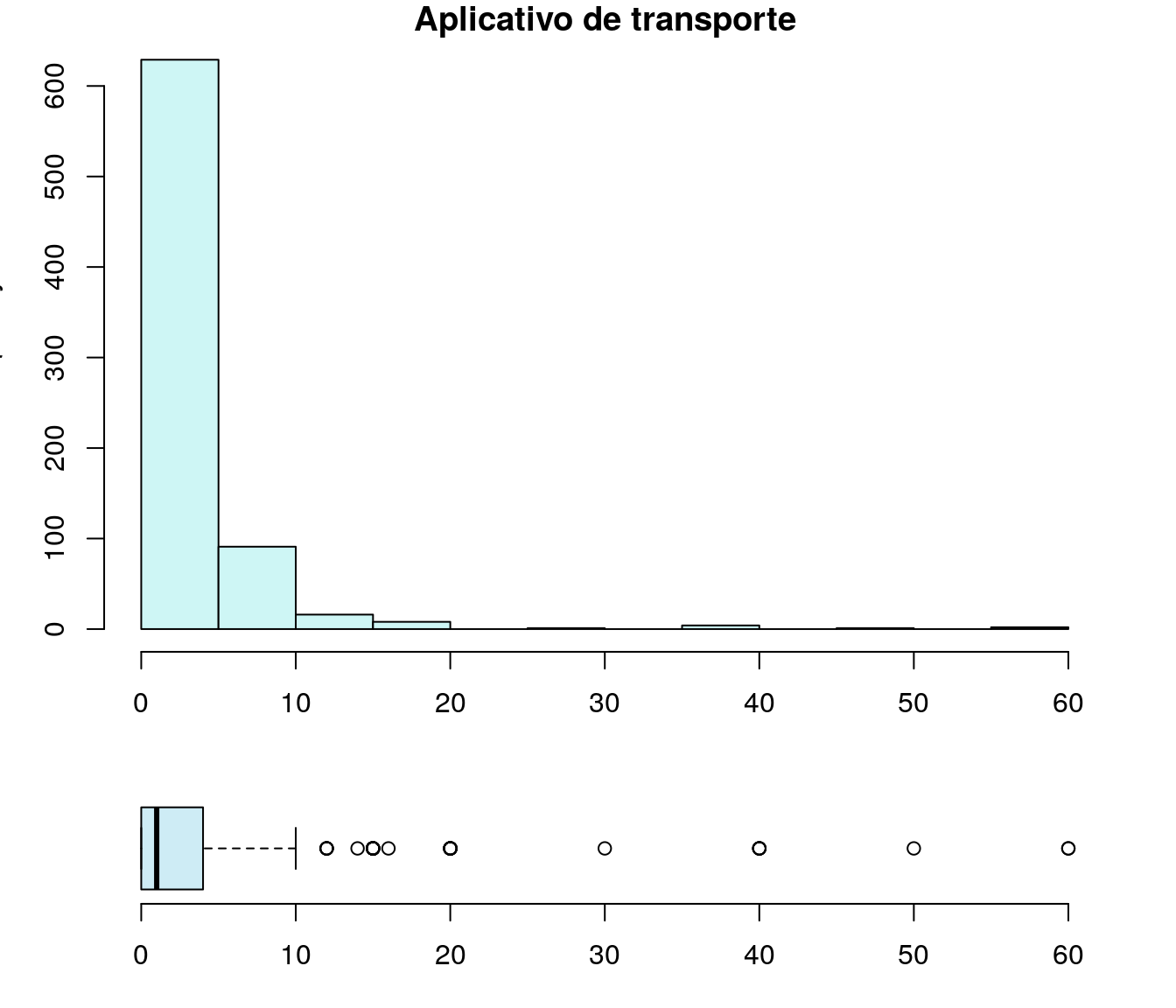
Possui animal de estimação?
Tabela
quest$ln_pet <-
tolower(iconv(quest$ln_pet,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$ln_pet <- gsub(",", ";", quest$ln_pet)
quest$ln_pet[ which(is.na(quest$ln_pet)) ] <- "nao possuo"
ar_pet<- cSplit(quest, "ln_pet", sep = ";", direction = "long")$ln_pet
ar_pet <- factor(ar_pet, levels = c("nao possuo", "cachorro",
"gato", "passaro",
"peixe", "tartaruga",
"coelho", "outro"))
fa_pet <- table(ar_pet) # frequência absoluta
fr_pet <- prop.table(fa_pet) # frequência relativa
fac_pet <- cumsum(fr_pet) # frequência acumulada
pet <- data.frame(niveis = names(fa_pet),
freq = as.vector(fa_pet),
freq_r = as.vector(fr_pet),
freq_ac = as.vector(fac_pet)) # unindo as informações
pander:::pander(pet) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| nao possuo | 288 | 0.3207 | 0.3207 |
| cachorro | 367 | 0.4087 | 0.7294 |
| gato | 146 | 0.1626 | 0.892 |
| passaro | 30 | 0.03341 | 0.9254 |
| peixe | 26 | 0.02895 | 0.9543 |
| tartaruga | 5 | 0.005568 | 0.9599 |
| coelho | 16 | 0.01782 | 0.9777 |
| outro | 20 | 0.02227 | 1 |
Gráfico 1
ppet <- c(sum(quest$ln_pet == "nao possuo"),
sum(quest$ln_pet != "nao possuo"))
names(ppet) <- c("Não possui", "Possui")
par(mfrow = c(1,2))
ar_color <- c("#5882FA", "#FA5858")
pie(ppet, col = ar_color,
main = "Animais de estimação",
labels = ppet)
legend("topleft", legend = names(ppet), fill = ar_color, cex = 1)
barplot(ppet, col = ar_color,
main = "Animais de estimação",
names.arg = names(ppet),
ylim = c(0, max(ppet + 30)))
text(x = as.vector(barplot(ppet, plot = FALSE)),
y = as.vector(ppet) + 10,
labels = ppet, cex = 1)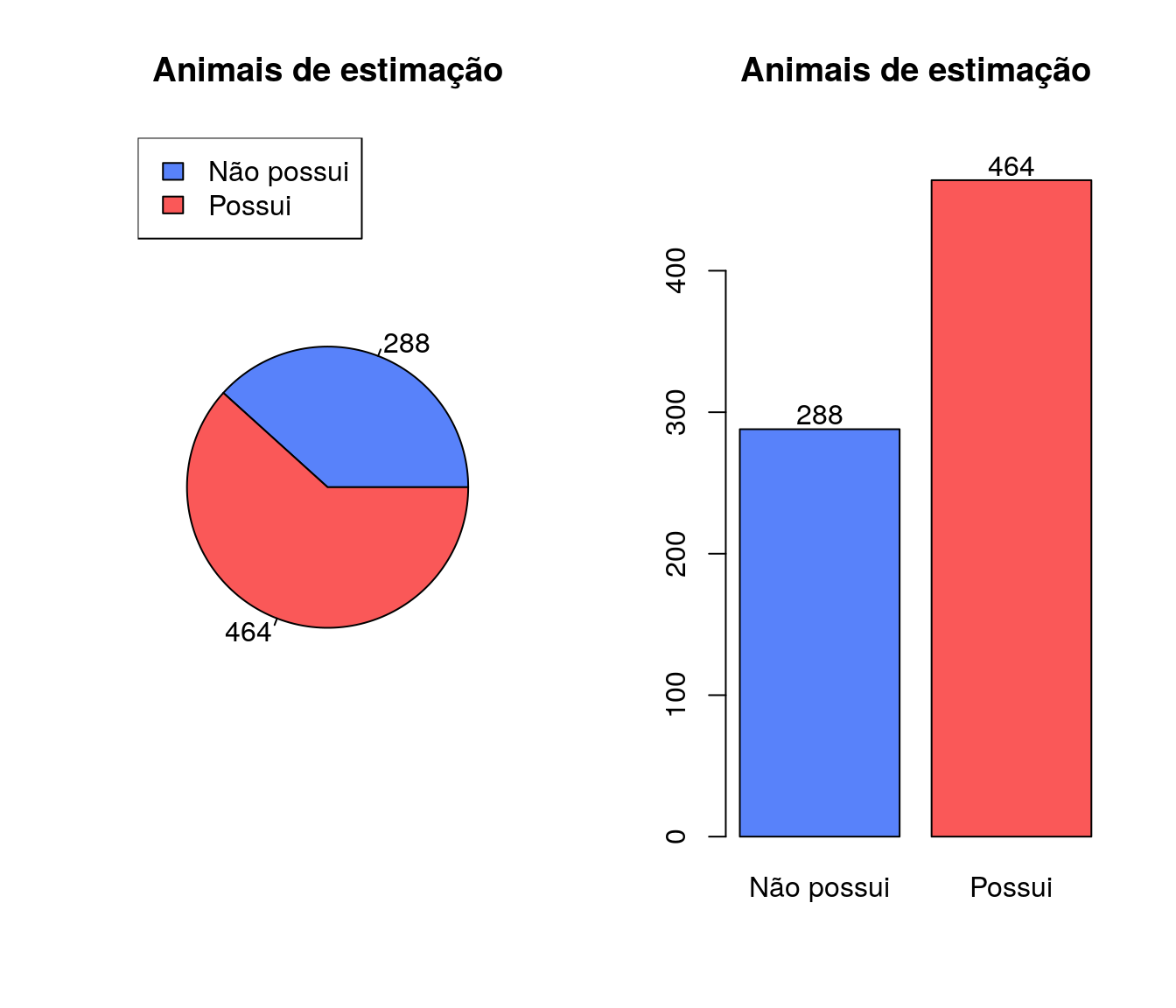
Gráfico 2
pet$niveis <- c("Não", "Cão", "Gato", "Ave", "Peixe",
"Tartaruga", "Coelho", "Outro")
pet_ord <- arrange(pet, pet$freq)
barplot(pet_ord$freq, col = '#E0F8F7',
names.arg = pet_ord$niveis, horiz = T,
xlim = c(0, max(pet_ord$freq + 30)),
main = "Animais de estimação",
las = 2)
text(y = as.vector(barplot(pet_ord$freq, plot = FALSE)),
x = as.vector(pet_ord$freq) + 10,
labels = pet_ord$freq, cex = 1)
abline(v=50, lty=3, col = 2)
abline(v=100, lty=3, col = 2)
abline(v=150, lty=3, col = 2)
abline(v=200, lty=3, col = 2)
abline(v=250, lty=3, col = 2)
abline(v=300, lty=3, col = 2)
abline(v=350, lty=3, col = 2)
abline(v=400, lty=3, col = 2)
abline(v=450, lty=3, col = 2)
abline(v=500, lty=3, col = 2)
abline(v=550, lty=3, col = 2)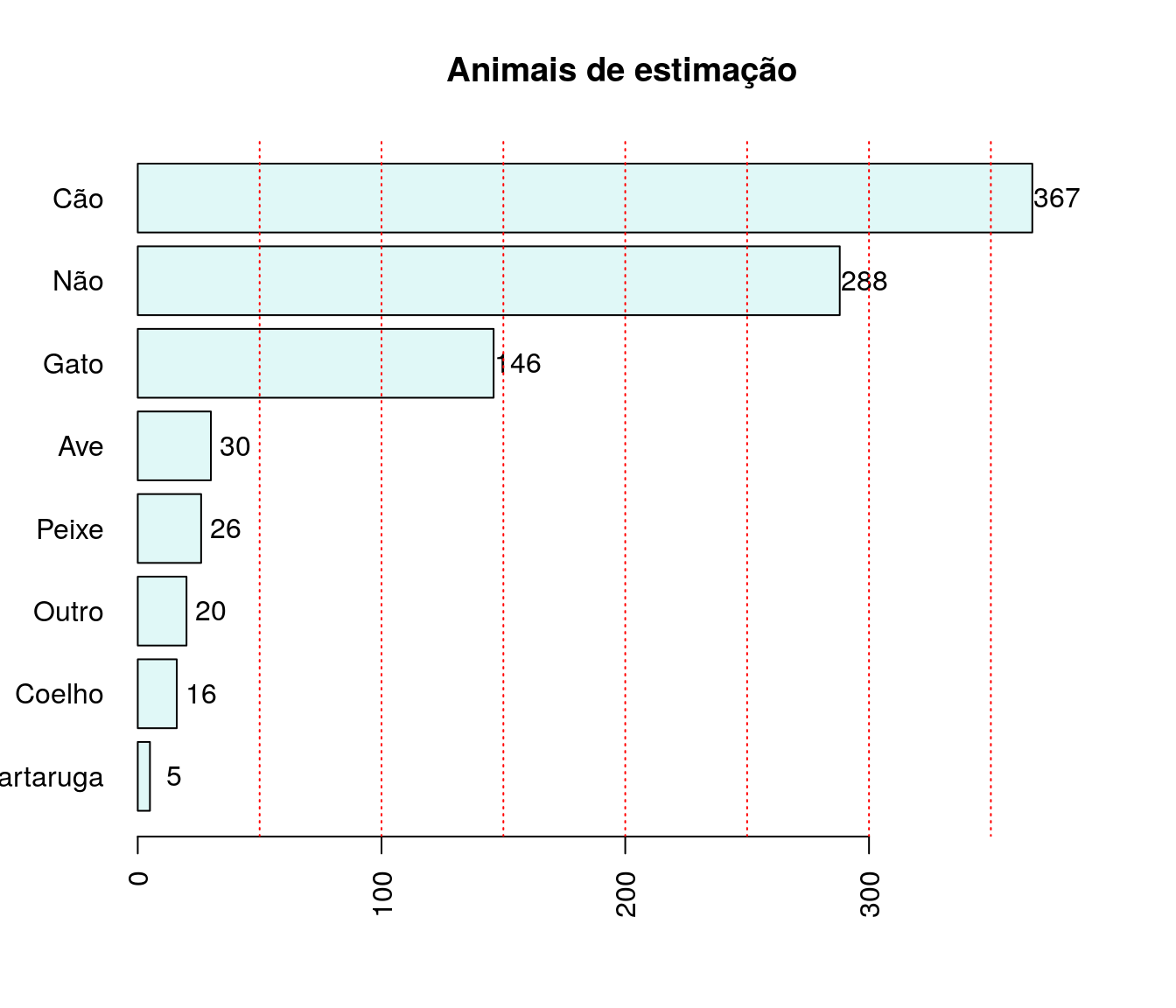
Toca algum instrumento musical?
Tabela
quest$ln_instr <-
tolower(iconv(quest$ln_instr,
to ='ASCII//TRANSLIT',
from = "UTF-8"))
quest$ln_instr <- gsub(",", ";", quest$ln_instr)
quest$ln_instr[ which(is.na(quest$ln_instr)) ] <- "nao toco nenhum instrumento"
ar_inst<- cSplit(quest, "ln_instr", sep = ";", direction = "long")$ln_instr
ar_inst <- factor(ar_inst, levels = c("nao toco nenhum instrumento",
"violao", "guitarra",
"teclado", "contrabaixo",
"bateria", "piano",
"flauta", "outro"))
fa_inst <- table(ar_inst) # frequência absoluta
fr_inst <- prop.table(fa_inst) # frequência relativa
fac_inst <- cumsum(fr_inst) # frequência acumulada
inst <- data.frame(niveis = names(fa_inst),
freq = as.vector(fa_inst),
freq_r = as.vector(fr_inst),
freq_ac = as.vector(fac_inst)) # unindo as informações
pander:::pander(inst) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| nao toco nenhum instrumento | 535 | 0.6032 | 0.6032 |
| violao | 122 | 0.1375 | 0.7407 |
| guitarra | 37 | 0.04171 | 0.7824 |
| teclado | 52 | 0.05862 | 0.841 |
| contrabaixo | 16 | 0.01804 | 0.8591 |
| bateria | 13 | 0.01466 | 0.8737 |
| piano | 40 | 0.0451 | 0.9188 |
| flauta | 21 | 0.02368 | 0.9425 |
| outro | 51 | 0.0575 | 1 |
Gráfico 1
pinst <- c(sum(quest$ln_instr == "nao toco nenhum instrumento"),
sum(quest$ln_pet != "nao toco nenhum instrumento"))
names(pinst) <- c("Toca", "Não toca")
par(mfrow = c(1,2))
ar_color <- c("#5882FA", "#FA5858")
pie(pinst, col = ar_color,
main = "Instrumentos musicais",
labels = pinst)
legend("topleft", legend = names(pinst), fill = ar_color, cex = 1)
barplot(pinst, col = ar_color,
main = "Instrumentos musicais",
names.arg = names(pinst),
ylim = c(0, max(pinst + 20)))
text(x = as.vector(barplot(pinst, plot = FALSE)),
y = as.vector(pinst) + 10,
labels = pinst, cex = 1)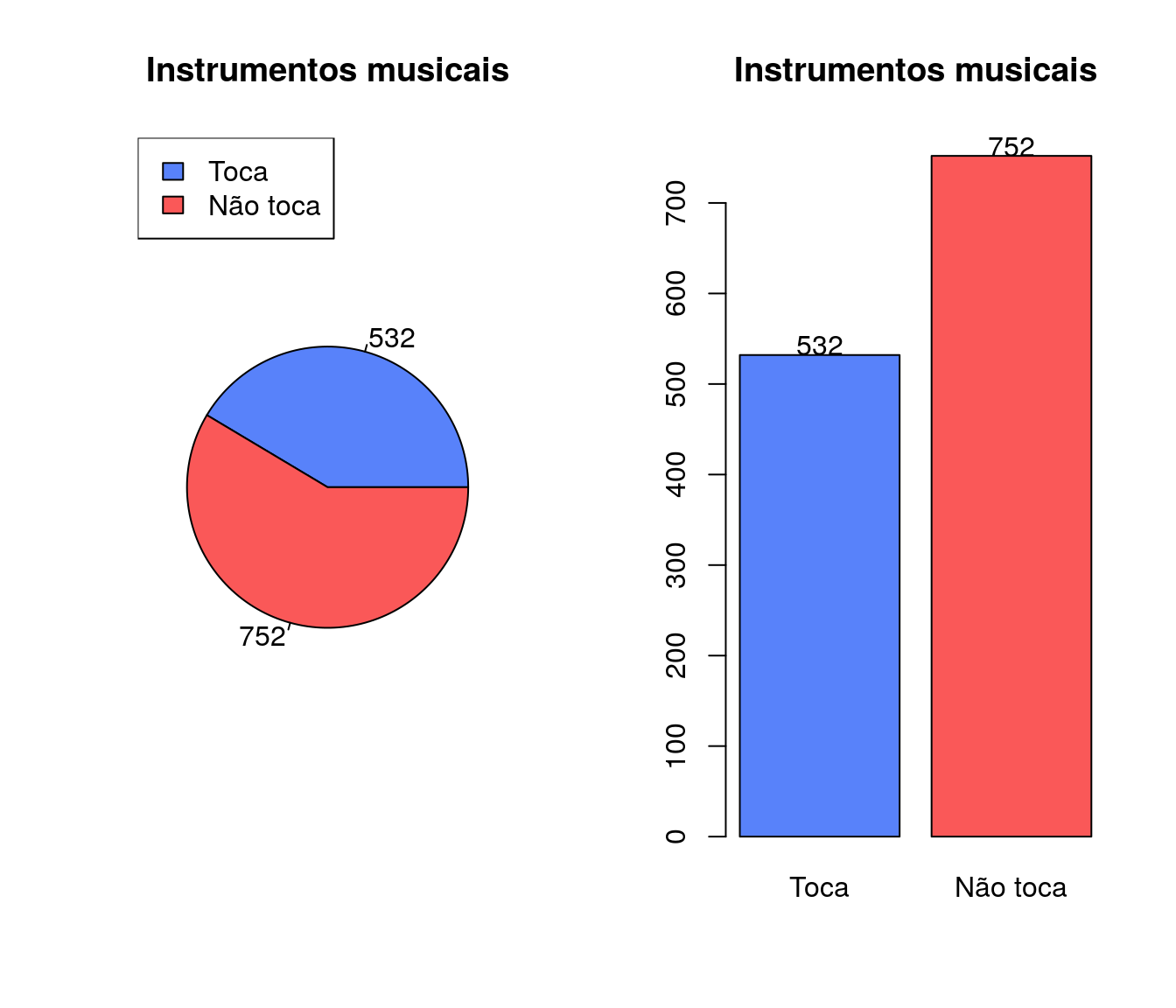
Gráfico 2
inst$niveis <- c("Não", "Violão", "Guitarra", "Teclado", "Baixo",
"Bateria", "Piano", "Flauta", "Outro")
inst_ord <- arrange(inst, inst$freq)
barplot(inst_ord$freq, col = '#CEF6CE',
names.arg = inst_ord$niveis, horiz = T,
xlim = c(0, max(inst_ord$freq + 30)),
main = "Instrumentos musicais",
las = 2)
text(y = as.vector(barplot(inst_ord$freq, plot = FALSE)),
x = as.vector(inst_ord$freq) + 10,
labels = inst_ord$freq, cex = 1)
abline(v=50, lty=3, col = 2)
abline(v=100, lty=3, col = 2)
abline(v=150, lty=3, col = 2)
abline(v=200, lty=3, col = 2)
abline(v=250, lty=3, col = 2)
abline(v=300, lty=3, col = 2)
abline(v=350, lty=3, col = 2)
abline(v=400, lty=3, col = 2)
abline(v=450, lty=3, col = 2)
abline(v=500, lty=3, col = 2)
abline(v=550, lty=3, col = 2)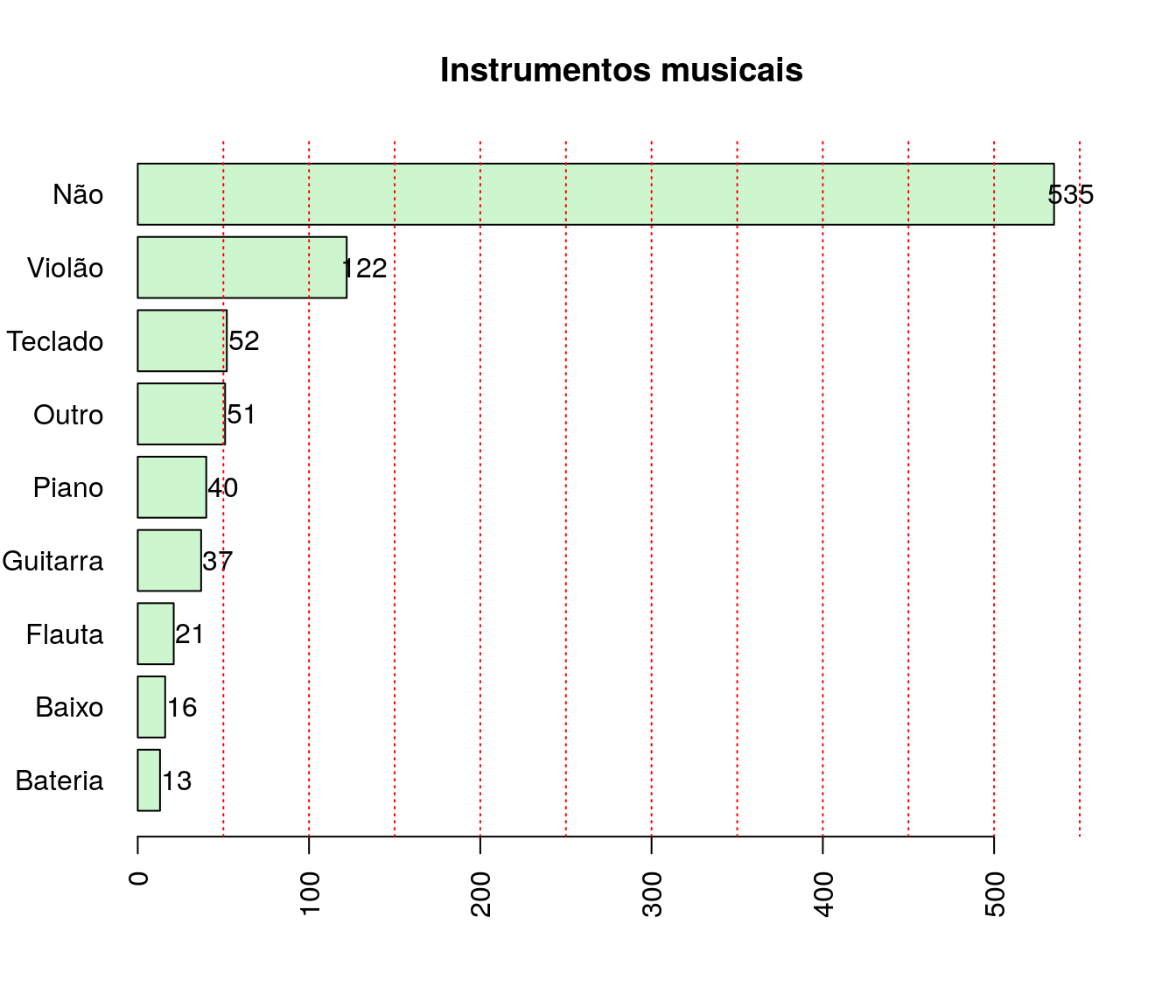
De quais redes sociais você participa?
Tabela
quest$ln_rede <- gsub(",", ";", quest$ln_rede)
quest$ln_rede[ which(is.na(quest$ln_rede)) ] <- "Nenhuma"
ar_rede<- cSplit(quest, "ln_rede", sep = ";", direction = "long")$ln_rede
ar_rede <- factor(ar_rede, levels = c("Facebook", "Twitter", "Google+", "Instagram",
"Linkedin", "Outras", "Nenhuma"))
fa_rede <- table(ar_rede) # frequência absoluta
fr_rede <- prop.table(fa_rede) # frequência relativa
fac_rede <- cumsum(fr_rede) # frequência acumulada
rede <- data.frame(niveis = names(fa_rede),
freq = as.vector(fa_rede),
freq_r = as.vector(fr_rede),
freq_ac = as.vector(fac_rede)) # unindo as informações
rede$niveis <- as.vector(rede$niveis)
rede[7,1] <- 'Nao tem'
pander:::pander(rede) # gerando a tabela| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| 620 | 0.3149 | 0.3149 | |
| 162 | 0.08228 | 0.3972 | |
| Google+ | 87 | 0.04418 | 0.4413 |
| 629 | 0.3195 | 0.7608 | |
| 383 | 0.1945 | 0.9553 | |
| Outras | 54 | 0.02743 | 0.9827 |
| Nao tem | 34 | 0.01727 | 1 |
Gráfico
rede$niveis <- c('Face', 'Twitter', 'Google+',
'Insta', 'Linkedin', 'Outras',
'Nao tem')
rede_ord <- arrange(rede, rede$freq)
bp <- barplot(rede_ord$freq,
names.arg = rede_ord$niveis,
col = '#81F7BE',
main = 'Redes sociais',
xlab = 'Frequência',
ylab = '',
horiz = T,
las=2,
xlim = c(0, max(rede_ord$freq)+50))
text(y = c(bp),
x = rede_ord$freq,
labels = rede_ord$freq,
pos = 4)
abline(v=50, lty=3, col = 2)
abline(v=100, lty=3, col = 2)
abline(v=150, lty=3, col = 2)
abline(v=200, lty=3, col = 2)
abline(v=250, lty=3, col = 2)
abline(v=300, lty=3, col = 2)
abline(v=350, lty=3, col = 2)
abline(v=400, lty=3, col = 2)
abline(v=450, lty=3, col = 2)
abline(v=500, lty=3, col = 2)
abline(v=550, lty=3, col = 2)
abline(v=600, lty=3, col = 2)
abline(v=650, lty=3, col = 2)
abline(v=700, lty=3, col = 2)
abline(v=750, lty=3, col = 2)
abline(v=800, lty=3, col = 2)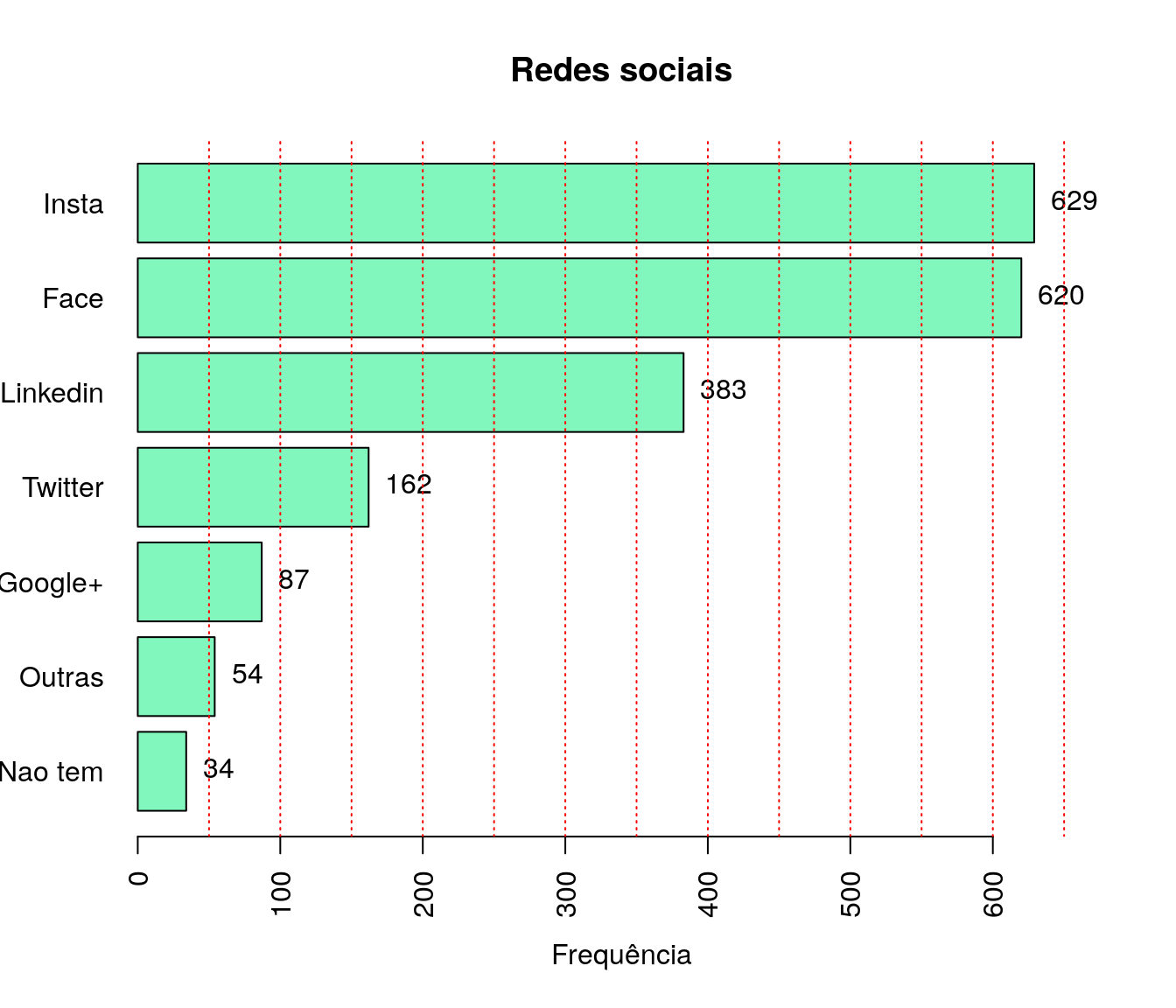
Questões extra
Quantos anos você acha que a pessoa da foto abaixo tem?

|

|

|
Geral
Tabela 1
quest$tc_idadeProf <- as.numeric(quest$tc_idadeProf)
idadeProf <- subset(quest$tc_idadeProf, quest$tc_idadeProf > 15 & quest$tc_idadeProf < 100)
h <- hist(idadeProf, plot = FALSE) #histograma
breaks <- h$breaks #armazenando os breaks do histograma
classes <- cut(idadeProf, breaks = breaks,
include.lowest = TRUE, right = TRUE) #gerando classes
tb.idade <- as.data.frame(table(classes)) #gerando tabela com faixas
tb.idade$Perc <- prop.table(tb.idade$Freq)
names(tb.idade)[1] <- "Idade"
pander:::pander(tb.idade)| Idade | Freq | Perc |
|---|---|---|
| [25,30] | 2 | 0.002663 |
| (30,35] | 15 | 0.01997 |
| (35,40] | 96 | 0.1278 |
| (40,45] | 214 | 0.285 |
| (45,50] | 221 | 0.2943 |
| (50,55] | 135 | 0.1798 |
| (55,60] | 53 | 0.07057 |
| (60,65] | 11 | 0.01465 |
| (65,70] | 4 | 0.005326 |
Tabela 2
medidas <- data.frame(minimo = quantile(idadeProf)[1],
quart1 = quantile(idadeProf)[2],
media = mean(idadeProf),
mediana = quantile(idadeProf)[3],
moda = names(sort(table(idadeProf),
decreasing = TRUE)[1]),
quart3 = quantile(idadeProf)[4],
max = quantile(idadeProf)[5])
row.names(medidas) <- NULL
pander(medidas)| minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|
| 28 | 43 | 47.66 | 48 | 45 | 52 | 70 |
disp <- data.frame(amplitude = diff(range(idadeProf)),
variancia = var(idadeProf),
desv_pad = sd(idadeProf),
coef_var = 100*sd(idadeProf)/mean(idadeProf))
pander(disp)| amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|
| 42 | 39.79 | 6.308 | 13.24 |
Gráfico 1
plot(table(idadeProf), t = "h", xlab = "Idade", ylab = "Frequência",
lwd = 6, cex.axis = 0.8, main = "Idade professor")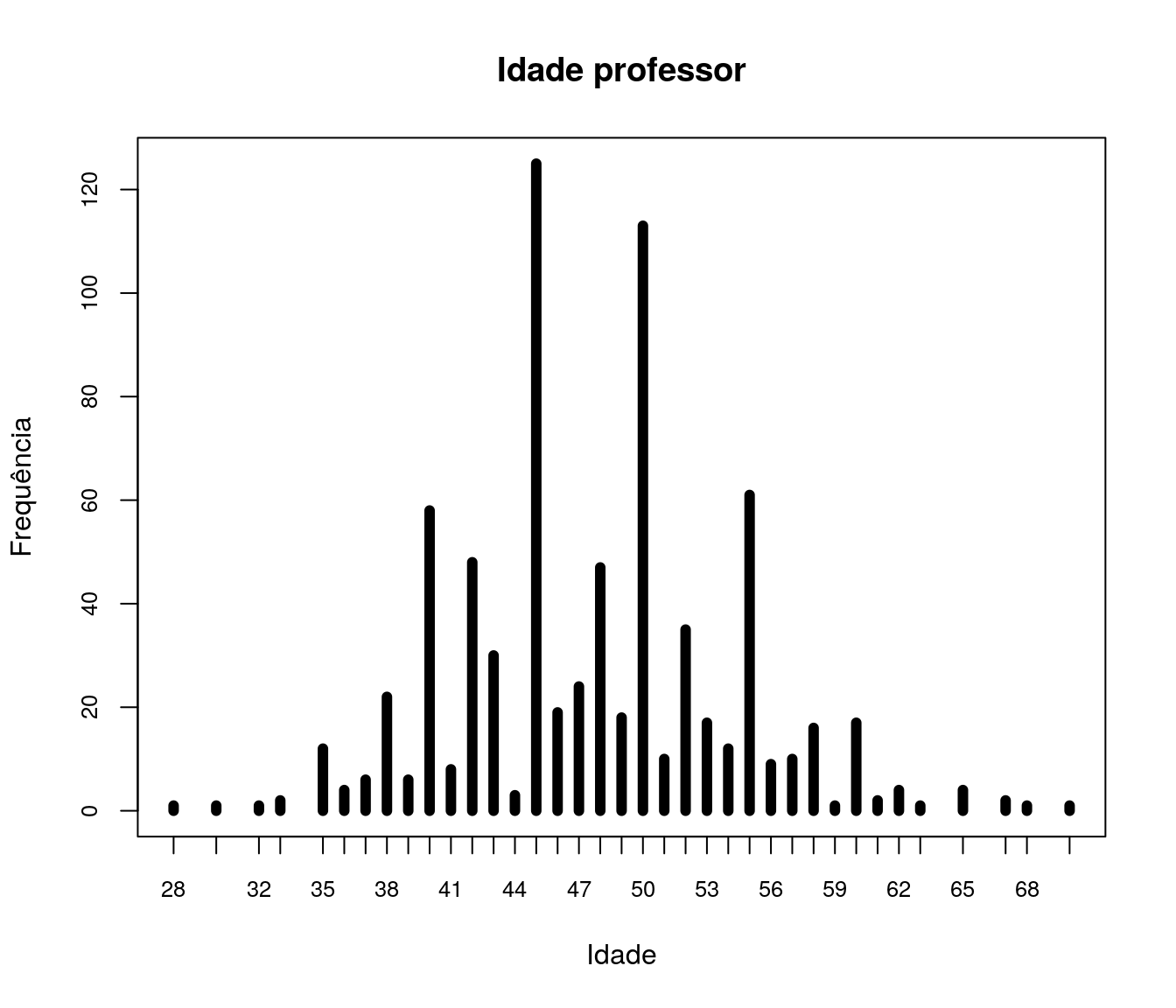
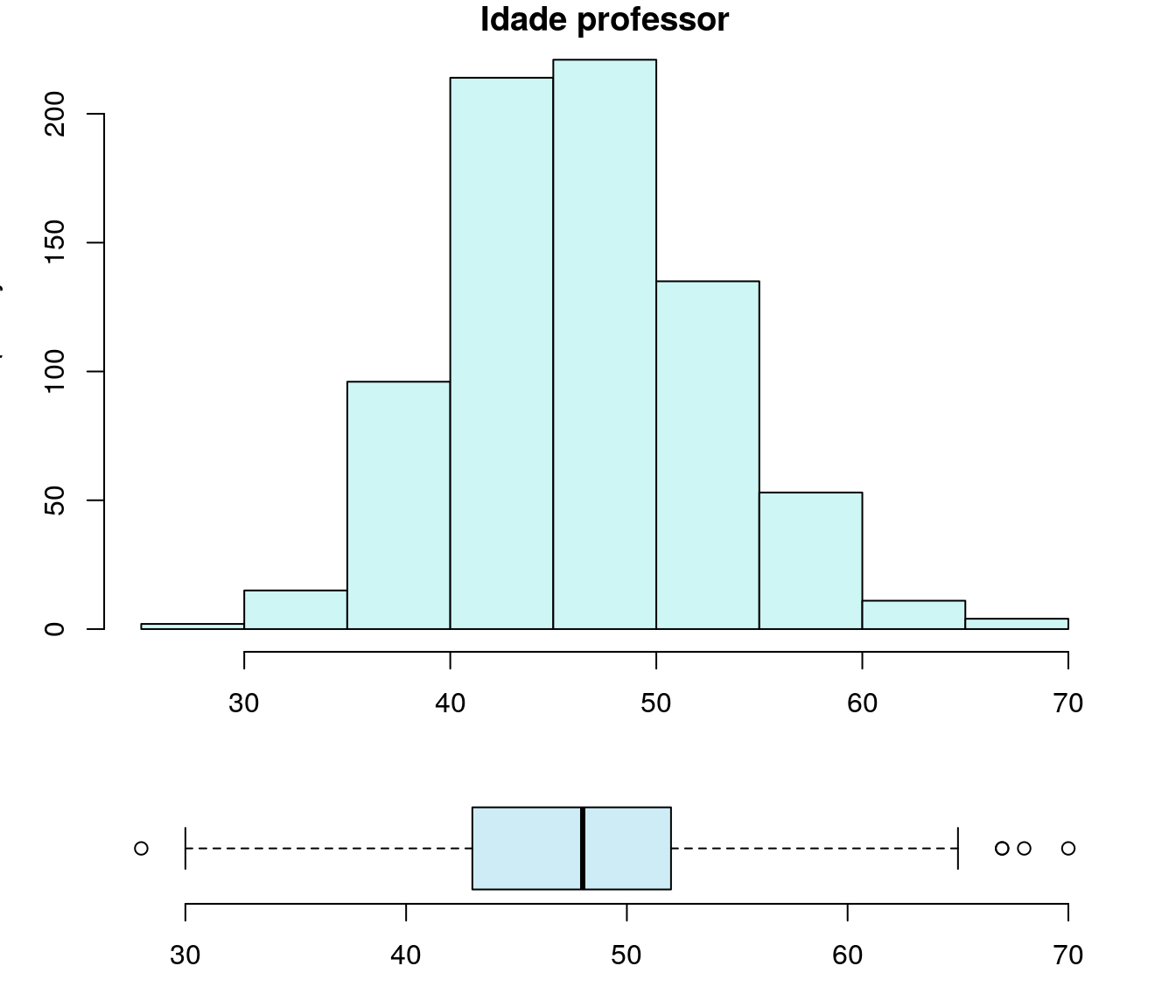
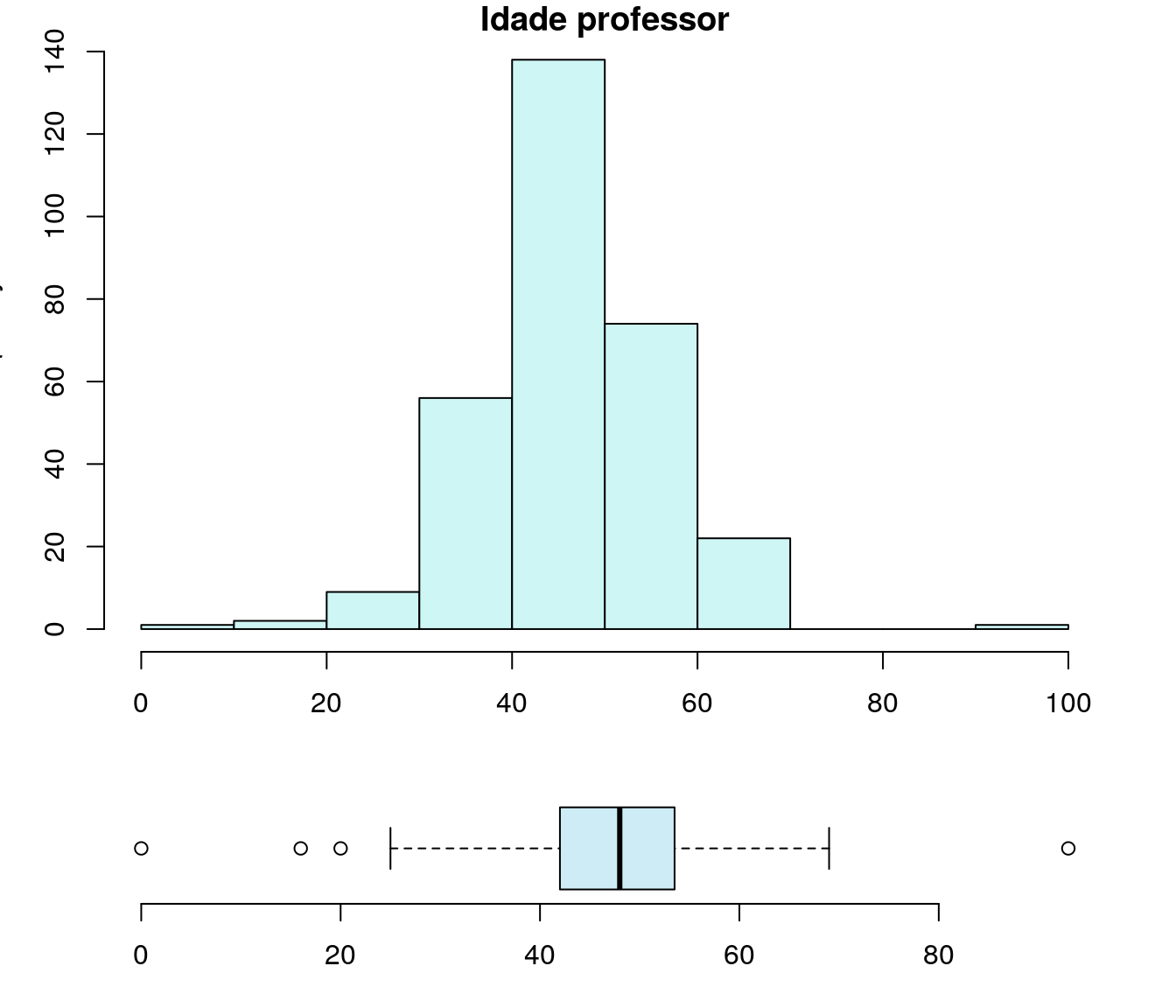
Fotos
Tabela 1
idade_prof1 <- idadeProf[c(1:174, 403:582)]
h <- hist(idade_prof1, plot = FALSE) #histograma
breaks <- h$breaks #armazenando os breaks do histograma
classes <- cut(idade_prof1, breaks = breaks,
include.lowest = TRUE, right = TRUE) #gerando classes
tb.idade1 <- as.data.frame(table(classes)) #gerando tabela com faixas
tb.idade1$Freq_rel <- round(prop.table(tb.idade1$Freq),3)
names(tb.idade1)[1] <- "Idade"
#-------------------------------------------------------
idade_prof2 <- quest$tc_idadeProf[c(175:402, 583:nrow(quest))]
idade_prof2 <- subset(idade_prof2, idade_prof2 > 15)
classes <- cut(idade_prof2, breaks = breaks,
include.lowest = TRUE, right = TRUE) #gerando classes
tb.idade2 <- as.data.frame(table(classes)) #gerando tabela com faixas
tb.idade2$Freq_rel <- round(prop.table(tb.idade2$Freq),3)
names(tb.idade2)[1] <- "Idade"|
Foto 1
|
|
Foto 2
|
Tabela 2
idade_prof11 <- quest[c(1:174, 403:582),]
idade_prof22 <- quest[c(175:402, 583:nrow(quest)),]
idade_prof22 <- subset(idade_prof22, idade_prof22$tc_idadeProf > 15)
medidas <- data.frame(foto = c('Foto 1', 'Foto 2'),
minimo = c(quantile(idade_prof11$tc_idadeProf)[1],
quantile(idade_prof22$tc_idadeProf)[1]),
quart1 = c(quantile(idade_prof11$tc_idadeProf)[2],
quantile(idade_prof22$tc_idadeProf)[2] ),
media = c(mean(idade_prof11$tc_idadeProf),
mean(idade_prof22$tc_idadeProf)),
mediana = c(quantile(idade_prof11$tc_idadeProf)[3],
quantile(idade_prof22$tc_idadeProf)[3]),
moda = c(names(sort(table(idade_prof11$tc_idadeProf),
decreasing = TRUE)[1]),
names(sort(table(idade_prof22$tc_idadeProf),
decreasing = TRUE)[1])),
quart3 = c(quantile(idade_prof11$tc_idadeProf)[4],
quantile(idade_prof22$tc_idadeProf)[4]),
max = c(quantile(idade_prof11$tc_idadeProf)[5],
quantile(idade_prof22$tc_idadeProf)[5]))
row.names(medidas) <- NULL
pander(medidas)| foto | minimo | quart1 | media | mediana | moda | quart3 | max |
|---|---|---|---|---|---|---|---|
| Foto 1 | 28 | 45 | 49.65 | 50 | 50 | 55 | 70 |
| Foto 2 | 30 | 42 | 45.89 | 45 | 45 | 50 | 67 |
#------------------------------------------------
disp <- data.frame(foto = c('Foto 1', 'Foto 2'),
amplitude = c(diff(range(idade_prof11$tc_idadeProf)),
diff(range(idade_prof22$tc_idadeProf))),
variancia = c(var(idade_prof11$tc_idadeProf),
var(idade_prof22$tc_idadeProf)),
desv_pad = c(sd(idade_prof11$tc_idadeProf),
sd(idade_prof22$tc_idadeProf)),
coef_var = c(100*sd(idade_prof11$tc_idadeProf)/mean(idade_prof11$tc_idadeProf),
100*sd(idade_prof22$tc_idadeProf)/mean(idade_prof22$tc_idadeProf)))
pander(disp)| foto | amplitude | variancia | desv_pad | coef_var |
|---|---|---|---|---|
| Foto 1 | 42 | 38.05 | 6.169 | 12.43 |
| Foto 2 | 37 | 34.77 | 5.897 | 12.85 |
Gráfico 1
par(mfrow = c(1,2))
plot(table(idade_prof1), t = "h", xlab = "Idade", ylab = "Frequência",
lwd = 6, cex.axis = 0.8, main = "Foto 1")
plot(table(idade_prof2), t = "h", xlab = "Idade", ylab = "Frequência",
lwd = 6, cex.axis = 0.8, main = "Foto 2")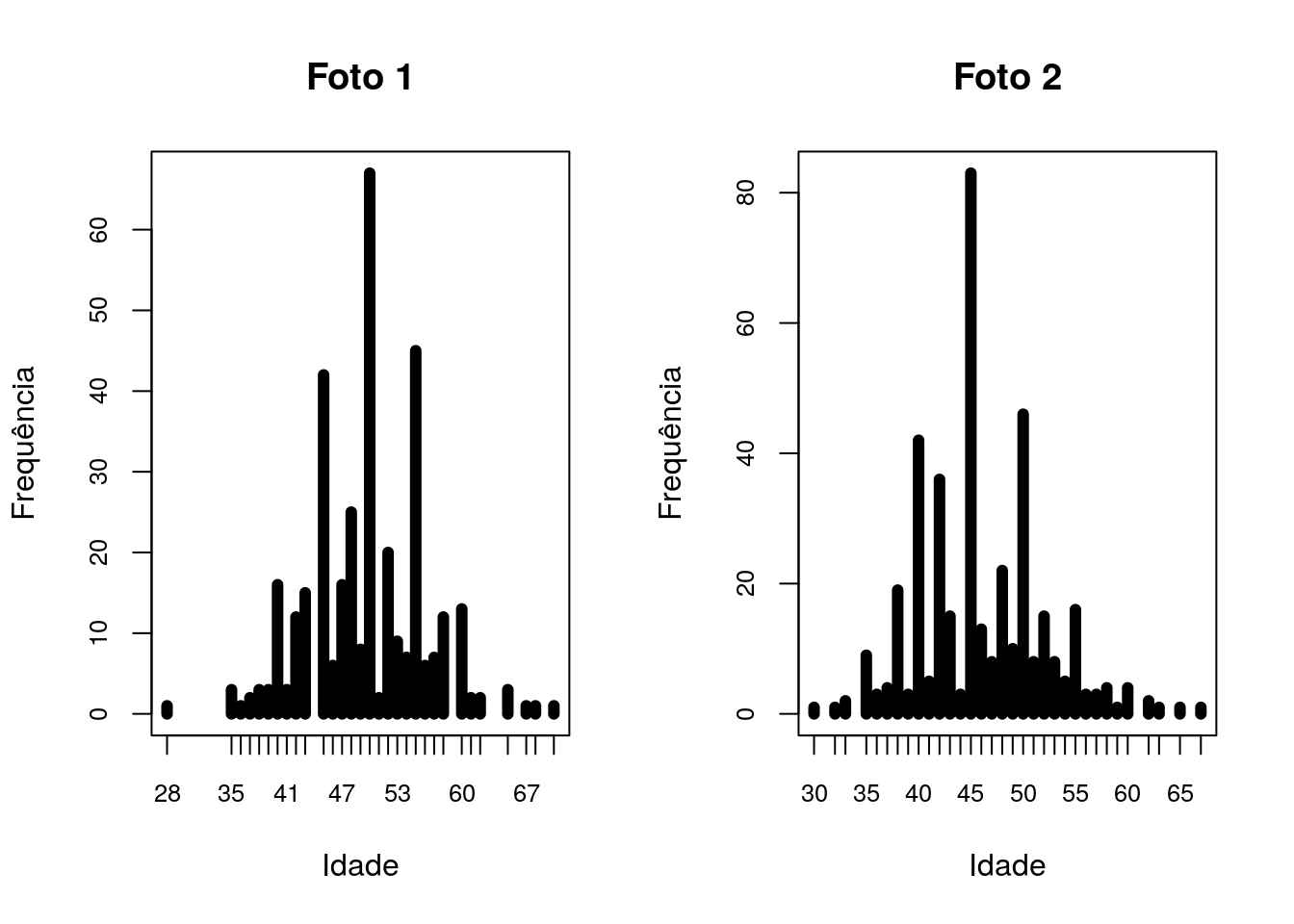
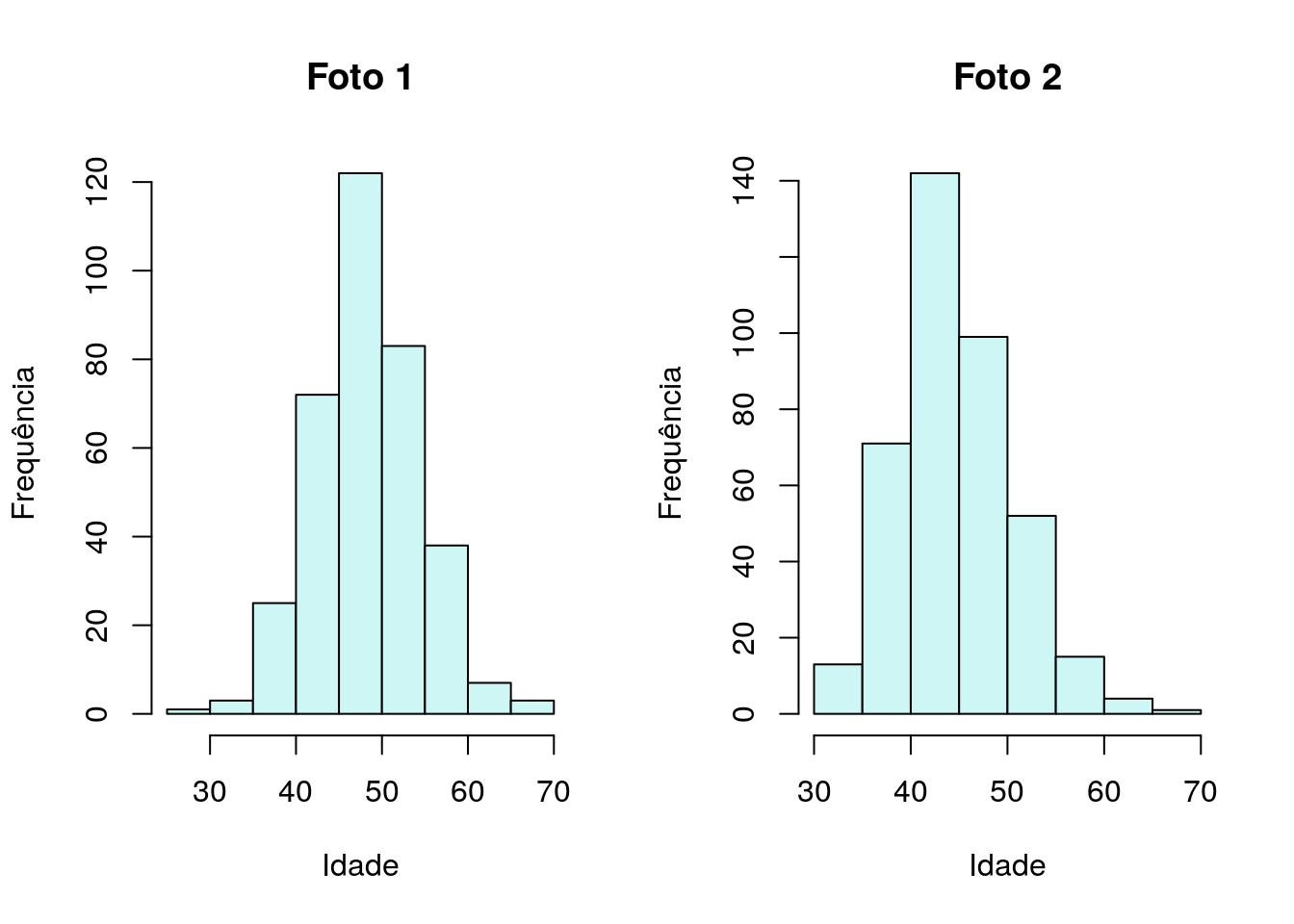
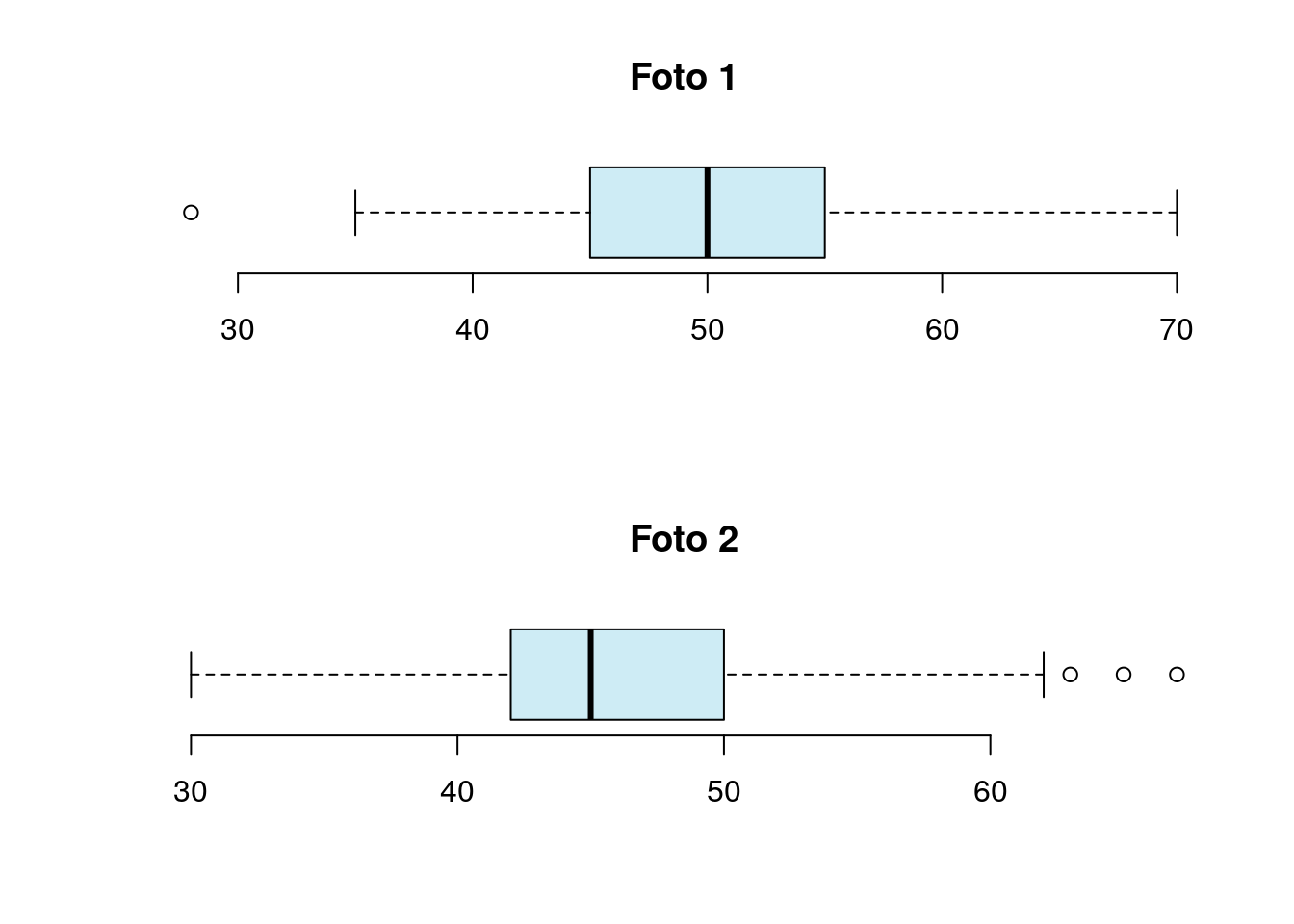
Observe as figuras abaixo. Uma delas se chama “Bouba” e a outra “Kiki”. Quem é quem?

|
Tabela
| niveis | freq | freq_r | freq_ac |
|---|---|---|---|
| Bouba/Kiki | 178 | 0.2367 | 0.2367 |
| Kiki/Bouba | 574 | 0.7633 | 1 |
Gráfico
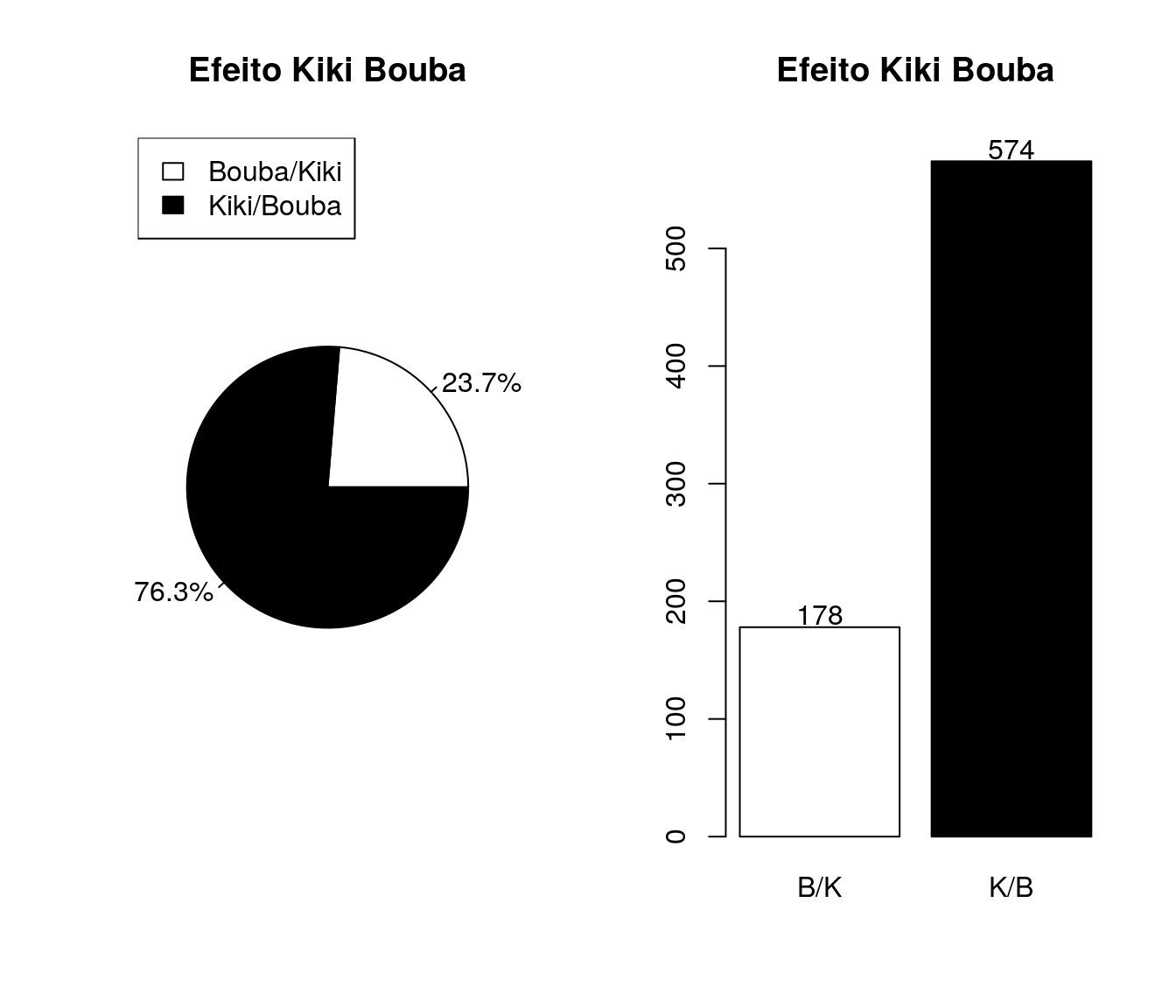
Análise bivariada
Análises bivariadas tem como objetivo buscar compreender como uma variável se comporta na presença de outra. Isto é, neste tipo de análise buscamos verificar se há relação entre duas variáveis.
Entre duas variáveis qualitativas
Sexo x Bolsa de estudo
Gráfico 1
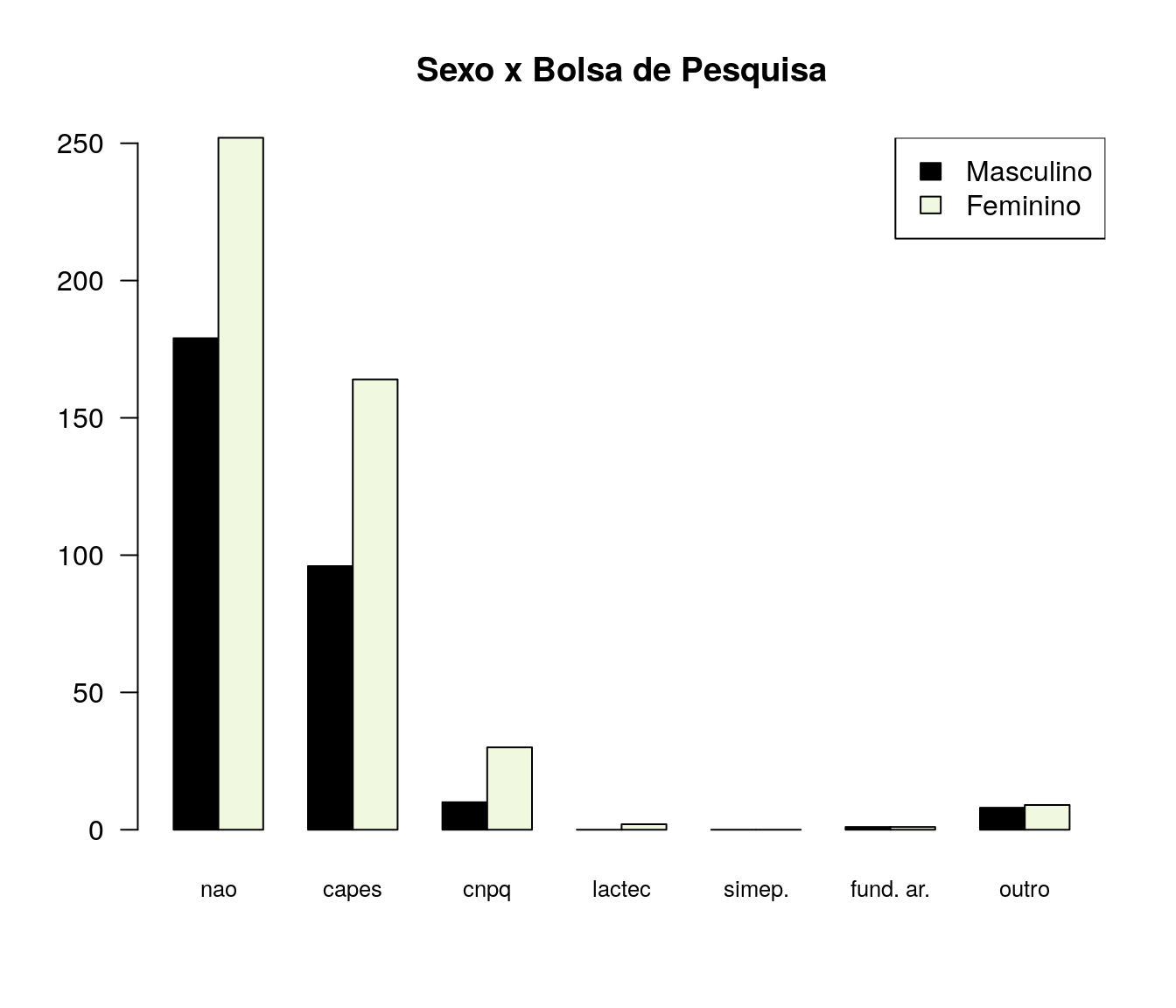
Gráfico 2
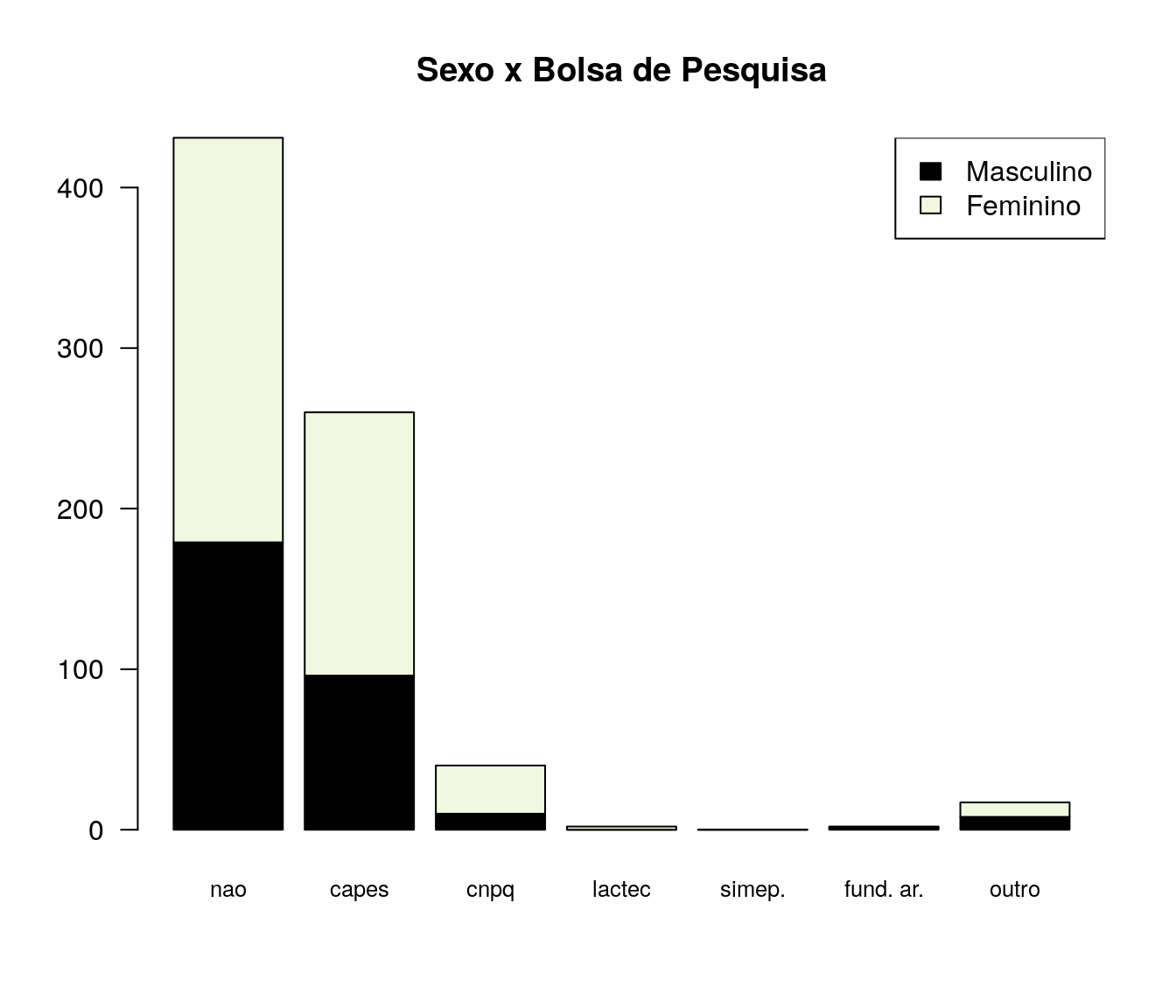
Gráfico 3
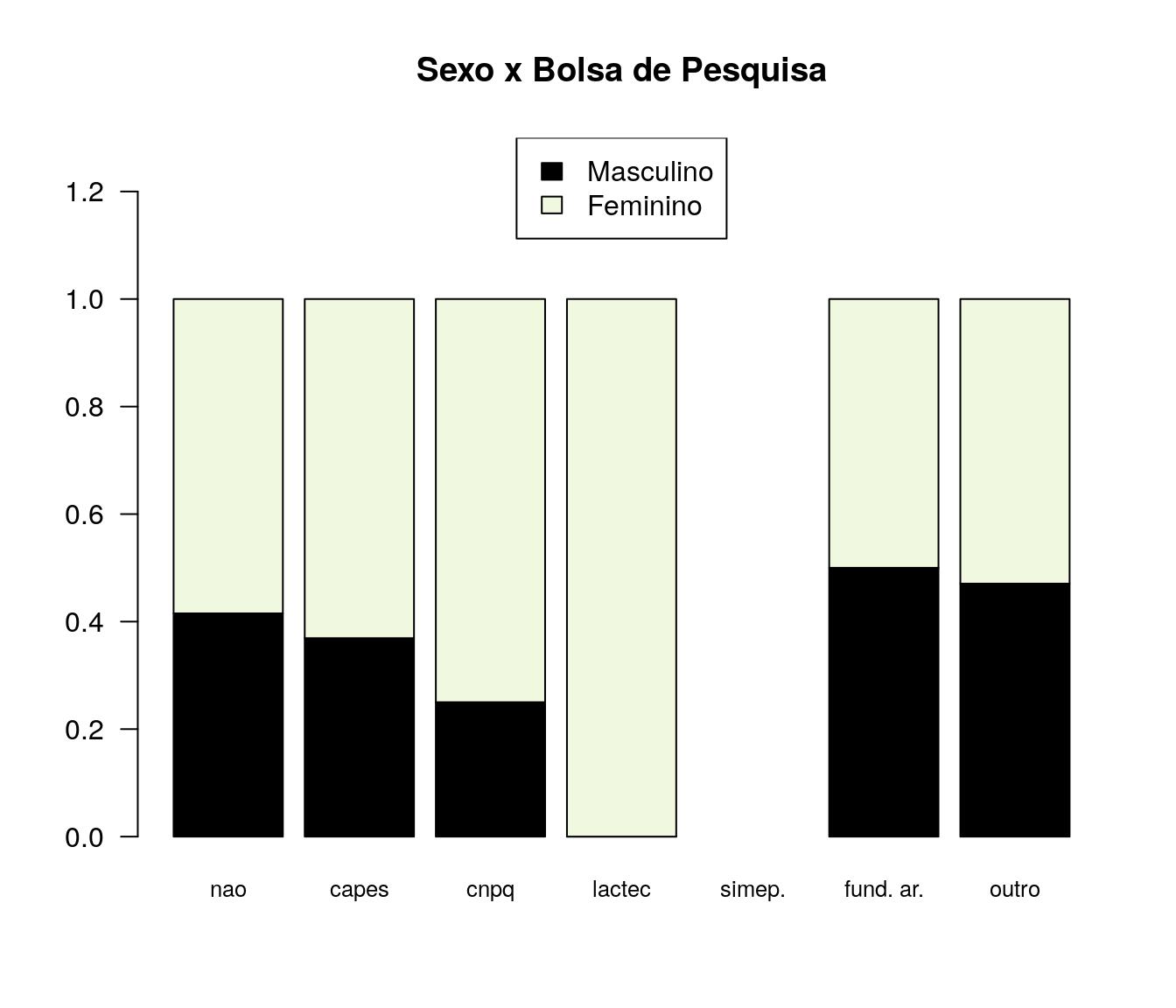
Origem x Tipo de ensino médio
Gráfico 1
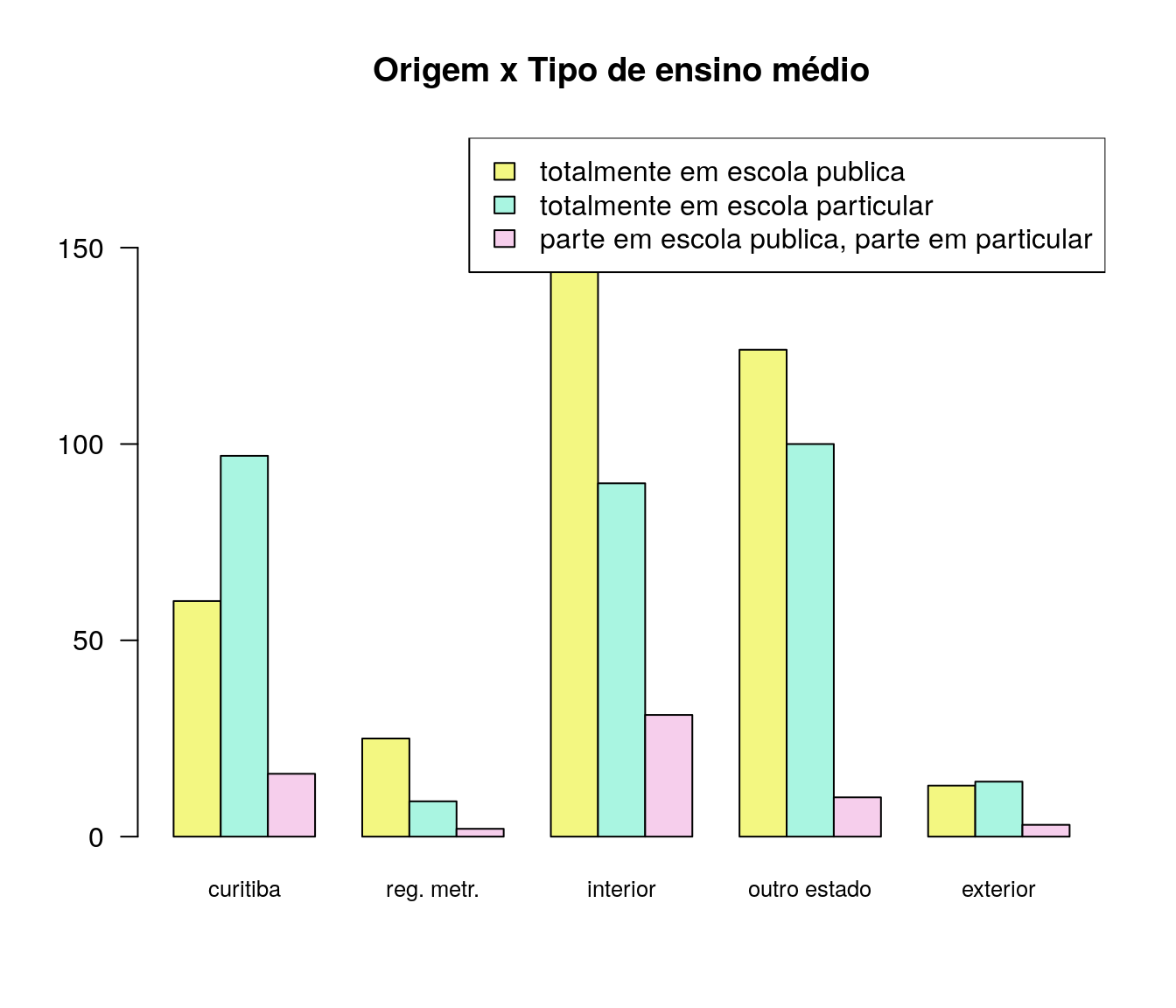
Gráfico 2
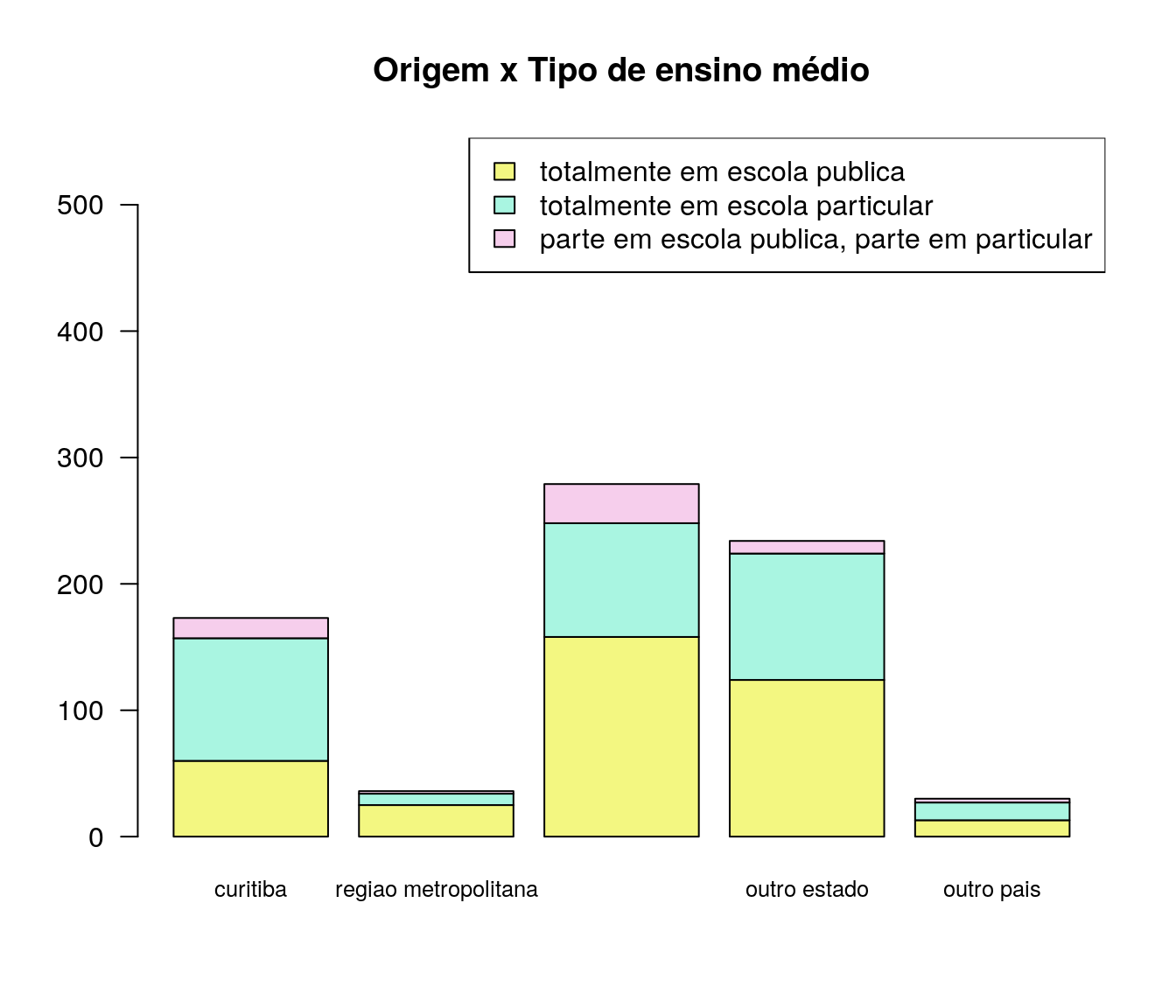
Gráfico 3
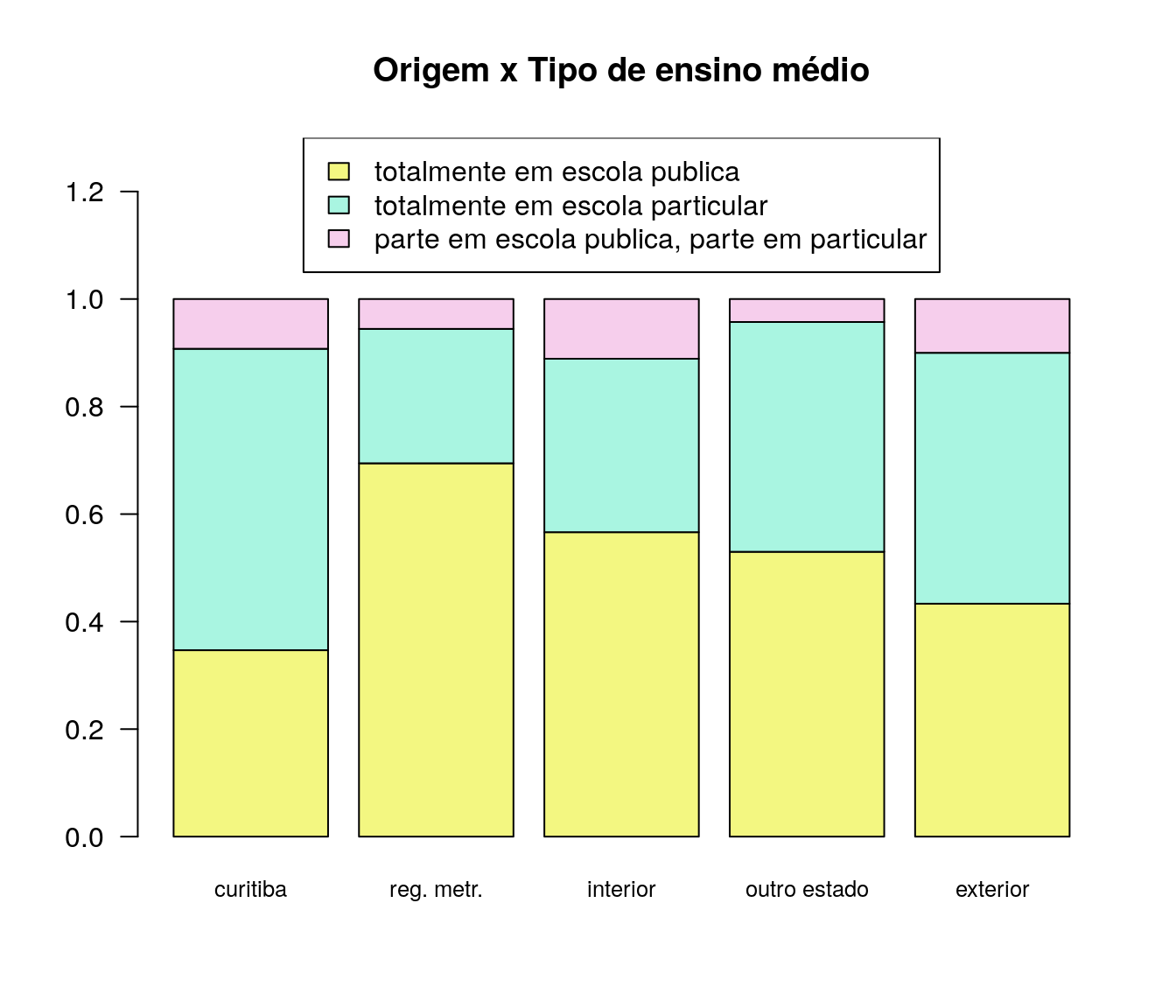
Entre uma variável qualitativa e uma quantitativa
Sexo x Numero de artigos
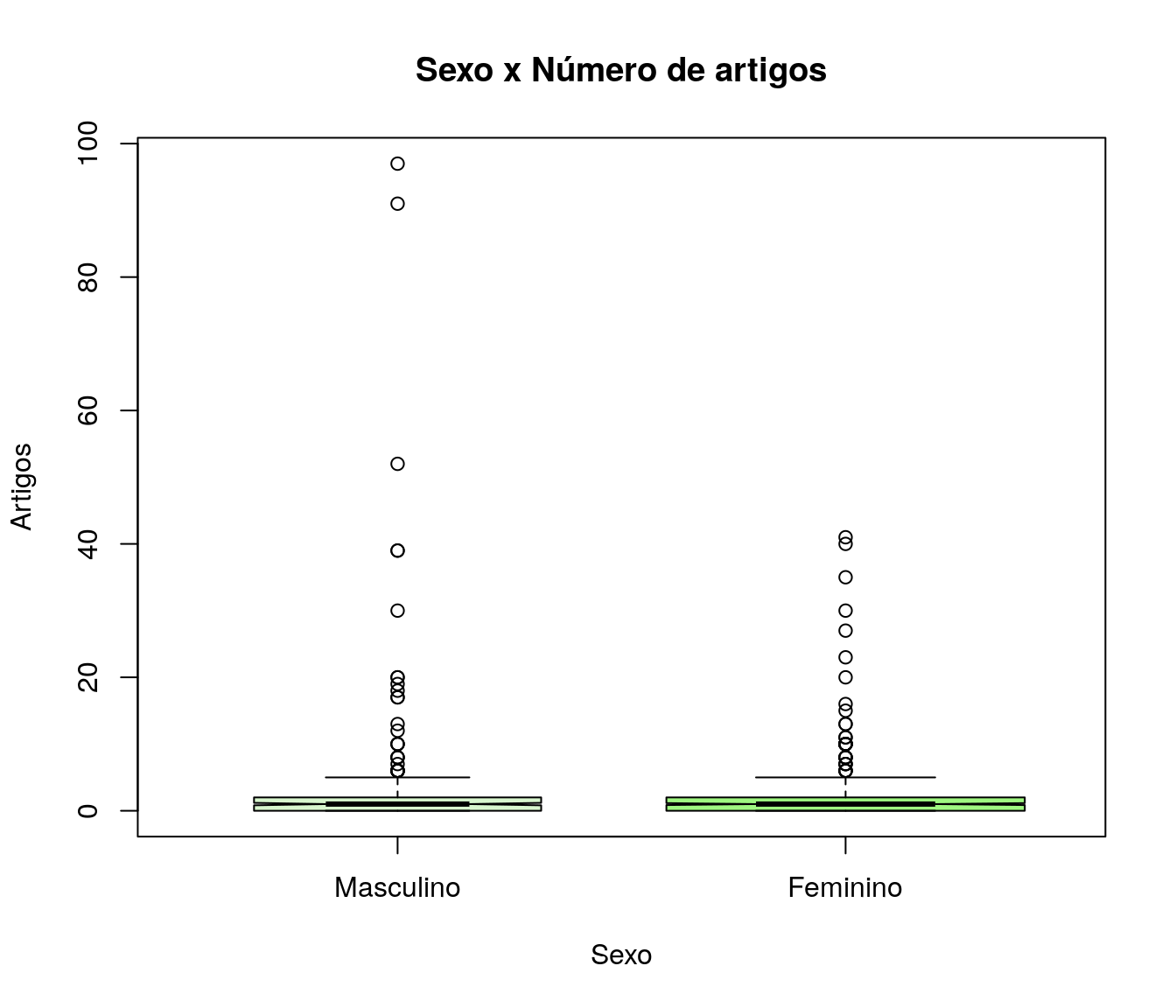
Ensino médio x Idade
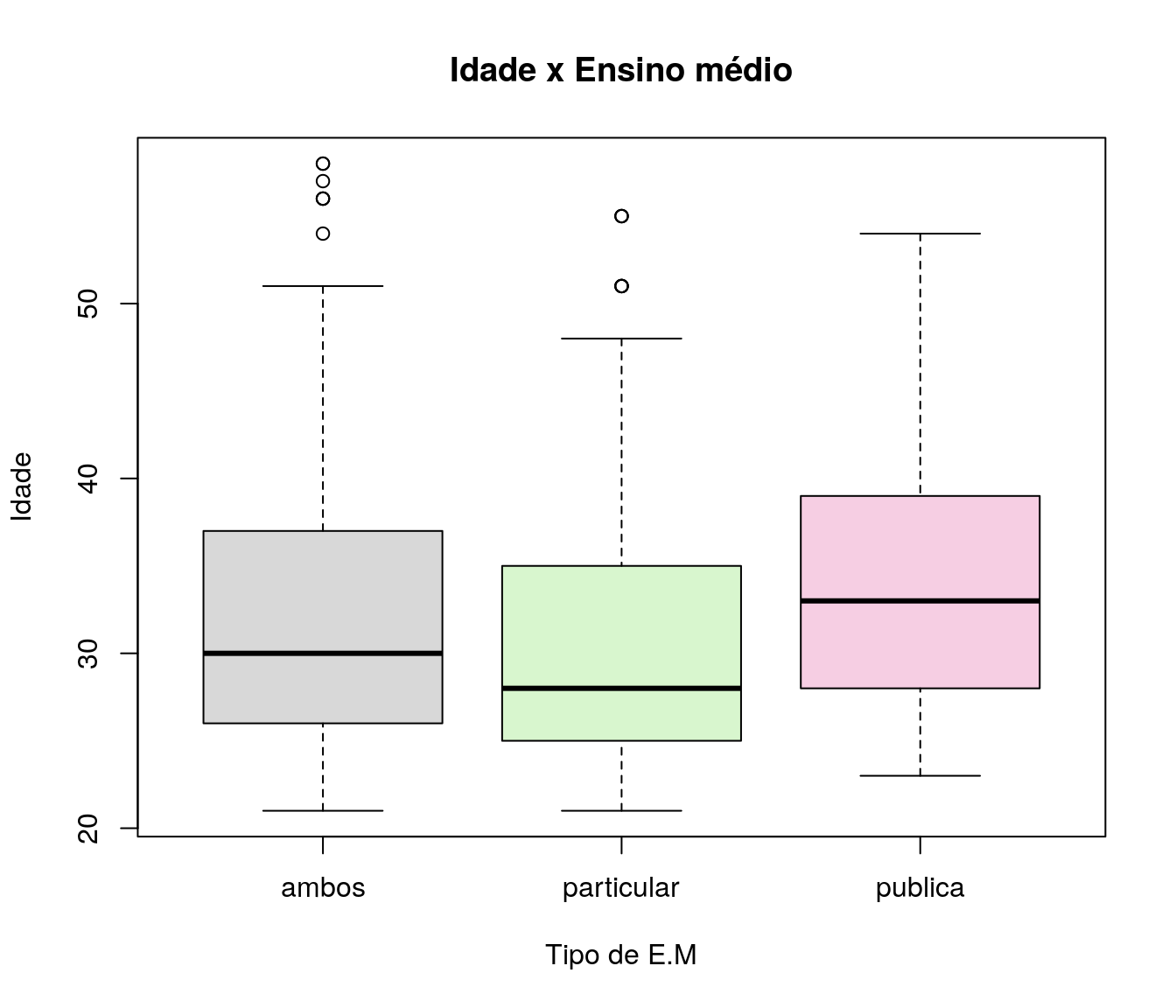
Origem x Altura
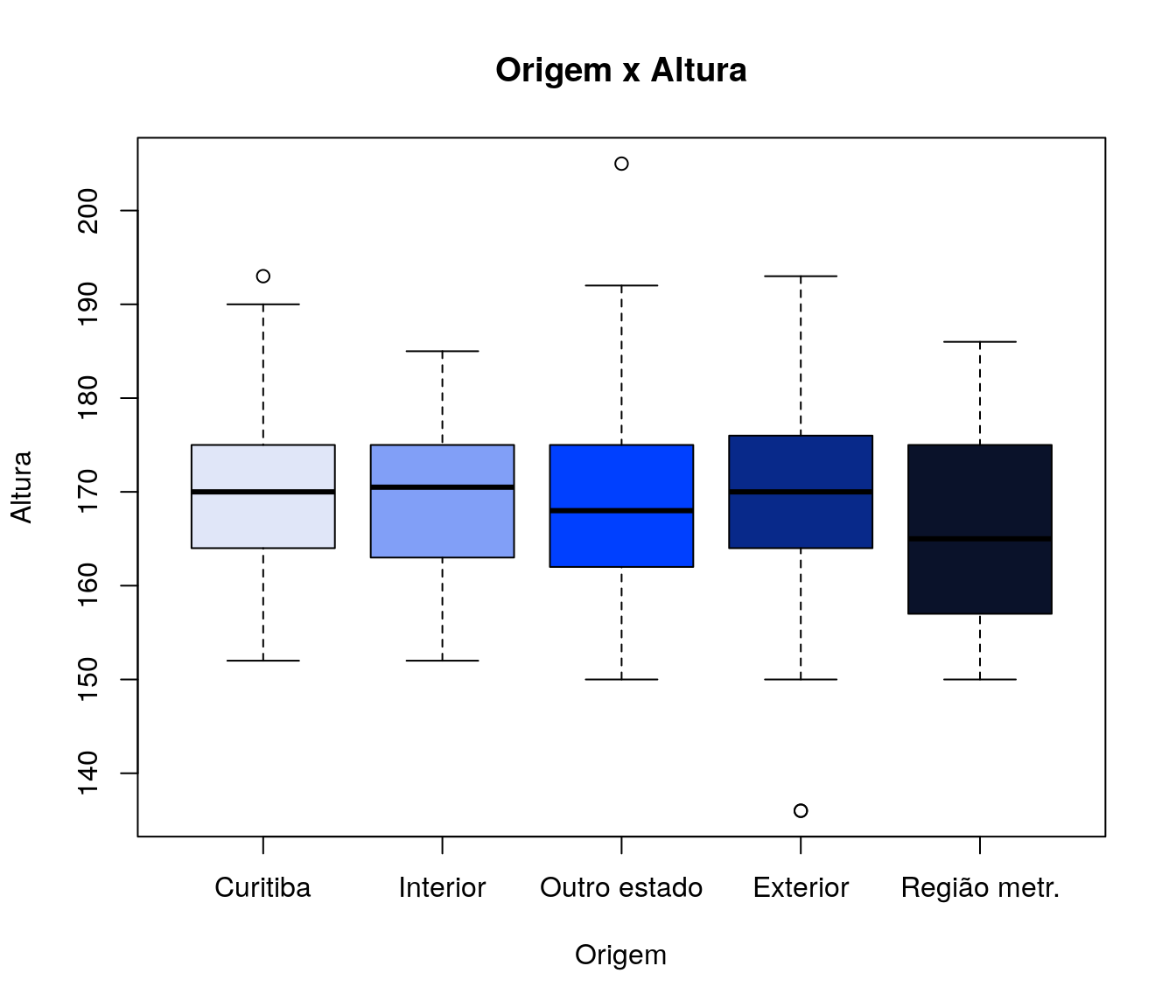
Entre duas quantitativas
Idade do professor x Idade dos alunos
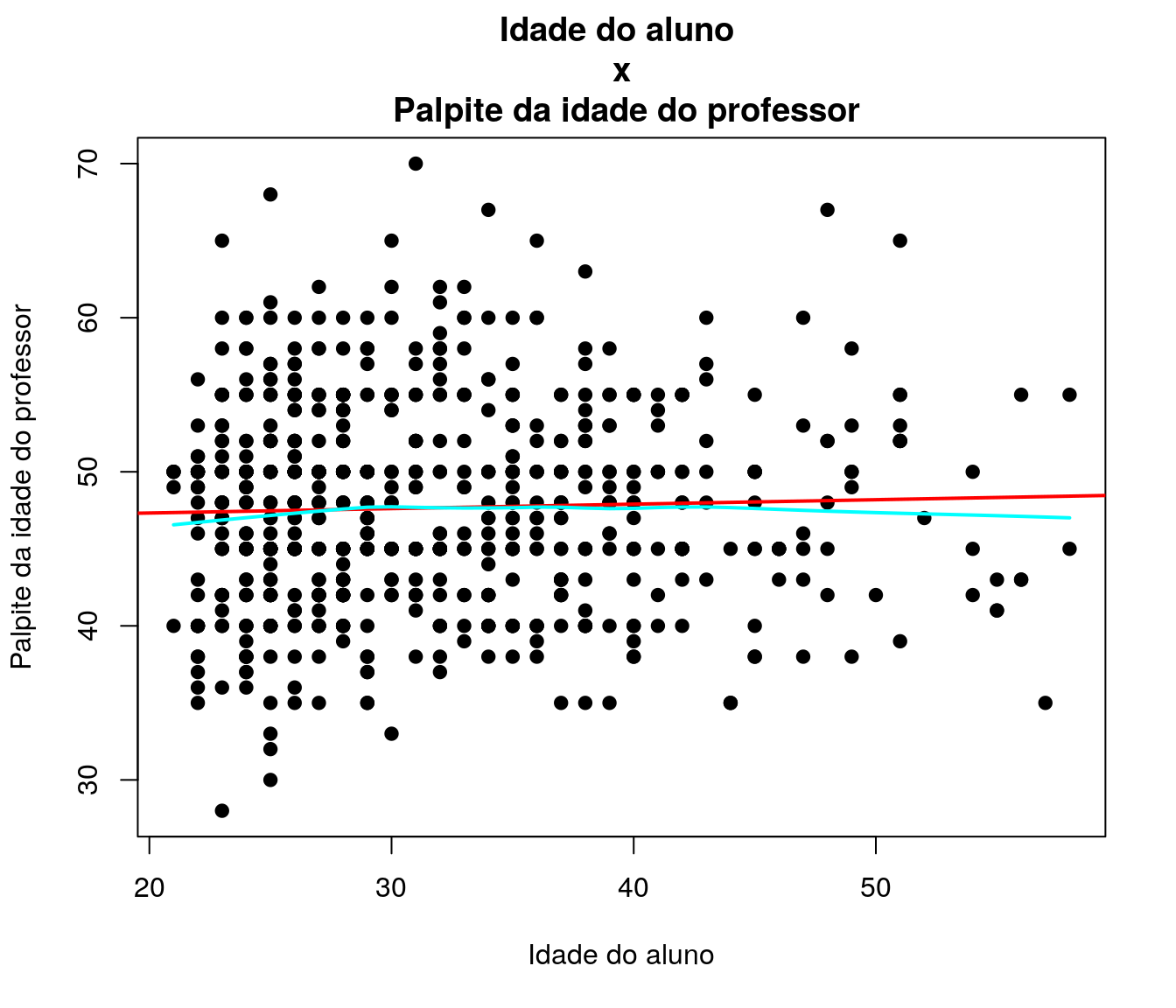
Peso x Altura
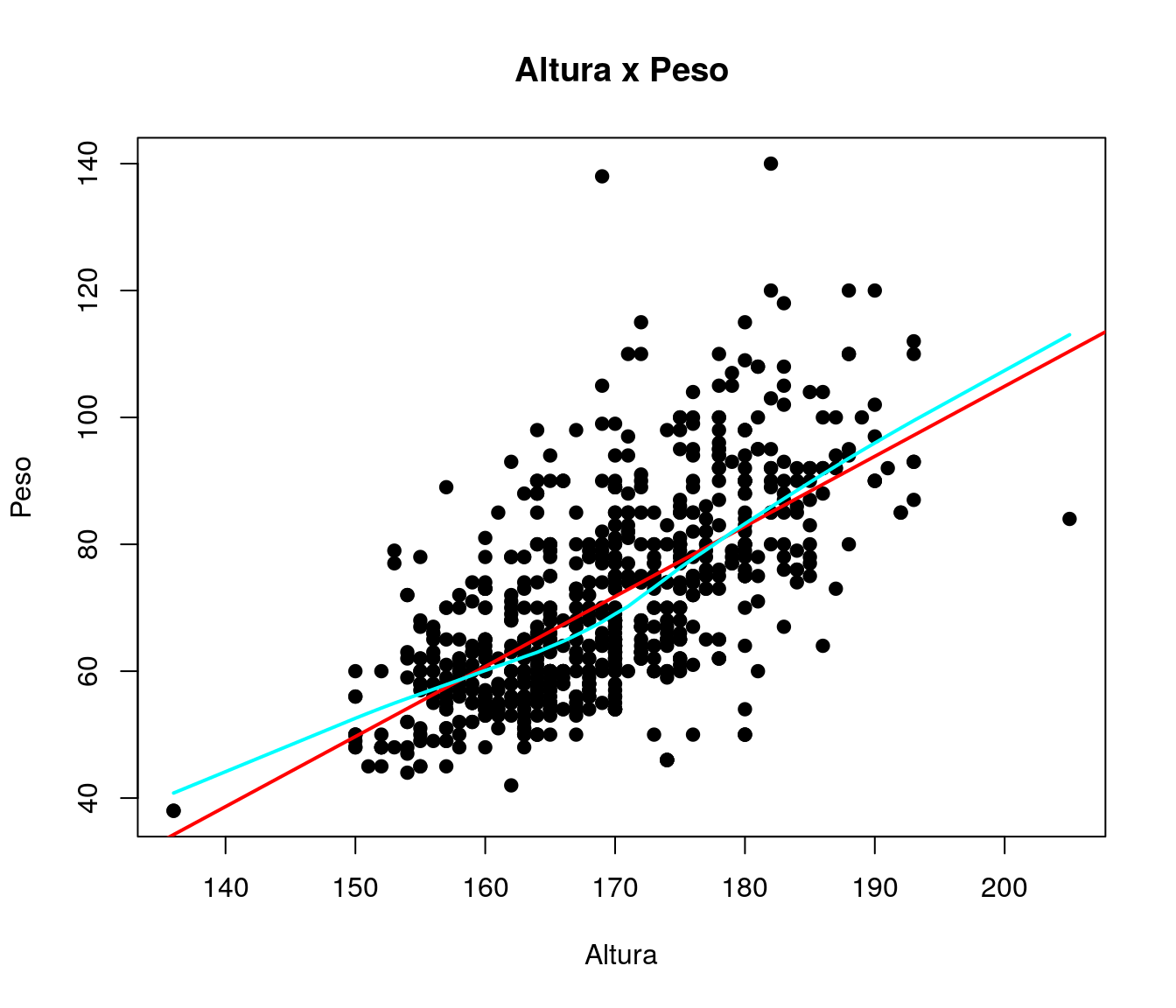
Tempo até a universidade x Uso de aplicativos de mobilidade
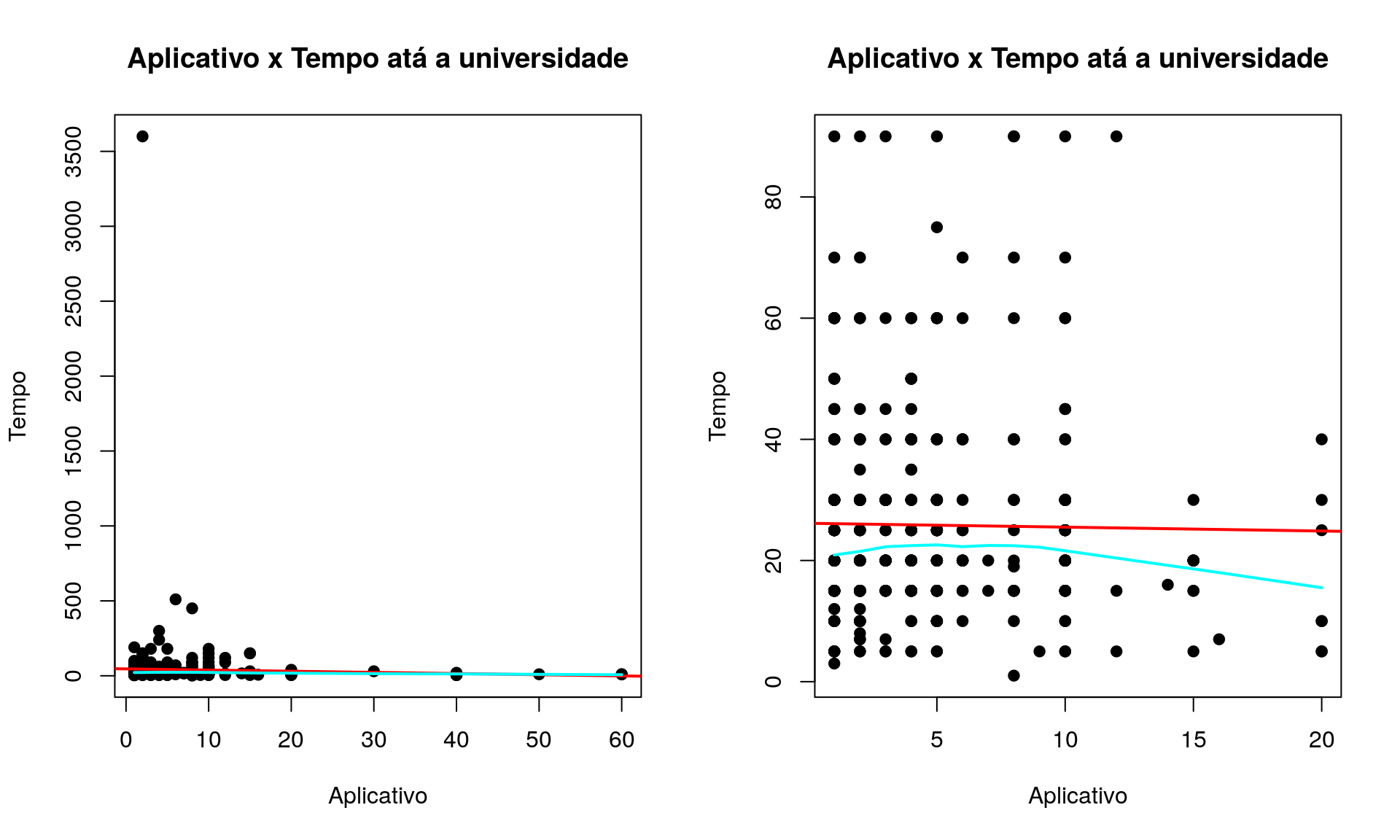
Correlação
Gráfico 1
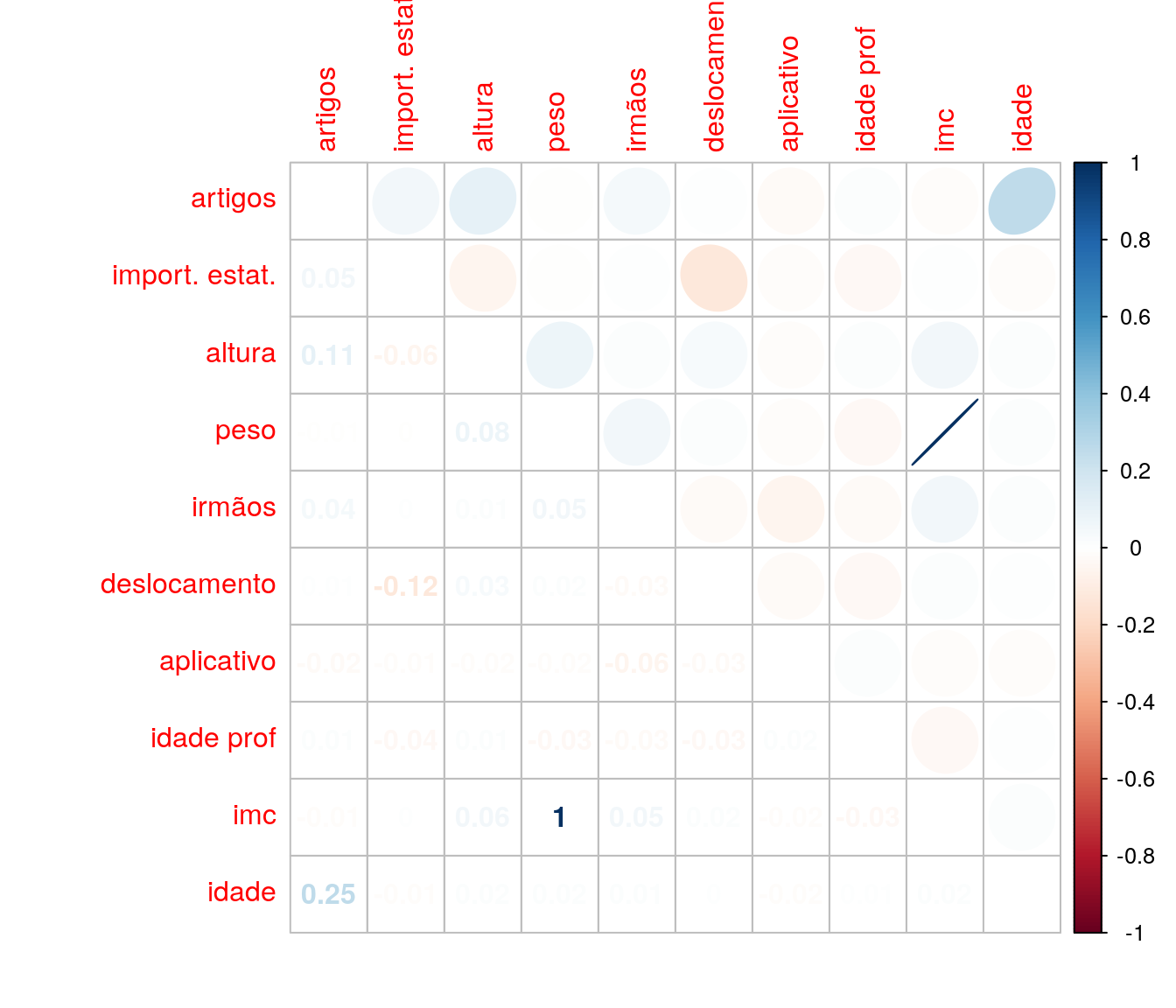

|
|

|
|
|
Gráfico 2
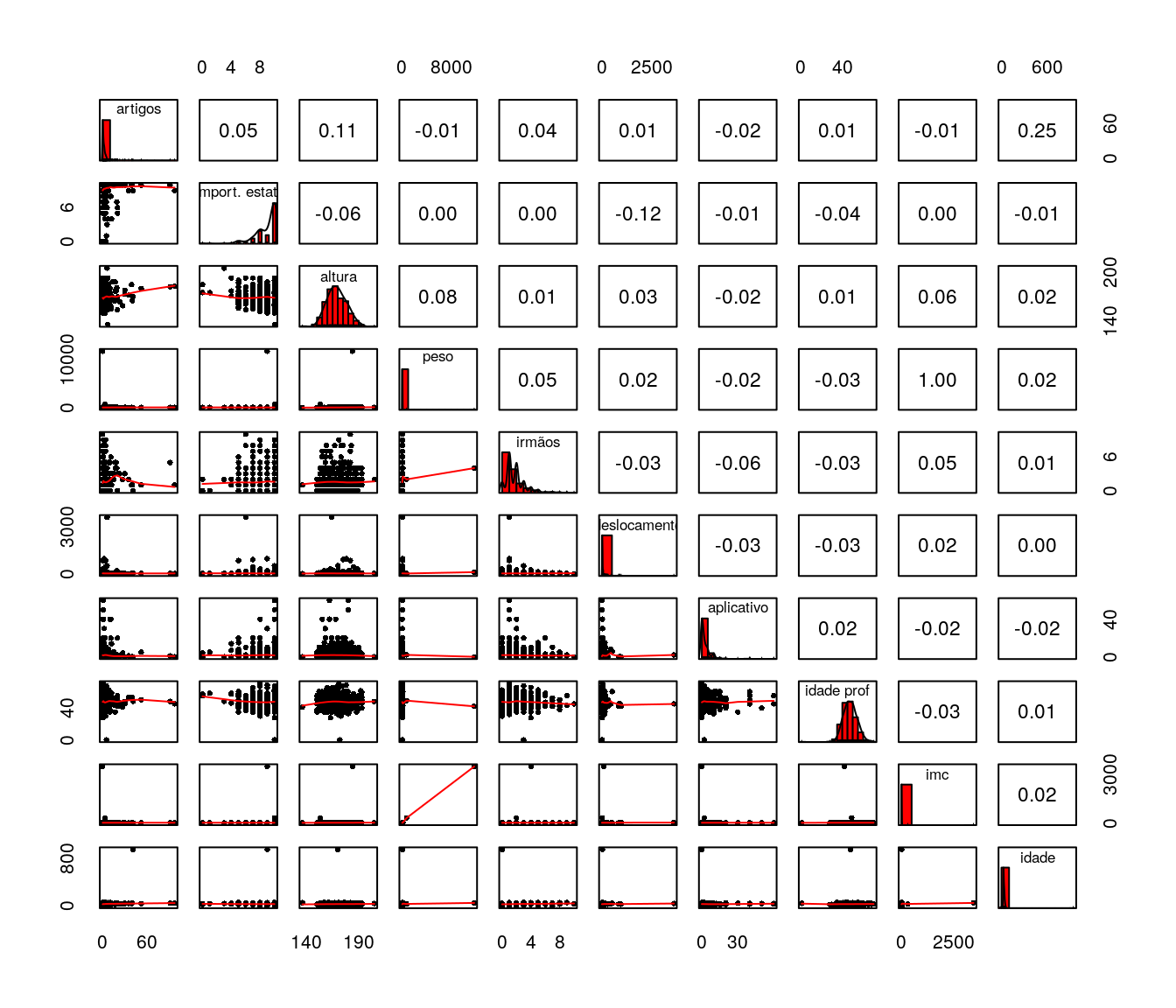
|
|
|
|
|
|